
اختيار وتكوين محركات الاستدلال لـ LLMs
نشرت: 2024-04-02مقدمة لمحركات الاستدلال
هناك العديد من تقنيات التحسين التي تم تطويرها للتخفيف من أوجه القصور التي تحدث في المراحل المختلفة لعملية الاستدلال. من الصعب قياس الاستدلال على نطاق واسع باستخدام محولات/تقنيات الفانيليا. تقوم محركات الاستدلال بتجميع التحسينات في حزمة واحدة وتسهل علينا عملية الاستدلال.
بالنسبة لمجموعة صغيرة جدًا من الاختبارات المخصصة، أو المرجع السريع، يمكننا استخدام كود محول الفانيليا للقيام بالاستدلال.
يتطور مشهد محركات الاستدلال بسرعة، نظرًا لأن لدينا خيارات متعددة، فمن المهم اختبار الأفضل وقائمة مختصرة لحالات استخدام محددة. فيما يلي بعض تجارب محركات الاستدلال التي قمنا بها والأسباب التي جعلتنا نكتشف سبب نجاحها في حالتنا.
لقد جربنا نموذج Vicuna-7B الذي تم ضبطه جيدًا
- تي جي آي
- vLLM
- أفروديت
- الأمثل نفيديا
- PowerInfer
- لاماكب
- كترجمة2
لقد مررنا بصفحة github ودليل البدء السريع الخاص بها لإعداد هذه المحركات، PowerInfer وLlaamaCPP وCtranslate2 ليست مرنة جدًا ولا تدعم العديد من تقنيات التحسين مثل التجميع المستمر والاهتمام المقسم إلى صفحات والأداء دون المستوى عند مقارنتها بالمحركات الأخرى المذكورة .
للحصول على إنتاجية أعلى، يجب على محرك/خادم الاستدلال زيادة الذاكرة وقدرات الحوسبة إلى أقصى حد ويجب أن يعمل كل من العميل والخادم بطريقة متوازية/غير متزامنة لخدمة الطلبات للحفاظ على الخادم في العمل دائمًا. كما ذكرنا سابقًا، بدون مساعدة تقنيات التحسين مثل PagedAttention، وFlash Attention، والتجميع المستمر، سيؤدي ذلك دائمًا إلى أداء دون المستوى الأمثل.
يعتبر كل من TGI وvLLM وAphrodite مرشحين أكثر ملاءمة في هذا الصدد، ومن خلال إجراء تجارب متعددة مذكورة أدناه، وجدنا التكوين الأمثل للحصول على أقصى قدر من الأداء من الاستدلال. يتم تمكين تقنيات مثل التجميع المستمر والاهتمام المقسم إلى صفحات بشكل افتراضي، ويجب تمكين فك التشفير التخميني يدويًا في محرك الاستدلال للاختبارات أدناه.
التحليل المقارن لمحركات الاستدلال
تي جي آي
لاستخدام TGI، يمكننا الانتقال إلى قسم "البدء" في صفحة github، وهنا يعد عامل الإرساء هو أبسط طريقة لتكوين محرك TGI واستخدامه.
وسائط مشغل إنشاء النص -> هذه قائمة بالإعدادات المختلفة التي يمكننا استخدامها من جانب الخادم. القليل من الأشياء المهمة،
- –max-input-length : يحدد الحد الأقصى لطول الإدخال للنموذج، وهذا يتطلب تغييرات في معظم الحالات، حيث أن القيمة الافتراضية هي 1024.
- -الحد الأقصى لإجمالي الرموز: الحد الأقصى إجمالي الرموز المميزة، أي طول رمز الإدخال + الإخراج.
- –speculate, –quantiz, –max-concurrent-requests -> الافتراضي هو 128 فقط وهو أقل بشكل واضح.
لبدء نموذج محلي مضبوط،
تشغيل عامل الميناء – جهاز gpus = 1 –shm-size 1g -p 9091:80 -v /path/to/fine_tuned_v1:/model ghcr.io/huggingface/text- Generation-inference:1.4.4 –model-id /model – dtype float16 –num-shard 1 –max-input-length 3600 –max-tokens-tokens 4000 –speculate 2
لبدء نموذج من المحور،
model=”lmsys/vicuna-7b-v1.5″; الحجم = $PWD/البيانات؛ رمز = "<hf_token>"; تشغيل عامل الميناء –gpus all –shm-size 1g -e HUGGING_FACE_HUB_TOKEN=$token -p 9091:80 -v $volume:/data ghcr.io/huggingface/text-generation-inference:1.4.4 –model-id $model – dtype float16 –num-shard 1 –max-input-length 3600 –max-tokens-tokens 4000 –speculate 2
يمكنك أن تطلب من chatGPT شرح الأمر أعلاه للحصول على فهم أكثر تفصيلاً. نحن هنا نبدأ خادم الاستدلال في منفذ 9091. ويمكننا استخدام عميل بأي لغة لنشر طلب على الخادم. تشير واجهة برمجة تطبيقات استدلال إنشاء النص -> إلى جميع نقاط النهاية ومعلمات الحمولة للطلب.
