
Python Web Crawler – البرنامج التعليمي خطوة بخطوة
نشرت: 2023-12-07تعد برامج زحف الويب أدوات رائعة في عالم جمع البيانات وتجميع الويب. فهي تقوم بأتمتة عملية التنقل عبر الويب لجمع البيانات، والتي يمكن استخدامها لأغراض مختلفة، مثل فهرسة محركات البحث، أو استخراج البيانات، أو التحليل التنافسي. في هذا البرنامج التعليمي، سنبدأ في رحلة غنية بالمعلومات لبناء زاحف ويب أساسي باستخدام لغة Python، وهي لغة معروفة ببساطتها وقدراتها القوية في التعامل مع بيانات الويب.
توفر لغة Python، مع نظامها البيئي الغني بالمكتبات، منصة ممتازة لتطوير برامج زحف الويب. سواء كنت مطورًا ناشئًا، أو متحمسًا للبيانات، أو مجرد فضول حول كيفية عمل برامج زحف الويب، فقد تم تصميم هذا الدليل خطوة بخطوة لتعريفك بأساسيات الزحف إلى الويب وتزويدك بالمهارات اللازمة لإنشاء برنامج زحف خاص بك .
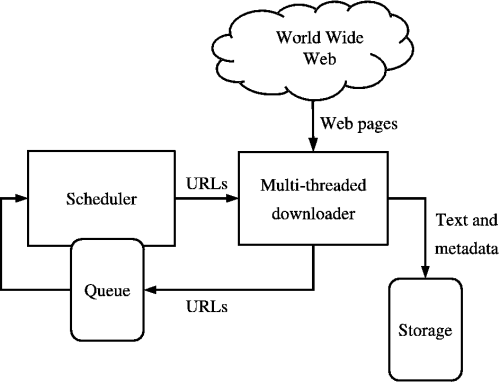
المصدر: https://medium.com/kariyertech/web-crawling-general-perspective-713971e9c659
Python Web Crawler – كيفية إنشاء زاحف الويب
الخطوة 1: فهم الأساسيات
زاحف الويب، المعروف أيضًا باسم العنكبوت، هو برنامج يتصفح شبكة الويب العالمية بطريقة منهجية وآلية. بالنسبة للزاحف الخاص بنا، سنستخدم لغة Python نظرًا لبساطتها ومكتباتها القوية.
الخطوة 2: إعداد بيئتك
تثبيت بايثون : تأكد من تثبيت بايثون. يمكنك تنزيله من python.org.
تثبيت المكتبات : ستحتاج إلى طلبات لإجراء طلبات HTTP وBeautifulSoup من bs4 لتحليل HTML. تثبيتها باستخدام النقطة:
طلبات تثبيت النقطة، تثبيت النقطة beautifulsoup4
الخطوة 3: كتابة الزاحف الأساسي
استيراد المكتبات :
طلبات الاستيراد من bs4 import BeautifulSoup
جلب صفحة ويب :
هنا، سنقوم بإحضار محتوى صفحة الويب. استبدل "URL" بصفحة الويب التي تريد الزحف إليها.
url = استجابة 'URL' = طلبات.get(url) المحتوى = Response.content
تحليل محتوى HTML :
حساء = BeautifulSoup(المحتوى، 'html.parser')
استخراج المعلومات :
على سبيل المثال، لاستخراج كافة الارتباطات التشعبية، يمكنك القيام بما يلي:
للارتباط في sauce.find_all('a'): print(link.get('href'))
الخطوة 4: قم بتوسيع الزاحف الخاص بك
التعامل مع عناوين URL النسبية :
استخدم urljoin للتعامل مع عناوين URL النسبية.
من urllib.parse استيراد urljoin
تجنب الزحف إلى نفس الصفحة مرتين :
احتفظ بمجموعة من عناوين URL التي تمت زيارتها لتجنب التكرار.
إضافة التأخير :
يتضمن الزحف المحترم التأخير بين الطلبات. استخدم time.sleep().
