
دليل خطوة بخطوة لإنشاء زاحف الويب
نشرت: 2023-12-05في نسيج الإنترنت المعقد، حيث تنتشر المعلومات عبر عدد لا يحصى من مواقع الويب، تظهر برامج زحف الويب كأبطال مجهولين، يعملون بجد لتنظيم وفهرسة وإتاحة الوصول إلى هذه الثروة من البيانات. تبدأ هذه المقالة في استكشاف برامج زحف الويب، وتسليط الضوء على أعمالها الأساسية، والتمييز بين زحف الويب واستخراج الويب، وتقديم رؤى عملية مثل دليل خطوة بخطوة لصياغة زاحف ويب بسيط يعتمد على لغة بايثون. وبينما نتعمق أكثر، سنكتشف إمكانيات الأدوات المتقدمة مثل Scrapy ونكتشف كيف تعمل PromptCloud على رفع مستوى الزحف على الويب إلى مستوى صناعي.
ما هو زاحف الويب
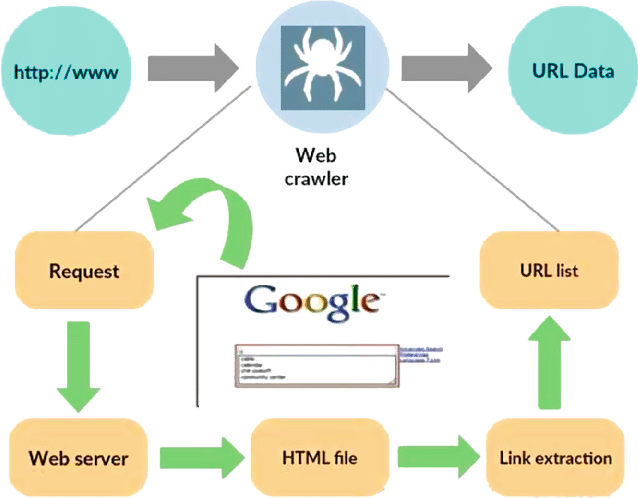
المصدر: https://www.researchgate.net/figure/Working-model-of-web-crawler_fig1_316089973
زاحف الويب، المعروف أيضًا باسم العنكبوت أو الروبوت، هو برنامج متخصص مصمم للتنقل بشكل منهجي ومستقل في الامتداد الشاسع لشبكة الويب العالمية. وتتمثل وظيفتها الأساسية في اجتياز مواقع الويب وجمع البيانات وفهرسة المعلومات لأغراض مختلفة، مثل تحسين محرك البحث أو فهرسة المحتوى أو استخراج البيانات.
في جوهره، يحاكي زاحف الويب تصرفات المستخدم البشري، ولكن بوتيرة أسرع وأكثر كفاءة. يبدأ رحلته من نقطة بداية محددة، يُشار إليها غالبًا بعنوان URL الأولي، ثم يتبع الارتباطات التشعبية من صفحة ويب إلى أخرى. تعتبر عملية تتبع الروابط هذه متكررة، مما يسمح للزاحف باستكشاف جزء كبير من الإنترنت.
عندما يزور الزاحف صفحات الويب، فإنه يستخرج البيانات ذات الصلة ويخزنها بشكل منهجي، والتي يمكن أن تشمل النصوص والصور والبيانات الوصفية والمزيد. يتم بعد ذلك تنظيم البيانات المستخرجة وفهرستها، مما يسهل على محركات البحث استرداد المعلومات ذات الصلة وتقديمها للمستخدمين عند الاستعلام عنها.
تلعب برامج زحف الويب دورًا محوريًا في وظائف محركات البحث مثل Google وBing وYahoo. ومن خلال الزحف المستمر والمنظم إلى الويب، فإنهم يضمنون تحديث فهارس محركات البحث، مما يوفر للمستخدمين نتائج بحث دقيقة وذات صلة. بالإضافة إلى ذلك، يتم استخدام برامج زحف الويب في العديد من التطبيقات الأخرى، بما في ذلك تجميع المحتوى ومراقبة موقع الويب واستخراج البيانات.
تعتمد فعالية زاحف الويب على قدرته على التنقل بين هياكل مواقع الويب المتنوعة، والتعامل مع المحتوى الديناميكي، واحترام القواعد التي تحددها مواقع الويب من خلال ملف robots.txt، الذي يحدد أجزاء الموقع التي يمكن الزحف إليها. يعد فهم كيفية عمل برامج زحف الويب أمرًا أساسيًا لتقدير أهميتها في تسهيل الوصول إلى شبكة المعلومات الواسعة وتنظيمها.