على سبيل المثال
الحمولة=”<المطالبة هنا>”
حليقة -XPOST "0.0.0.0:9091/إنشاء" -H "نوع المحتوى: application/json" -d "{"inputs": $payload، "parameters": {"max_new_tokens": 400،"do_sample": false "best_of": null، "repetition_penalty": 1، "return_full_text": false، "seed": null، "stop_sequences": null، "درجة الحرارة": 0.1، "top_k": 100، "top_p": 0.3،" اقتطاع": خالية،"typical_p": خالية، "العلامة المائية": خطأ، "decoder_input_details": خطأ}}"
ملاحظات قليلة،
- يزداد زمن الوصول مع الحد الأقصى للرموز المميزة، وهو أمر واضح أنه إذا كنا نعالج نصًا طويلًا، فسيزيد الوقت الإجمالي.
- تساعد المضاربة ولكنها تعتمد على حالة الاستخدام وتوزيع المدخلات والمخرجات.
- يساعد تكميم Eetq أكثر في زيادة الإنتاجية.
- إذا كان لديك وحدة معالجة رسومات متعددة، فإن تشغيل واجهة برمجة تطبيقات واحدة على كل وحدة معالجة رسومات ووجود واجهات برمجة تطبيقات GPU المتعددة خلف موازن التحميل يؤدي إلى إنتاجية أعلى من التجزئة بواسطة TGI نفسها.
vLLM
لبدء خادم vLLM، يمكننا استخدام خادم/عامل إرساء REST API متوافق مع OpenAI. من السهل جدًا البدء، اتبع النشر باستخدام Docker — vLLM، إذا كنت ستستخدم نموذجًا محليًا، فقم بإرفاق وحدة التخزين واستخدم المسار كاسم للنموذج،
تشغيل عامل الإرساء – وقت التشغيل nvidia –gpus devices=1 –shm-size 1g -v /path/to/fine_tuned_v1:/model -v ~/.cache/ -p 8000:8000 –ipc=host vllm/vllm-openai:latest – نموذج / نموذج
أعلاه سيبدأ خادم vLLM على منفذ 8000 المذكور، كما هو الحال دائمًا يمكنك اللعب بالوسائط.
تقديم طلب نشر مع،
"" قذيفة
الحمولة=”<المطالبة هنا>”
حليقة -XPOST -m 1200 "0.0.0.0:8000/v1/completions" -H "نوع المحتوى: application/json" -d "{"prompt": $payload،"model":"/model" ، max_tokens ": 400،"top_p": 0.3، "top_k": 100، "درجة الحرارة": 0.1}"

""
أفروديت
"" قذيفة
نقطة تثبيت محرك أفروديت
بايثون -m aphrodite.endpoints.openai.api_server –model PygmalionAI/pygmalion-2-7b
""
أو
""
تشغيل عامل الميناء -v /path/to/fine_tuned_v1:/model -d -e MODEL_NAME=”/model” -p 2242:7860 –gpus devices=1 –ipc host alpindale/aphrodite-engine
""
توفر أفروديت تثبيت النقطة ووحدة الإرساء كما هو مذكور في قسم البدء. يعد Docker عمومًا أسهل نسبيًا في التدوير والاختبار. خيارات الاستخدام، خيارات الخادم تساعدنا في كيفية تقديم الطلبات.
- يستخدم كل من Aphrodite وvLLM الحمولات المستندة إلى خادم openAI، حتى تتمكن من التحقق من وثائقه.
- لقد جربنا Deepspeed-mii، نظرًا لأنه في حالة انتقالية (عندما حاولنا) من قاعدة التعليمات البرمجية القديمة إلى قاعدة التعليمات البرمجية الجديدة، فإنه لا يبدو موثوقًا وسهل الاستخدام.
- لا يدعم Optimum-NVIDIA التحسينات الرئيسية الأخرى ويؤدي إلى أداء دون المستوى الأمثل، رابط المرجع.
- تمت إضافة جوهر الكود الذي استخدمناه لتنفيذ الطلبات الموازية المخصصة.
المقاييس والقياسات
نريد أن نجرب ونجد:
- الرقم الأمثل. من المواضيع لخادم محرك العميل/الاستدلال.