الخطوة 5: احترام ملف Robots.txt
تأكد من أن الزاحف الخاص بك يحترم ملف robots.txt الخاص بمواقع الويب، والذي يشير إلى أجزاء الموقع التي لا ينبغي الزحف إليها.
الخطوة 6: معالجة الأخطاء
قم بتنفيذ كتل المحاولة باستثناء التعامل مع الأخطاء المحتملة مثل مهلة الاتصال أو رفض الوصول.
الخطوة 7: الذهاب أعمق
يمكنك تحسين الزاحف الخاص بك للتعامل مع المهام الأكثر تعقيدًا، مثل عمليات إرسال النماذج أو عرض JavaScript. بالنسبة لمواقع الويب التي تعتمد على جافا سكريبت، فكر في استخدام السيلينيوم.
الخطوة 8: تخزين البيانات
قرر كيفية تخزين البيانات التي قمت بالزحف إليها. تتضمن الخيارات ملفات بسيطة أو قواعد بيانات أو حتى إرسال البيانات مباشرة إلى الخادم.
الخطوة 9: كن أخلاقيا
- لا تفرط في تحميل الخوادم؛ إضافة التأخير في طلباتك.
- اتبع شروط الخدمة الخاصة بالموقع.
- لا تقم بجمع أو تخزين البيانات الشخصية دون إذن.
يعد الحظر تحديًا شائعًا عند الزحف إلى الويب، خاصة عند التعامل مع مواقع الويب التي لديها إجراءات للكشف عن الوصول الآلي وحظره. فيما يلي بعض الاستراتيجيات والاعتبارات لمساعدتك في التغلب على هذه المشكلة في بايثون:
فهم سبب حظرك
الطلبات المتكررة: يمكن للطلبات السريعة والمتكررة من نفس عنوان IP أن تؤدي إلى الحظر.
الأنماط غير البشرية: غالبًا ما تظهر الروبوتات سلوكًا مختلفًا عن أنماط التصفح البشرية، مثل الوصول إلى الصفحات بسرعة كبيرة جدًا أو بتسلسل يمكن التنبؤ به.
سوء إدارة الرؤوس: قد تؤدي رؤوس HTTP المفقودة أو غير الصحيحة إلى جعل طلباتك تبدو مشبوهة.
تجاهل ملف robots.txt: قد يؤدي عدم الالتزام بالتوجيهات الموجودة في ملف robots.txt الخاص بالموقع إلى حدوث عمليات حظر.
استراتيجيات لتجنب التعرض للحظر
احترام ملف robots.txt : تحقق دائمًا من ملف robots.txt الخاص بموقع الويب والتزم به. إنها ممارسة أخلاقية ويمكن أن تمنع الحظر غير الضروري.

وكلاء المستخدم المتناوبون : يمكن لمواقع الويب التعرف عليك من خلال وكيل المستخدم الخاص بك. ومن خلال تدويره، فإنك تقلل من خطر وضع علامة عليك كروبوت. استخدم مكتبة fake_useragent لتنفيذ ذلك.
من fake_useragent استيراد UserAgent ua = رؤوس UserAgent() = {'User-Agent': ua.random}
إضافة تأخيرات : تنفيذ تأخير بين الطلبات يمكن أن يحاكي السلوك البشري. استخدم time.sleep() لإضافة تأخير عشوائي أو ثابت.
وقت الاستيراد time.sleep(3) # ينتظر لمدة 3 ثوان
تدوير IP : إذا أمكن، استخدم خدمات الوكيل لتدوير عنوان IP الخاص بك. هناك خدمات مجانية ومدفوعة متاحة لهذا الغرض.
استخدام الجلسات : يمكن أن يساعد كائن request.Session في Python في الحفاظ على اتصال ثابت ومشاركة الرؤوس وملفات تعريف الارتباط وما إلى ذلك عبر الطلبات، مما يجعل الزاحف الخاص بك يبدو وكأنه جلسة متصفح عادية.
