
إطلاق العنان لإمكانات الذكاء الاصطناعي في استخلاص مواقع الويب: نظرة عامة
نشرت: 2024-02-02لقد تحول تجريف الويب اليوم من نشاط برمجي متخصص إلى أداة عمل أساسية. في البداية، كان الاستخراج عملية يدوية، حيث يقوم الأفراد بنسخ البيانات من صفحات الويب. لقد قدم تطور التكنولوجيا نصوصًا آلية يمكنها استخراج البيانات بشكل أكثر كفاءة، ولو بشكل فظ.
مع تطور مواقع الويب، تطورت أيضًا تقنيات الكشط، حيث تتكيف مع الهياكل المعقدة وتقاوم إجراءات مكافحة الكشط. لقد أدى التقدم في الذكاء الاصطناعي والتعلم الآلي إلى دفع عملية تصفح الويب إلى مناطق مجهولة، مما أتاح فهم السياق وأساليب قابلة للتكيف تحاكي سلوكيات التصفح البشري. يشكل هذا التقدم المستمر كيفية تسخير المؤسسات لبيانات الويب على نطاق واسع وبتطور غير مسبوق.
ظهور الذكاء الاصطناعي في تجريف الويب

مصدر الصورة: https://www.scrapehero.com/
لا يمكن المبالغة في تقدير تأثير الذكاء الاصطناعي (AI) على تجريف الويب؛ لقد غيّر المشهد تمامًا، مما جعل العملية أكثر كفاءة. لقد ولت أيام التكوينات اليدوية الشاقة واليقظة المستمرة للتكيف مع هياكل مواقع الويب المتغيرة.
الآن، وبفضل الذكاء الاصطناعي، تطورت أدوات استخراج بيانات الويب إلى أدوات بديهية قادرة على التعلم من الأنماط والتكيف بشكل مستقل مع التغييرات الهيكلية دون إشراف بشري مستمر. وهذا يعني أنهم يستطيعون فهم سياق البيانات، وتمييز ما هو ذي صلة بدقة ملحوظة، وترك ما هو غريب وراءهم.
لقد أحدثت هذه الطريقة الأكثر ذكاءً ومرونة تحولًا في عملية استخراج البيانات، وتزويد الصناعات بالأدوات اللازمة لاتخاذ قرارات مستنيرة بشكل أفضل ترتكز على جودة البيانات من الدرجة الأولى. مع تقدم تكنولوجيا الذكاء الاصطناعي، فإن دمجها في أدوات استخراج البيانات من الويب من شأنه أن يؤدي إلى إنشاء معايير جديدة، مما يؤدي بشكل أساسي إلى تغيير جوهر كيفية جمعنا للمعلومات من الويب.
الاعتبارات الأخلاقية والقانونية في تجريف الويب الحديث
ومع تطور عملية استخراج البيانات من الويب مع تطورات الذكاء الاصطناعي، أصبحت الآثار الأخلاقية والقانونية أكثر تعقيدًا. يجب أن تتنقل أدوات كاشطات الويب:
- قوانين خصوصية البيانات : يجب على مطوري برنامج Scraper فهم التشريعات مثل القانون العام لحماية البيانات (GDPR) وقانون خصوصية المستهلك في كاليفورنيا (CCPA) لتجنب الانتهاكات القانونية المتعلقة بالبيانات الشخصية.
- الامتثال لشروط الخدمة : يعد احترام شروط الخدمة الخاصة بموقع الويب أمرًا بالغ الأهمية؛ يمكن أن يؤدي الكشط المخالف لهذه إلى التقاضي أو رفض الوصول.
- المواد المحمية بحقوق الطبع والنشر : يجب ألا ينتهك المحتوى الذي تم الحصول عليه حقوق الطبع والنشر، مما يثير المخاوف بشأن توزيع واستخدام البيانات المسروقة.
- معيار استبعاد الروبوتات : يشير الالتزام بملف robots.txt الخاص بمواقع الويب إلى السلوك الأخلاقي من خلال احترام تفضيلات مالك الموقع.
- موافقة المستخدم : عندما يتعلق الأمر بالبيانات الشخصية، فإن ضمان الحصول على موافقة المستخدم يحافظ على النزاهة الأخلاقية.
- الشفافية : التواصل الواضح فيما يتعلق بقصد ونطاق عمليات الكشط يعزز بيئة من الثقة والمساءلة.