- كيف ينمو الإنتاجية زيادة في الذاكرة
- كيف ينمو معدل النقل النوى الموتر.
- تأثير المواضيع مقابل الطلب المتوازي من قبل العميل
الطريقة الأساسية جدًا لمراقبة الاستخدام هي مشاهدته عبر linux utils nvidia-smi وnvtop، وهذا سيخبرنا بالذاكرة المشغولة واستخدام الحساب ومعدل نقل البيانات وما إلى ذلك.
هناك طريقة أخرى وهي تحديد ملف تعريف العملية باستخدام GPU مع nsys.
| رقم S | GPU | ذاكرة vRAM | محرك الاستدلال | الخيوط | الوقت (ق) | المضاربة |
| 1 | A6000 | 48 / 48 جيجابايت | تي جي آي | 24 | 664 | - |
| 2 | A6000 | 48 / 48 جيجابايت | تي جي آي | 64 | 561 | - |
| 3 | A6000 | 48 / 48 جيجابايت | تي جي آي | 128 | 554 | - |
| 4 | A6000 | 48 / 48 جيجابايت | تي جي آي | 256 | 568 | - |
بناءً على التجارب المذكورة أعلاه، فإن 128/256 خيطًا أفضل من رقم الخيط السفلي وما بعد 256 من الحمل الزائد يساهم في تقليل الإنتاجية. وجد أن هذا يعتمد على وحدة المعالجة المركزية ووحدة معالجة الرسومات، ويحتاج إلى تجربة خاصة. | ||||||
| 5 | A6000 | 48 / 48 جيجابايت | تي جي آي | 128 | 596 | 2 |
| 6 | A6000 | 48 / 48 جيجابايت | تي جي آي | 128 | 945 | 8 |
تؤدي قيمة المضاربة الأعلى إلى المزيد من حالات الرفض لنموذجنا المضبوط بدقة وبالتالي تقليل الإنتاجية. 1 / 2 نظرًا لأن قيمة المضاربة جيدة، فهذا يخضع للنموذج وليس مضمونًا للعمل بنفس الطريقة عبر حالات الاستخدام. لكن الاستنتاج هو أن فك التشفير التخميني يحسن الإنتاجية. | ||||||
| 7 | 3090 | 24/ 24 جيجابايت | تي جي آي | 128 | 741 | 2 |
| 7 | 4090 | 24/ 24 جيجابايت | تي جي آي | 128 | 481 | 2 |
على الرغم من أن 4090 يحتوي على ذاكرة vRAM أقل مقارنةً بـ A6000، إلا أنه يتفوق في الأداء بسبب ارتفاع عدد النواة الموتر وسرعة عرض النطاق الترددي للذاكرة. | ||||||
| 8 | A6000 | 24/ 48 جيجابايت | تي جي آي | 128 | 707 | 2 |
| 9 | A6000 | 2 × 24/ 48 جيجابايت | تي جي آي | 128 | 1205 | 2 |
إعداد وتكوين TGI للإنتاجية العالية
قم بإعداد الطلب غير المتزامن بلغة البرمجة النصية المفضلة مثل python/Ruby وباستخدام نفس الملف للتكوين الذي وجدناه:
- الوقت المستغرق يزيد من الحد الأقصى لطول الإخراج لتوليد التسلسل.
- 128/256 سلسلة رسائل على العميل والخادم أفضل من 24، 64، 512. عند استخدام سلاسل رسائل أقل، لا يتم استخدام الحوسبة بشكل كافٍ، وبعد تجاوز عتبة مثل 128، يصبح الحمل أعلى وبالتالي تنخفض الإنتاجية.
- هناك تحسن بنسبة 6% عند الانتقال من الطلبات غير المتزامنة إلى الطلبات المتوازية باستخدام "GNUتوازي" بدلاً من الترابط في لغات مثل Go وPython/Ruby.
- 4090 لديه إنتاجية أعلى بنسبة 12% من A6000. على الرغم من أن 4090 يحتوي على ذاكرة vRAM أقل مقارنةً بـ A6000، إلا أنه يتفوق في الأداء بسبب ارتفاع عدد النواة الموتر وسرعة عرض النطاق الترددي للذاكرة.
- نظرًا لأن A6000 يحتوي على ذاكرة وصول عشوائي (vRAM) بسعة 48 جيجابايت، لاستنتاج ما إذا كانت ذاكرة الوصول العشوائي الإضافية تساعد في تحسين الإنتاجية أم لا، حاولنا استخدام أجزاء من ذاكرة وحدة معالجة الرسومات في التجربة 8 من الجدول، نرى أن ذاكرة الوصول العشوائي الإضافية تساعد في التحسين ولكن ليس بشكل خطي. أيضًا عند محاولة تقسيم أي استضافة 2 API على نفس وحدة معالجة الرسومات باستخدام نصف الذاكرة لكل واجهة برمجة تطبيقات، فإنها تتصرف مثل 2 API متسلسلتين قيد التشغيل، بدلاً من قبول الطلبات بشكل متوازي.
