
تقنيات متقدمة لتعزيز إنتاجية LLM
نشرت: 2024-04-02في عالم التكنولوجيا سريع الخطى، أصبح نموذج اللغة الكبير (LLMs) لاعبًا رئيسيًا في كيفية تفاعلنا مع المعلومات الرقمية. يمكن لهذه الأدوات القوية كتابة المقالات، والإجابة على الأسئلة، وحتى إجراء المحادثات، ولكنها لا تخلو من التحديات. وبينما نطالب بالمزيد من هذه النماذج، فإننا نواجه عقبات، خاصة عندما يتعلق الأمر بجعلها تعمل بشكل أسرع وأكثر كفاءة. تدور هذه المدونة حول معالجة تلك العقبات بشكل مباشر.
نحن نتعمق في بعض الاستراتيجيات الذكية المصممة لتعزيز سرعة عمل هذه النماذج، دون فقدان جودة مخرجاتها. تخيل أنك تحاول تحسين سرعة سيارة السباق مع ضمان استمرار قدرتها على التنقل في المنعطفات الضيقة دون أي عيب - وهذا ما نهدف إليه من خلال النماذج اللغوية الكبيرة. سننظر في أساليب مثل الضرب المستمر، الذي يساعد على معالجة المعلومات بشكل أكثر سلاسة، والأساليب المبتكرة مثل Paged وFlash Attention، التي تجعل طلاب LLM أكثر انتباهاً وأسرع في تفكيرهم الرقمي.
لذا، إذا كنت مهتمًا بدفع حدود ما يمكن لعمالقة الذكاء الاصطناعي القيام به، فأنت في المكان الصحيح. دعونا نستكشف معًا كيف تعمل هذه التقنيات المتقدمة على تشكيل مستقبل LLMs، مما يجعلها أسرع وأفضل من أي وقت مضى.
التحديات في تحقيق إنتاجية أعلى لـ LLMs
يواجه تحقيق إنتاجية أعلى في نماذج اللغات الكبيرة (LLMs) عدة تحديات كبيرة، يعمل كل منها بمثابة عقبة أمام السرعة والكفاءة التي يمكن أن تعمل بها هذه النماذج. تتمثل إحدى العوائق الأساسية في متطلبات الذاكرة الهائلة اللازمة لمعالجة وتخزين الكميات الهائلة من البيانات التي تعمل بها هذه النماذج. مع نمو ماجستير إدارة الأعمال من حيث التعقيد والحجم، يزداد الطلب على الموارد الحسابية، مما يجعل الحفاظ على سرعات المعالجة، ناهيك عن تعزيزها، أمرًا صعبًا.
التحدي الرئيسي الآخر هو الطبيعة التراجعية التلقائية للماجستير في القانون، خاصة في النماذج المستخدمة لإنشاء النص. وهذا يعني أن الإخراج في كل خطوة يعتمد على الخطوات السابقة، مما يؤدي إلى إنشاء متطلبات معالجة تسلسلية تحد بطبيعتها من سرعة تنفيذ المهام. غالبًا ما تؤدي هذه التبعية التسلسلية إلى اختناق، حيث يجب أن تنتظر كل خطوة حتى تكتمل سابقتها قبل أن تتمكن من المتابعة، مما يعيق الجهود المبذولة لتحقيق إنتاجية أعلى.
بالإضافة إلى ذلك، يعد التوازن بين الدقة والسرعة أمرًا دقيقًا. يعد تحسين الإنتاجية دون المساس بجودة المخرجات بمثابة نزهة على حبل مشدود، ويتطلب حلولًا مبتكرة يمكنها التنقل في المشهد المعقد للكفاءة الحسابية وفعالية النموذج.
تشكل هذه التحديات الخلفية التي يتم على أساسها تحقيق التقدم في تحسين LLM، مما يدفع حدود ما هو ممكن في مجال معالجة اللغة الطبيعية وخارجها.
متطلبات الذاكرة
تولد مرحلة فك التشفير رمزًا مميزًا واحدًا في كل خطوة زمنية، ولكن كل رمز يعتمد على موتر المفتاح والقيمة لجميع الرموز المميزة السابقة (بما في ذلك موترات KV الخاصة برموز الإدخال المحسوبة عند التعبئة المسبقة، وأي موترات KV جديدة محسوبة حتى الخطوة الزمنية الحالية) .