كيف تعمل برامج زحف الويب
تعمل برامج زحف الويب، المعروفة أيضًا باسم العناكب أو الروبوتات، من خلال عملية منهجية للتنقل في شبكة الويب العالمية لجمع المعلومات من مواقع الويب. فيما يلي نظرة عامة على كيفية عمل برامج زحف الويب:
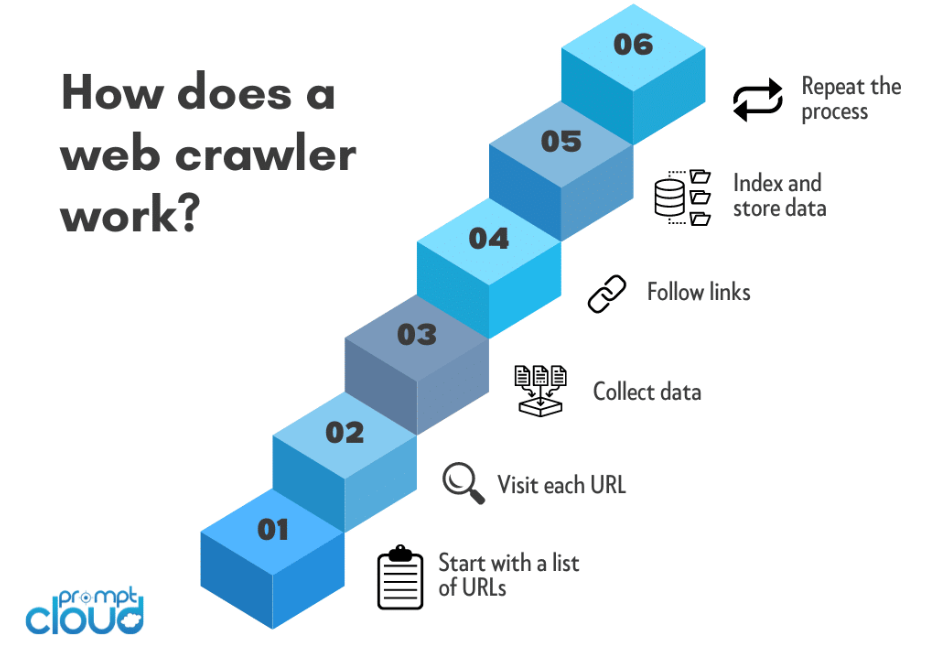
اختيار عنوان URL للبذور:
تبدأ عملية الزحف على الويب عادةً بعنوان URL الأولي. هذه هي صفحة الويب أو موقع الويب الأولي الذي يبدأ الزاحف رحلته منه.
طلب HTTP:
يرسل الزاحف طلب HTTP إلى عنوان URL الأولي لاسترداد محتوى HTML لصفحة الويب. يشبه هذا الطلب الطلبات التي تقدمها متصفحات الويب عند الوصول إلى موقع ويب.
تحليل HTML:
بمجرد جلب محتوى HTML، يقوم الزاحف بتحليله لاستخراج المعلومات ذات الصلة. يتضمن ذلك تقسيم تعليمات HTML البرمجية إلى تنسيق منظم يمكن للزاحف التنقل فيه وتحليله.
استخراج URL:
يقوم الزاحف بتحديد واستخراج الارتباطات التشعبية (عناوين URL) الموجودة في محتوى HTML. تمثل عناوين URL هذه روابط لصفحات أخرى سيزورها الزاحف لاحقًا.
قائمة الانتظار والمجدول:
تتم إضافة عناوين URL المستخرجة إلى قائمة الانتظار أو المجدول. تضمن قائمة الانتظار أن يقوم الزاحف بزيارة عناوين URL بترتيب معين، وغالبًا ما يعطي الأولوية لعناوين URL الجديدة أو التي لم تتم زيارتها أولاً.
العودية:
يتبع الزاحف الروابط الموجودة في قائمة الانتظار، ويكرر عملية إرسال طلبات HTTP، وتحليل محتوى HTML، واستخراج عناوين URL جديدة. تسمح هذه العملية المتكررة للزاحف بالتنقل عبر طبقات متعددة من صفحات الويب.
استخراج البيانات:
أثناء قيام الزاحف باجتياز الويب، فإنه يستخرج البيانات ذات الصلة من كل صفحة تمت زيارتها. يعتمد نوع البيانات المستخرجة على الغرض من الزاحف وقد يتضمن نصًا أو صورًا أو بيانات وصفية أو أي محتوى محدد آخر.