مع request.Session() كجلسة: session.headers = {'User-Agent': ua.random} Response = session.get(url)
التعامل مع جافا سكريبت : تعتمد بعض مواقع الويب بشكل كبير على جافا سكريبت لتحميل المحتوى. يمكن لأدوات مثل Selenium أو Puppeteer أن تحاكي متصفحًا حقيقيًا، بما في ذلك عرض JavaScript.
معالجة الأخطاء : تنفيذ معالجة قوية للأخطاء لإدارة الكتل أو المشكلات الأخرى والرد عليها بأمان.
الاعتبارات الاخلاقية
- احترم دائمًا شروط خدمة موقع الويب. إذا كان أحد المواقع يحظر صراحةً تجريف الويب، فمن الأفضل الالتزام بذلك.
- انتبه إلى تأثير الزاحف الخاص بك على موارد موقع الويب. يمكن أن يؤدي التحميل الزائد على الخادم إلى حدوث مشكلات لمالك الموقع.
تقنيات متقدمة
- أطر عمل استخلاص الويب : فكر في استخدام أطر عمل مثل Scrapy، التي تحتوي على ميزات مضمنة للتعامل مع مشكلات الزحف المختلفة.
- خدمات حل اختبار CAPTCHA : بالنسبة للمواقع التي بها تحديات CAPTCHA، هناك خدمات يمكنها حل اختبارات CAPTCHA، على الرغم من أن استخدامها يثير مخاوف أخلاقية.
أفضل ممارسات الزحف على الويب في بايثون
يتطلب الانخراط في أنشطة الزحف على الويب تحقيق التوازن بين الكفاءة التقنية والمسؤولية الأخلاقية. عند استخدام Python للزحف على الويب، من المهم الالتزام بأفضل الممارسات التي تحترم البيانات ومواقع الويب التي يتم الحصول عليها منها. فيما يلي بعض الاعتبارات الأساسية وأفضل الممارسات للزحف إلى الويب في Python:
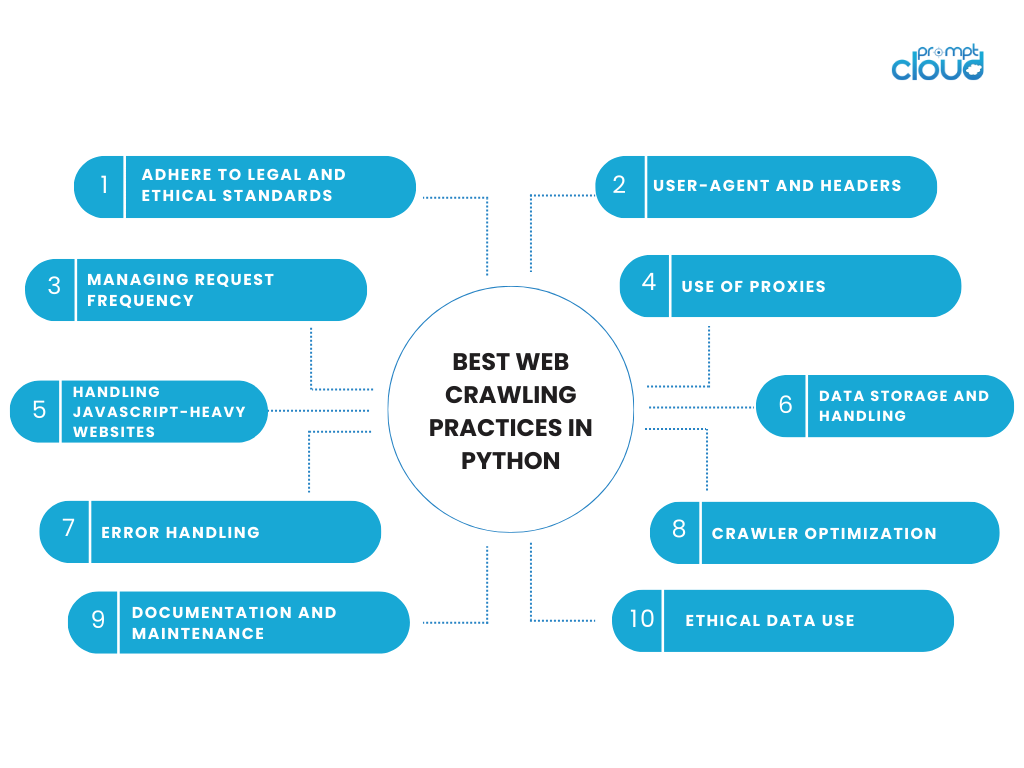
الالتزام بالمعايير القانونية والأخلاقية
- احترام ملف robots.txt: تحقق دائمًا من ملف robots.txt الخاص بموقع الويب. يوضح هذا الملف مناطق الموقع التي يفضل مالك موقع الويب عدم الزحف إليها.