لذلك، لتقليل الحسابات الزائدة في كل مرة ولتجنب إعادة حساب كل هذه الموترات لجميع الرموز المميزة في كل خطوة زمنية، فمن الممكن تخزينها مؤقتًا في ذاكرة وحدة معالجة الرسومات. في كل تكرار، عندما يتم حساب عناصر جديدة، تتم إضافتها ببساطة إلى ذاكرة التخزين المؤقت قيد التشغيل لاستخدامها في التكرار التالي. يُعرف هذا بشكل أساسي باسم ذاكرة التخزين المؤقت KV.
يؤدي هذا إلى تقليل العمليات الحسابية المطلوبة بشكل كبير ولكنه يقدم متطلبات ذاكرة إلى جانب متطلبات ذاكرة أعلى بالفعل لنماذج اللغات الكبيرة مما يجعل من الصعب تشغيلها على وحدات معالجة الرسومات السلعية. مع زيادة حجم معلمات النموذج (7B إلى 33B) والدقة الأعلى (fp16 إلى fp32)، تزداد أيضًا متطلبات الذاكرة. دعونا نرى مثالا لسعة الذاكرة المطلوبة،
كما نعلم فإن شاغلي الذاكرة الرئيسيين هما
- أوزان النموذج الخاصة في الذاكرة، وهذا يأتي مع عدم وجود. من المعلمات مثل 7B ونوع البيانات لكل معلمة، على سبيل المثال، 7B في fp16(2 بايت) ~= 14 جيجابايت في الذاكرة
- ذاكرة التخزين المؤقت KV: ذاكرة التخزين المؤقت المستخدمة للقيمة الأساسية لمرحلة الاهتمام الذاتي لتجنب الحسابات الزائدة عن الحاجة.
حجم ذاكرة التخزين المؤقت KV لكل رمز بالبايت = 2 * (num_layers) * (hidden_size) * الدقة_in_bytes
العامل الأول 2 يمثل مصفوفات K وV. يمكن الحصول على الحجم المخفي والرأس الخافت من بطاقة النموذج أو ملف التكوين.
الصيغة أعلاه مخصصة لكل رمز مميز، لذلك بالنسبة لتسلسل الإدخال، ستكون seq_len * size_of_kv_per_token. وبالتالي فإن الصيغة أعلاه سوف تتحول إلى،
الحجم الإجمالي لذاكرة التخزين المؤقت KV بالبايت = (sequence_length) * 2 * (num_layers) * (hidden_size) * الدقة_in_bytes
على سبيل المثال، مع LLAMA 2 في fp16، سيكون الحجم (4096) * 2 * (32) * (4096) * 2، وهو ما يعادل 2 جيجابايت تقريبًا.
هذا أعلاه مخصص لإدخال واحد، مع إدخالات متعددة وهذا ينمو بسرعة، وبالتالي يصبح تخصيص الذاكرة وإدارتها أثناء الطيران خطوة حاسمة لتحقيق الأداء الأمثل، إن لم يكن يؤدي إلى نفاد الذاكرة ومشكلات التجزئة.
في بعض الأحيان، تكون متطلبات الذاكرة أكثر من سعة وحدة معالجة الرسومات الخاصة بنا، وفي هذه الحالات، نحتاج إلى النظر في توازي النموذج، وتوازي الموتر الذي لم يتم تناوله هنا ولكن يمكنك استكشافه في هذا الاتجاه.
الانحدار التلقائي وعملية مرتبطة بالذاكرة
كما نرى، فإن جزء توليد المخرجات في نماذج اللغات الكبيرة هو ذو طبيعة انحدارية تلقائية. يشير إلى إنشاء أي رمز مميز جديد، ويعتمد ذلك على جميع الرموز المميزة السابقة وحالاتها الوسيطة. نظرًا لأنه في مرحلة الإخراج لا تتوفر جميع الرموز المميزة لإجراء المزيد من الحسابات، ولديها ناقل واحد فقط (للرمز المميز التالي) وكتلة المرحلة السابقة، يصبح هذا مثل عملية ناقل المصفوفة التي تستخدم بشكل أقل قدرة حساب GPU عندما مقارنة بمرحلة التعبئة المسبقة. إن السرعة التي يتم بها نقل البيانات (الأوزان والمفاتيح والقيم وعمليات التنشيط) إلى وحدة معالجة الرسومات من الذاكرة تهيمن على زمن الوصول، وليس مدى سرعة حدوث العمليات الحسابية فعليًا. وبعبارة أخرى، هذه عملية مرتبطة بالذاكرة .