الملاحظات والمقاييس
وفيما يلي الرسوم البيانية لبعض التجارب والوقت المستغرق لإكمال مجموعة المدخلات الثابتة، كلما كان الوقت المستغرق أقل هو الأفضل.
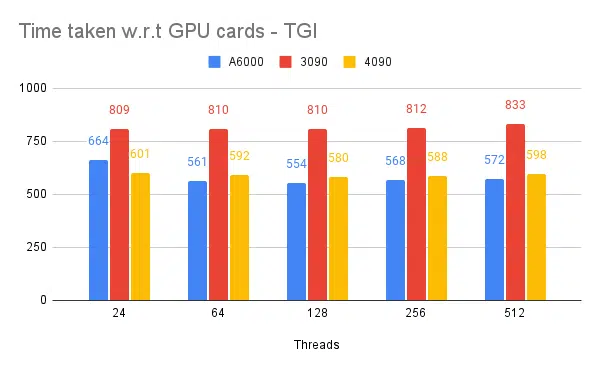
- المذكورة هي المواضيع من جانب العميل. جانب الخادم الذي نحتاج إلى ذكره أثناء بدء تشغيل محرك الاستدلال.
اختبار التخمين:

اختبار محركات الاستدلال المتعددة:
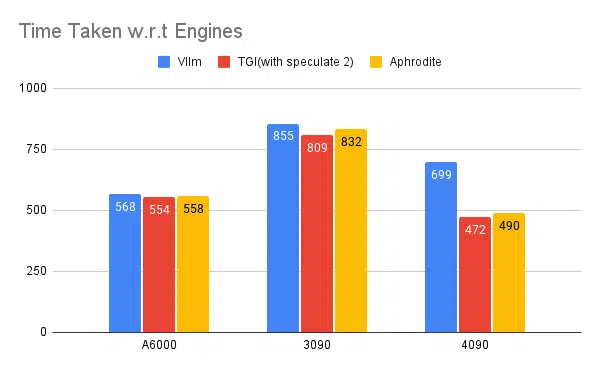
نفس النوع من التجارب التي تم إجراؤها مع محركات أخرى مثل vLLM وAphrodite نلاحظ نتائج مماثلة، اعتبارًا من كتابة هذا المقال، لا يدعم vLLM وAphrodite فك التشفير التخميني حتى الآن، مما يتركنا نختار TGI لأنه يعطي إنتاجية أعلى من الباقي المستحق لفك التشفير المضاربة.
بالإضافة إلى ذلك، يمكنك تكوين ملفات تعريف GPU لتحسين إمكانية المراقبة، مما يساعد في تحديد المناطق ذات الاستخدام المفرط للموارد وتحسين الأداء. اقرأ المزيد: أدوات مطور Nvidia Nsight - Max Katz
خاتمة
نحن نرى أن مشهد توليد الاستدلال يتطور باستمرار وأن تحسين الإنتاجية في LLM يتطلب فهمًا جيدًا لوحدة معالجة الرسومات ومقاييس الأداء وتقنيات التحسين والتحديات المرتبطة بمهام إنشاء النص. وهذا يساعد في اختيار الأدوات المناسبة لهذا المنصب. من خلال فهم الأجزاء الداخلية لوحدة معالجة الرسومات وكيفية توافقها مع استدلال LLM، مثل الاستفادة من نوى الموتر وزيادة عرض النطاق الترددي للذاكرة، يمكن للمطورين اختيار وحدة معالجة الرسومات الفعالة من حيث التكلفة وتحسين الأداء بفعالية.
توفر بطاقات GPU المختلفة إمكانيات مختلفة، ويعد فهم الاختلافات أمرًا بالغ الأهمية لاختيار الأجهزة الأكثر ملاءمة لمهام محددة. توفر تقنيات مثل التجميع المستمر، والاهتمام المقسم إلى صفحات، ودمج kernel، والاهتمام السريع حلولاً واعدة للتغلب على التحديات الناشئة وتحسين الكفاءة. يبدو TGI هو الخيار الأفضل لحالة الاستخدام لدينا بناءً على التجارب والنتائج التي نحصل عليها.
اقرأ مقالات أخرى متعلقة بنموذج اللغة الكبير:
فهم بنية GPU لتحسين الاستدلال LLM
تقنيات متقدمة لتعزيز إنتاجية LLM