فهرسة المحتوى:
يتم تنظيم البيانات التي تم جمعها وفهرستها. تتضمن الفهرسة إنشاء قاعدة بيانات منظمة تجعل من السهل البحث عن المعلومات واسترجاعها وتقديمها عندما يقوم المستخدمون بإرسال الاستعلامات.
احترام ملف Robots.txt:
تلتزم برامج زحف الويب عادةً بالقواعد المحددة في ملف robots.txt الخاص بموقع الويب. يوفر هذا الملف إرشادات حول مناطق الموقع التي يمكن الزحف إليها وتلك التي يجب استبعادها.
تأخير الزحف والأدب:
لتجنب التحميل الزائد على الخوادم والتسبب في حدوث اضطرابات، غالبًا ما تقوم برامج الزحف بدمج آليات لتأخير الزحف والأدب. تضمن هذه الإجراءات أن يتفاعل الزاحف مع مواقع الويب بطريقة محترمة وغير مزعجة.
تتنقل برامج زحف الويب بشكل منهجي على الويب، وتتبع الروابط، وتستخرج البيانات، وتنشئ فهرسًا منظمًا. تتيح هذه العملية لمحركات البحث تقديم نتائج دقيقة وذات صلة للمستخدمين بناءً على استفساراتهم، مما يجعل برامج زحف الويب مكونًا أساسيًا في النظام البيئي الحديث للإنترنت.
الزحف على الويب مقابل تجريف الويب

المصدر: https://research.aimultiple.com/web-crawling-vs-web-scraping/

على الرغم من أن الزحف على الويب وتجميع الويب غالبًا ما يتم استخدامهما بالتبادل، إلا أنهما يخدمان أغراضًا مختلفة. يتضمن الزحف على الويب التنقل بشكل منهجي في الويب لفهرسة المعلومات وجمعها، بينما يركز تجريف الويب على استخراج بيانات محددة من صفحات الويب. في جوهره، يتعلق الزحف على الويب باستكشاف الويب ورسم خرائط له، في حين أن تجريف الويب يتعلق بجمع المعلومات المستهدفة.
بناء زاحف الويب
يتضمن إنشاء زاحف ويب بسيط في Python عدة خطوات، بدءًا من إعداد بيئة التطوير وحتى ترميز منطق الزاحف. يوجد أدناه دليل تفصيلي لمساعدتك في إنشاء زاحف ويب أساسي باستخدام Python، وذلك باستخدام مكتبة الطلبات لإجراء طلبات HTTP وBeautifulSoup لتحليل HTML.
الخطوة 1: إعداد البيئة
تأكد من تثبيت Python على نظامك. يمكنك تنزيله من python.org. بالإضافة إلى ذلك، ستحتاج إلى تثبيت المكتبات المطلوبة:
pip install requests beautifulsoup4
الخطوة 2: استيراد المكتبات
قم بإنشاء ملف Python جديد (على سبيل المثال، simple_crawler.py) وقم باستيراد المكتبات الضرورية:
import requests from bs4 import BeautifulSoup
الخطوة 3: تحديد وظيفة الزاحف
قم بإنشاء وظيفة تأخذ عنوان URL كمدخل، وترسل طلب HTTP، وتستخرج المعلومات ذات الصلة من محتوى HTML:
def simple_crawler(url):
# Send HTTP request to the URL
response = requests.get(url)
# Check if the request was successful (status code 200)
if response.status_code == 200:
# Parse HTML content with BeautifulSoup
soup = BeautifulSoup(response.text, 'html.parser')
# Extract and print relevant information (modify as needed)
title = soup.title.text
print(f'Title: {title}')
# Additional data extraction and processing can be added here
else:
print(f'Error: Failed to fetch {url}')
الخطوة 4: اختبار الزاحف
قم بتوفير نموذج لعنوان URL واستدعاء وظيفة simple_crawler لاختبار الزاحف:
if __name__ == "__main__": sample_url = 'https://example.com' simple_crawler(sample_url)
الخطوة 5: تشغيل الزاحف
قم بتنفيذ البرنامج النصي Python في المحطة الطرفية أو موجه الأوامر:
python simple_crawler.py
سيقوم الزاحف بجلب محتوى HTML لعنوان URL المقدم، وتحليله، وطباعة العنوان. يمكنك توسيع الزاحف عن طريق إضافة المزيد من الوظائف لاستخراج أنواع مختلفة من البيانات.