حلول مبتكرة للتغلب على تحديات الإنتاجية
الخلط المستمر
تتمثل الخطوة البسيطة جدًا لتقليل طبيعة مرحلة فك التشفير المرتبطة بالذاكرة في تجميع الإدخال وإجراء العمليات الحسابية لمدخلات متعددة في وقت واحد. لكن التجميع المستمر البسيط أدى إلى ضعف الأداء بسبب طبيعة أطوال التسلسل المتغيرة التي يتم إنشاؤها وهنا يعتمد زمن الوصول للدفعة على أطول تسلسل يتم إنشاؤه في الدفعة وأيضًا مع متطلبات الذاكرة المتزايدة نظرًا لأن المدخلات المتعددة تتم معالجتها الآن مرة واحدة.

ولذلك، فإن الخلط الثابت البسيط غير فعال، ويأتي الخلط المستمر. ويكمن جوهرها في تجميع دفعات الطلبات الواردة ديناميكيًا، والتكيف مع معدلات الوصول المتقلبة، واستغلال فرص المعالجة المتوازية كلما أمكن ذلك. يعمل هذا أيضًا على تحسين استخدام الذاكرة من خلال تجميع التسلسلات ذات الأطوال المتشابهة معًا في كل دفعة مما يقلل من مقدار الحشو المطلوب للتسلسلات الأقصر ويتجنب إهدار الموارد الحسابية على الحشو الزائد.
يقوم بضبط حجم الدفعة بشكل تكيفي بناءً على عوامل مثل سعة الذاكرة الحالية والموارد الحسابية وأطوال تسلسل الإدخال. وهذا يضمن أن النموذج يعمل على النحو الأمثل في ظل ظروف مختلفة دون تجاوز قيود الذاكرة. يساعد هذا في المساعدة على الاهتمام بالصفحات (الموضح أدناه) في تقليل زمن الوصول وزيادة الإنتاجية.
اقرأ المزيد: كيف يتيح التجميع المستمر إنتاجية تبلغ 23x في استدلال LLM مع تقليل زمن الوصول p50
اهتمام الصفحات
نظرًا لأننا نقوم بالتجميع لتحسين الإنتاجية، فإن ذلك يأتي أيضًا على حساب زيادة متطلبات ذاكرة التخزين المؤقت KV، نظرًا لأننا نقوم الآن بمعالجة مدخلات متعددة في وقت واحد. يمكن أن تتجاوز هذه التسلسلات سعة الذاكرة للموارد الحسابية المتاحة، مما يجعل معالجتها بأكملها غير عملية.
ويلاحظ أيضًا أن التخصيص الساذج للذاكرة لذاكرة التخزين المؤقت KV يؤدي إلى الكثير من تجزئة الذاكرة تمامًا كما نلاحظ في أنظمة الكمبيوتر بسبب التخصيص غير المتكافئ للذاكرة. قدم vLLM Paged Attention وهي تقنية لإدارة الذاكرة مستوحاة من مفاهيم نظام التشغيل الخاصة بالترحيل والذاكرة الافتراضية للتعامل بكفاءة مع المتطلبات المتزايدة لذاكرة التخزين المؤقت KV.
يعالج "الانتباه المقسم إلى صفحات" قيود الذاكرة عن طريق تقسيم آلية الانتباه إلى صفحات أو أجزاء أصغر، يغطي كل منها مجموعة فرعية من تسلسل الإدخال. بدلاً من حساب درجات الاهتمام لتسلسل الإدخال بأكمله مرة واحدة، يركز النموذج على صفحة واحدة في كل مرة، ويعالجها بالتسلسل.
أثناء الاستدلال أو التدريب، يتكرر النموذج خلال كل صفحة من تسلسل الإدخال، ويحسب درجات الاهتمام ويولد المخرجات وفقًا لذلك. بمجرد معالجة الصفحة، يتم تخزين نتائجها، وينتقل النموذج إلى الصفحة التالية.