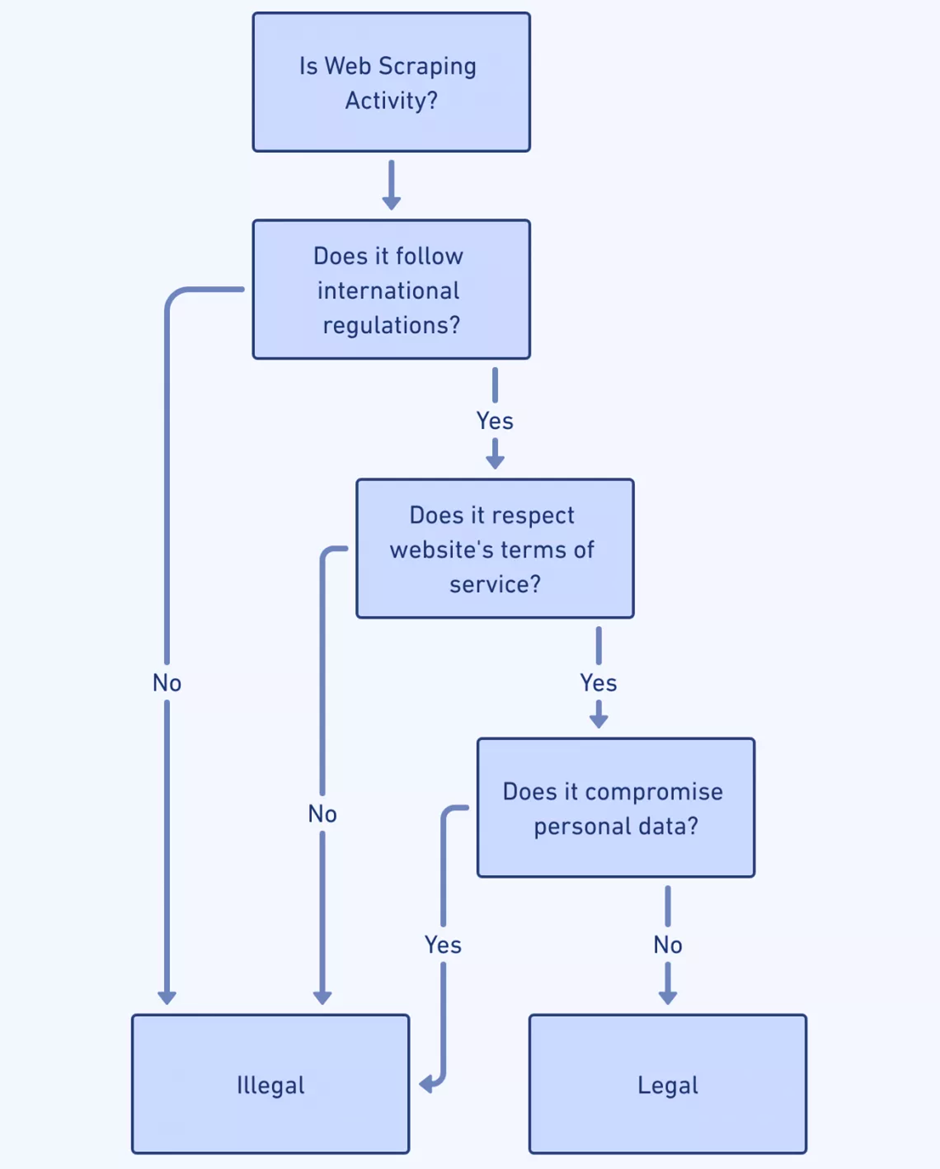
مصدر الصورة: https://scrape-it.cloud/
إن الإبحار في هذه الاعتبارات يتطلب اليقظة والالتزام بالممارسات الأخلاقية.
التطورات في خوارزميات الذكاء الاصطناعي لتحسين استخلاص البيانات
لقد لاحظنا مؤخرًا تطورًا ملحوظًا في خوارزميات الذكاء الاصطناعي، مما أدى إلى إعادة تشكيل مشهد قدرات استخراج البيانات بشكل كبير. لقد أدت نماذج التعلم الآلي المتقدمة، التي تُظهر قدرة محسنة على فك رموز الأنماط المعقدة، إلى رفع دقة استخراج البيانات إلى مستويات غير مسبوقة.

أدت التطورات في معالجة اللغات الطبيعية (NLP) إلى تعميق فهم السياق، ليس فقط تسهيل استخراج المعلومات ذات الصلة ولكن أيضًا تمكين تفسير الفروق الدقيقة والمشاعر الدلالية الدقيقة.
أدى ظهور الشبكات العصبية، وخاصة الشبكات العصبية التلافيفية (CNNs)، إلى ثورة في استخراج بيانات الصور. يعمل هذا الاختراق على تمكين الذكاء الاصطناعي ليس فقط من التعرف على المحتوى المرئي الذي يتم الحصول عليه من مساحة واسعة من الإنترنت، بل أيضًا من تصنيفه.