الزحف على الويب باستخدام Scrapy
يفتح الزحف إلى الويب باستخدام Scrapy الباب أمام إطار عمل قوي ومرن مصمم خصيصًا لتجميع الويب بكفاءة وقابلية للتطوير. يعمل Scrapy على تبسيط تعقيدات إنشاء برامج زحف الويب، مما يوفر بيئة منظمة لصياغة العناكب التي يمكنها التنقل في مواقع الويب واستخراج البيانات وتخزينها بطريقة منهجية. فيما يلي نظرة فاحصة على الزحف إلى الويب باستخدام Scrapy:
تثبيت:
قبل البدء، تأكد من تثبيت Scrapy. يمكنك تثبيته باستخدام:
pip install scrapy
إنشاء مشروع Scrapy:
ابدأ مشروع Scrapy:
افتح محطة وانتقل إلى الدليل الذي تريد إنشاء مشروع Scrapy الخاص بك فيه. قم بتشغيل الأمر التالي:
scrapy startproject your_project_name
يؤدي هذا إلى إنشاء بنية المشروع الأساسية مع الملفات الضرورية.
تعريف العنكبوت:
داخل دليل المشروع، انتقل إلى مجلد العناكب وقم بإنشاء ملف Python للعنكبوت الخاص بك. حدد فئة العنكبوت عن طريق التصنيف الفرعي سكرابي.سبايدر وتوفير التفاصيل الأساسية مثل الاسم والمجالات المسموح بها وعناوين URL للبدء.
import scrapy
class YourSpider(scrapy.Spider):
name = 'your_spider'
allowed_domains = ['example.com']
start_urls = ['http://example.com']
def parse(self, response):
# Define parsing logic here
pass
استخراج البيانات:
استخدام المحددات:
يستخدم Scrapy محددات قوية لاستخراج البيانات من HTML. يمكنك تحديد المحددات بطريقة تحليل العنكبوت لالتقاط عناصر محددة.
def parse(self, response):
title = response.css('title::text').get()
yield {'title': title}
يستخرج هذا المثال محتوى نص العلامة <title>.
الروابط التالية:
Scrapy يبسط عملية الروابط التالية. استخدم طريقة المتابعة للانتقال إلى الصفحات الأخرى.
def parse(self, response):
for next_page in response.css('a::attr(href)').getall():
yield response.follow(next_page, self.parse)
تشغيل العنكبوت:
قم بتنفيذ العنكبوت باستخدام الأمر التالي من دليل المشروع:
scrapy crawl your_spider
سيقوم Scrapy ببدء العنكبوت، واتباع الروابط، وتنفيذ منطق التحليل المحدد في طريقة التحليل.
يوفر الزحف إلى الويب باستخدام Scrapy إطارًا قويًا وقابل للتوسيع للتعامل مع مهام التجريد المعقدة. إن بنيته المعيارية وميزاته المضمنة تجعله خيارًا مفضلاً للمطورين المشاركين في مشاريع استخراج بيانات الويب المتطورة.
الزحف على شبكة الإنترنت على نطاق واسع
يمثل الزحف على الويب على نطاق واسع تحديات فريدة، خاصة عند التعامل مع كمية هائلة من البيانات المنتشرة عبر العديد من مواقع الويب. PromptCloud عبارة عن منصة متخصصة مصممة لتبسيط عملية الزحف على الويب وتحسينها على نطاق واسع. إليك كيف يمكن لـ PromptCloud المساعدة في التعامل مع مبادرات الزحف على الويب واسعة النطاق:
- قابلية التوسع
- استخراج البيانات وإثرائها
- جودة البيانات ودقتها
- إدارة البنية التحتية
- سهولة الاستعمال
- الامتثال والأخلاق
- المراقبة وإعداد التقارير في الوقت الحقيقي
- الدعم والصيانة
يعد PromptCloud حلاً قويًا للمؤسسات والأفراد الذين يسعون إلى إجراء الزحف على الويب على نطاق واسع. من خلال معالجة التحديات الرئيسية المرتبطة باستخراج البيانات على نطاق واسع، تعمل المنصة على تحسين الكفاءة والموثوقية وسهولة الإدارة لمبادرات الزحف على الويب.
في ملخص
تقف برامج زحف الويب كأبطال مجهولين في المشهد الرقمي الواسع، حيث تتنقل بجدية في الويب لفهرسة المعلومات وجمعها وتنظيمها. مع توسع نطاق مشاريع الزحف على الويب، تتدخل PromptCloud كحل، مما يوفر قابلية التوسع وإثراء البيانات والامتثال الأخلاقي لتبسيط المبادرات واسعة النطاق. تواصل معنا على sales@promptcloud.com