- اتبع شروط الخدمة: تتضمن العديد من مواقع الويب بنودًا حول تجريف الويب في شروط الخدمة الخاصة بها. إن الالتزام بهذه الشروط هو أمر أخلاقي وقانوني.
- تجنب التحميل الزائد على الخوادم: قم بتقديم الطلبات بوتيرة معقولة لتجنب التحميل الزائد على خادم موقع الويب.
وكيل المستخدم والرؤوس
- حدد هويتك: استخدم سلسلة وكيل المستخدم التي تتضمن معلومات الاتصال الخاصة بك أو الغرض من الزحف. هذه الشفافية يمكن أن تبني الثقة.
- استخدم الرؤوس بشكل مناسب: يمكن لرؤوس HTTP التي تم تكوينها جيدًا أن تقلل من احتمالية حظرها. يمكن أن تتضمن معلومات مثل وكيل المستخدم ولغة القبول وما إلى ذلك.
إدارة تردد الطلب
- إضافة تأخيرات: تنفيذ تأخير بين الطلبات لتقليد أنماط التصفح البشري. استخدم وظيفة time.sleep() الخاصة ببايثون.
- تحديد المعدل: كن على دراية بعدد الطلبات التي ترسلها إلى موقع الويب خلال إطار زمني محدد.
استخدام الوكلاء
- تدوير عنوان IP: يمكن أن يساعد استخدام الوكلاء لتدوير عنوان IP الخاص بك في تجنب الحظر المستند إلى IP، ولكن يجب أن يتم ذلك بطريقة مسؤولة وأخلاقية.
التعامل مع مواقع الويب ذات جافا سكريبت الثقيلة
- المحتوى الديناميكي: بالنسبة للمواقع التي تقوم بتحميل المحتوى ديناميكيًا باستخدام JavaScript، يمكن لأدوات مثل Selenium أو Puppeteer (بالاشتراك مع Pyppeteer for Python) عرض الصفحات مثل المتصفح.
تخزين البيانات ومعالجتها
- تخزين البيانات: قم بتخزين البيانات التي تم الزحف إليها بطريقة مسؤولة، مع مراعاة قوانين ولوائح خصوصية البيانات.
- تقليل استخراج البيانات: قم باستخراج البيانات التي تحتاجها فقط. تجنب جمع المعلومات الشخصية أو الحساسة ما لم يكن ذلك ضروريًا وقانونيًا تمامًا.
معالجة الأخطاء
- معالجة قوية للأخطاء: تنفيذ معالجة شاملة للأخطاء لإدارة مشكلات مثل المهلات أو أخطاء الخادم أو المحتوى الذي يفشل في التحميل.
تحسين الزاحف
- قابلية التوسع: صمم الزاحف الخاص بك للتعامل مع الزيادة في الحجم، سواء من حيث عدد الصفحات التي تم الزحف إليها أو كمية البيانات التي تمت معالجتها.
- الكفاءة: قم بتحسين التعليمات البرمجية الخاصة بك لتحقيق الكفاءة. تعمل التعليمات البرمجية الفعالة على تقليل الحمل على كل من نظامك والخادم الهدف.