علاوة على ذلك، قدم التعلم المعزز (RL) نموذجًا جديدًا، حيث تعمل أدوات الذكاء الاصطناعي على تحسين استراتيجيات الكشط المثالية بمرور الوقت، وبالتالي تعزيز كفاءتها التشغيلية. وقد أدى دمج هذه الخوارزميات في أدوات تجريف الويب إلى ما يلي:
- تفسير وتحليل البيانات المتطورة
- تحسين القدرة على التكيف مع هياكل الويب المتنوعة
- تقليل الحاجة للتدخل البشري في المهام المعقدة
- تعزيز الكفاءة في التعامل مع استخراج البيانات على نطاق واسع
التغلب على العوائق: اختبارات CAPTCHA، والمحتوى الديناميكي، وجودة البيانات
يجب أن تتغلب تقنية تجريف الويب على عدة عقبات:
- اختبارات CAPTCHA : تستخدم أدوات استخراج مواقع الويب ذات الذكاء الاصطناعي الآن خوارزميات متقدمة للتعرف على الصور والتعلم الآلي لحل اختبارات CAPTCHA بدقة أعلى، مما يتيح الوصول إليها دون تدخل بشري.
- المحتوى الديناميكي : تم تصميم أدوات استخراج مواقع الويب ذات الذكاء الاصطناعي لتفسير JavaScript وAJAX التي تولد محتوى ديناميكيًا، مما يضمن التقاط البيانات من تطبيقات الويب بنفس الفعالية من الصفحات الثابتة.

مصدر الصورة: PromptCloud
- جودة البيانات : أدى إدخال الذكاء الاصطناعي إلى تحسينات في تحديد البيانات وتصنيفها. وذلك للتأكد من أن المعلومات التي تم جمعها ذات صلة وذات جودة عالية، مما يقلل الحاجة إلى التنظيف اليدوي والتحقق. تتعلم أدوات استخراج مواقع الويب الخاصة بالذكاء الاصطناعي باستمرار كيفية التمييز بين الضوضاء والبيانات القيمة، مما يؤدي إلى تحسين عملية استخراج البيانات الخاصة بها.
دمج الذكاء الاصطناعي مع تحليلات البيانات الضخمة في تجريف الويب
يمثل دمج الذكاء الاصطناعي (AI) مع تحليلات البيانات الضخمة قفزة تحويلية إلى الأمام في تجريف الويب. في هذا التكامل:
- يتم نشر خوارزميات الذكاء الاصطناعي لتفسير وتحليل مجموعات البيانات الضخمة التي يتم تسخيرها من خلال الاستخراج، وتحقيق رؤى بسرعات غير مسبوقة.
- يمكن لعناصر التعلم الآلي داخل الذكاء الاصطناعي أن تزيد من تعزيز استخراج البيانات، وتعلم تحديد واستقراء الأنماط والمعلومات بكفاءة.
- يمكن لتحليلات البيانات الضخمة بعد ذلك معالجة هذه المعلومات، مما يوفر للشركات معلومات استخباراتية قابلة للتنفيذ.
- بالإضافة إلى ذلك، يساعد الذكاء الاصطناعي في تنظيف البيانات وهيكلتها، وهي خطوة حاسمة للاستفادة من تحليلات البيانات الضخمة بشكل فعال.
- يعد هذا التآزر بين الذكاء الاصطناعي وتحليلات البيانات الضخمة في استخراج البيانات من الويب أمرًا بالغ الأهمية لاتخاذ القرارات الحساسة للوقت والحفاظ على المزايا التنافسية.
المشهد المستقبلي: التنبؤات وإمكانات كاشطات مواقع الويب المعتمدة على الذكاء الاصطناعي
يقف عالم تجريف موقع الويب الخاص بالذكاء الاصطناعي على عتبة تحول كبيرة. تشير التوقعات إلى:
- قدرات معرفية معززة، مما يسمح للكاشطات بتفسير البيانات المعقدة بفهم يشبه فهم الإنسان.
- التكامل مع تقنيات الذكاء الاصطناعي الأخرى مثل معالجة اللغة الطبيعية لاستخراج البيانات بشكل أكثر دقة.
- كاشطات التعلم الذاتي التي تعمل على تحسين أساليبها بناءً على معدلات النجاح، مما يؤدي إلى إنشاء بروتوكولات أكثر كفاءة لجمع البيانات.
- التزام أكبر بالمعايير الأخلاقية والقانونية من خلال خوارزميات الامتثال المتقدمة.
- التعاون بين كاشطات الذكاء الاصطناعي وتقنيات blockchain لمعاملات بيانات آمنة وشفافة.
اتصل بنا اليوم على sales@promptcloud.com لاكتشاف كيف يمكن لتقنية استخراج مواقع الويب المتطورة الخاصة بالذكاء الاصطناعي أن تُحدث ثورة في عمليات استخراج البيانات لديك وتدفع مؤسستك إلى آفاق جديدة!