من خلال تقسيم آلية الانتباه إلى صفحات، يتيح Paged Attention لنموذج اللغة الكبير التعامل مع تسلسلات الإدخال ذات الطول التعسفي دون تجاوز قيود الذاكرة. فهو يقلل بشكل فعال من مساحة الذاكرة المطلوبة لمعالجة التسلسلات الطويلة، مما يجعل من الممكن العمل مع المستندات والدفعات الكبيرة.
اقرأ المزيد: خدمة LLM السريعة مع vLLM وPagedAttention
اهتمام فلاش
نظرًا لأن آلية الانتباه ضرورية لنماذج المحولات التي تعتمد عليها نماذج اللغة الكبيرة، فإنها تساعد النموذج على التركيز على الأجزاء ذات الصلة من نص الإدخال عند إجراء التنبؤات. ومع ذلك، عندما تصبح النماذج المعتمدة على المحولات أكبر وأكثر تعقيدًا، تصبح آلية الاهتمام الذاتي بطيئة بشكل متزايد وتستهلك الكثير من الذاكرة، مما يؤدي إلى مشكلة عنق الزجاجة في الذاكرة كما ذكرنا سابقًا. Flash Attention هو أسلوب تحسين آخر يهدف إلى تخفيف هذه المشكلة عن طريق تحسين عمليات الانتباه، مما يسمح بالتدريب والاستدلال بشكل أسرع.
الميزات الرئيسية لبرنامج Flash Attention:
Kernel Fusion: من المهم ليس فقط زيادة استخدام حوسبة وحدة معالجة الرسومات إلى الحد الأقصى، ولكن أيضًا جعلها تؤدي عمليات فعالة قدر الإمكان. يجمع Flash Attention بين خطوات حسابية متعددة في عملية واحدة، مما يقلل الحاجة إلى عمليات نقل البيانات المتكررة. يعمل هذا النهج المبسط على تبسيط عملية التنفيذ وتعزيز الكفاءة الحسابية.
التجانب: يقوم برنامج Flash Attention بتقسيم البيانات المحملة إلى كتل أصغر، مما يساعد على المعالجة المتوازية. تعمل هذه الإستراتيجية على تحسين استخدام الذاكرة، مما يتيح حلولاً قابلة للتطوير للنماذج ذات أحجام الإدخال الأكبر.
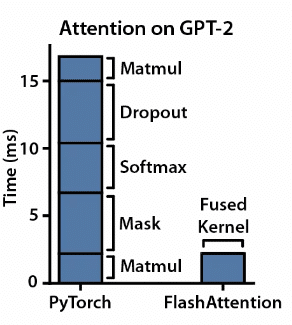
(نواة CUDA مدمجة تصور كيف أن التبليط والدمج يقللان من الوقت اللازم للحساب، مصدر الصورة: FlashAttention: انتباه دقيق سريع وفعال في الذاكرة مع وعي الإدخال والإخراج)
تحسين الذاكرة: يقوم Flash Attention بتحميل المعلمات للرموز القليلة الماضية فقط، وإعادة استخدام عمليات التنشيط من الرموز المميزة المحسوبة مؤخرًا. يقلل أسلوب النافذة المنزلقة هذا من عدد طلبات الإدخال/الإخراج لتحميل الأوزان ويزيد من إنتاجية ذاكرة الفلاش.
تقليل عمليات نقل البيانات: يعمل Flash Attention على تقليل عمليات نقل البيانات ذهابًا وإيابًا بين أنواع الذاكرة، مثل ذاكرة النطاق الترددي العالي (HBM) وSRAM (ذاكرة الوصول العشوائي الثابتة). عن طريق تحميل كافة البيانات (الاستعلامات والمفاتيح والقيم) مرة واحدة فقط، فإنه يقلل من الحمل الزائد لعمليات نقل البيانات المتكررة.
دراسة الحالة – تحسين الاستدلال من خلال فك التشفير التأملي
هناك طريقة أخرى تستخدم لتسريع عملية إنشاء النص في نموذج لغة الانحدار الذاتي وهي فك التشفير التأملي. الهدف الرئيسي من فك التشفير التأملي هو ربط عملية إنشاء النص مع الحفاظ على جودة النص الذي تم إنشاؤه بمستوى مماثل لمستوى التوزيع المستهدف.