التوثيق والصيانة
- الاحتفاظ بالوثائق: قم بتوثيق التعليمات البرمجية ومنطق الزحف للرجوع إليها والصيانة في المستقبل.
- التحديثات المنتظمة: حافظ على تحديث تعليمات الزحف الخاصة بك، خاصة إذا تغيرت بنية موقع الويب المستهدف.
الاستخدام الأخلاقي للبيانات
- الاستخدام الأخلاقي: استخدم البيانات التي جمعتها بطريقة أخلاقية، مع احترام خصوصية المستخدم ومعايير استخدام البيانات.
ختاماً
في ختام استكشافنا لبناء زاحف ويب في بايثون، قمنا برحلة عبر تعقيدات جمع البيانات الآلي والاعتبارات الأخلاقية التي تأتي معها. لا يؤدي هذا المسعى إلى تعزيز مهاراتنا التقنية فحسب، بل يعمق أيضًا فهمنا للتعامل المسؤول مع البيانات في المشهد الرقمي الواسع.
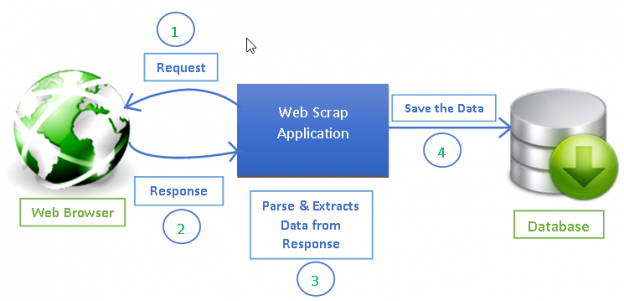
المصدر: https://www.datacamp.com/tutorial/make-web-crawlers-scrapy-python
ومع ذلك، قد يكون إنشاء زاحف الويب وصيانته مهمة معقدة وتستغرق وقتًا طويلاً، خاصة بالنسبة للشركات التي لديها احتياجات بيانات محددة وواسعة النطاق. هذا هو المكان الذي تلعب فيه خدمات تجريف الويب المخصصة من PromptCloud. إذا كنت تبحث عن حل مخصص وفعال وأخلاقي لمتطلبات بيانات الويب الخاصة بك، فإن PromptCloud يقدم مجموعة من الخدمات التي تناسب احتياجاتك الفريدة. بدءًا من التعامل مع مواقع الويب المعقدة ووصولاً إلى توفير بيانات نظيفة ومنظمة، فإنها تضمن أن تكون مشاريع تجريف الويب الخاصة بك خالية من المتاعب ومتوافقة مع أهداف عملك.
بالنسبة للشركات والأفراد الذين قد لا يكون لديهم الوقت أو الخبرة الفنية لتطوير وإدارة برامج زحف الويب الخاصة بهم، فإن الاستعانة بمصادر خارجية لهذه المهمة لخبراء مثل PromptCloud يمكن أن يغير قواعد اللعبة. لا توفر خدماتهم الوقت والموارد فحسب، بل تضمن أيضًا حصولك على البيانات الأكثر دقة وملاءمة، كل ذلك مع الالتزام بالمعايير القانونية والأخلاقية.
هل أنت مهتم بمعرفة المزيد حول كيفية تلبية PromptCloud لاحتياجاتك المحددة من البيانات؟ تواصل معهم على sales@promptcloud.com للحصول على مزيد من المعلومات ومناقشة كيف يمكن لحلول تجريف الويب المخصصة الخاصة بهم أن تساعد في دفع أعمالك إلى الأمام.
في عالم بيانات الويب الديناميكي، يمكن أن يؤدي وجود شريك موثوق به مثل PromptCloud إلى تمكين أعمالك، مما يمنحك الأفضلية في اتخاذ القرارات المستندة إلى البيانات. تذكر أنه في مجال جمع البيانات وتحليلها، فإن الشريك المناسب هو الذي يصنع الفارق.
صيد بيانات سعيد!