يقدم فك التشفير التخميني نموذجًا صغيرًا/مسودة يتنبأ بالرموز المميزة اللاحقة في التسلسل، والتي يتم بعد ذلك قبولها/رفضها بواسطة النموذج الرئيسي بناءً على معايير محددة مسبقًا. يؤدي دمج نموذج مسودة أصغر مع النموذج المستهدف إلى تحسين سرعة إنشاء النص بشكل كبير، ويرجع ذلك إلى طبيعة متطلبات الذاكرة. وبما أن مشروع النموذج صغير، فإنه يتطلب أقل لا. من أوزان الخلايا العصبية المراد تحميلها ولا. كما أن عملية الحساب أقل الآن مقارنة بالنموذج الرئيسي، مما يقلل من زمن الوصول ويسرع عملية توليد المخرجات. يقوم النموذج الرئيسي بعد ذلك بتقييم النتائج التي تم إنشاؤها والتأكد من ملاءمتها للتوزيع المستهدف للرمز المميز التالي.
في الأساس، يعمل فك التشفير التخميني على تبسيط عملية إنشاء النص من خلال الاستفادة من نموذج مسودة أصغر وأسرع للتنبؤ بالرموز المميزة اللاحقة، وبالتالي تسريع السرعة الإجمالية لإنشاء النص مع الحفاظ على جودة المحتوى الذي تم إنشاؤه بالقرب من التوزيع المستهدف.
من المهم جدًا ألا يتم دائمًا رفض الرموز المميزة التي تم إنشاؤها بواسطة النماذج الأصغر حجمًا، فهذه الحالة تؤدي إلى انخفاض الأداء بدلاً من التحسين. من خلال التجارب وطبيعة حالات الاستخدام، يمكننا اختيار نموذج أصغر/إدخال فك التشفير التأملي في عملية الاستدلال.
خاتمة
تنير الرحلة عبر التقنيات المتقدمة لتعزيز إنتاجية نموذج اللغة الكبير (LLM) الطريق إلى الأمام في عالم معالجة اللغة الطبيعية، ولا تعرض التحديات فحسب، بل تعرض أيضًا الحلول المبتكرة التي يمكنها مواجهتها بشكل مباشر. هذه التقنيات، بدءًا من التجميع المستمر إلى Paged وFlash Attention، والنهج المثير للاهتمام المتمثل في فك التشفير التخميني، هي أكثر من مجرد تحسينات تدريجية. إنها تمثل قفزات كبيرة إلى الأمام في قدرتنا على جعل النماذج اللغوية الكبيرة أسرع وأكثر كفاءة وفي نهاية المطاف أكثر سهولة في الوصول لمجموعة واسعة من التطبيقات.
لا يمكن المبالغة في أهمية هذه التطورات. في تحسين إنتاجية LLM وتحسين الأداء، فإننا لا نقوم فقط بتعديل محركات هذه النماذج القوية؛ نحن نعيد تعريف ما هو ممكن من حيث سرعة المعالجة والكفاءة. وهذا بدوره يفتح آفاقًا جديدة لتطبيق نموذج اللغة الكبير، بدءًا من خدمات الترجمة اللغوية في الوقت الفعلي التي يمكن أن تعمل بسرعة المحادثة، إلى أدوات التحليل المتقدمة القادرة على معالجة مجموعات البيانات الضخمة بسرعة غير مسبوقة.
علاوة على ذلك، تؤكد هذه التقنيات على أهمية اتباع نهج متوازن لتحسين نماذج اللغة الكبيرة - وهو النهج الذي يأخذ في الاعتبار بعناية التفاعل بين السرعة والدقة والموارد الحسابية. وبينما ندفع حدود قدرات LLM، فإن الحفاظ على هذا التوازن سيكون أمرًا بالغ الأهمية لضمان استمرار هذه النماذج في العمل كأدوات متعددة الاستخدامات وموثوقة عبر عدد لا يحصى من الصناعات.
إن التقنيات المتقدمة لتعزيز إنتاجية نماذج اللغة الكبيرة هي أكثر من مجرد إنجازات تقنية؛ إنها معالم بارزة في التطور المستمر للذكاء الاصطناعي. إنهم يعدون بجعل LLMs أكثر قدرة على التكيف، وأكثر كفاءة، وأكثر قوة، مما يمهد الطريق للابتكارات المستقبلية التي ستستمر في تحويل مشهدنا الرقمي.
اقرأ المزيد حول بنية GPU لتحسين الاستدلال لنموذج اللغة الكبيرة في منشور مدونتنا الأخير