
ما هي تسمية البيانات في التعلم الآلي وكيف تعمل؟
نشرت: 2022-04-29البيانات هي الثروة الجديدة لشركات اليوم. مع تولي تقنيات مثل الذكاء الاصطناعي بشكل تدريجي لمعظم أنشطتنا اليومية ، فإن الاستخدام الصحيح لأي بيانات يؤثر على المجتمع بشكل إيجابي. من خلال فصل البيانات وتصنيفها بكفاءة ، يمكن لخوارزميات ML اكتشاف المشكلات وتقديم حلول عملية وذات صلة.
بمساعدة وسم البيانات ، نقوم بتعليم الآلة تقنيات مختلفة وإدخال المعلومات بتنسيقات مختلفة حتى يتصرفوا "بذكاء". يتضمن العلم الكامن وراء تصنيف البيانات مجموعة كبيرة من الواجبات المنزلية في شكل تعليق توضيحي أو تصنيف مجموعات البيانات بأشكال متعددة من نفس المعلومات. على الرغم من أن النتيجة النهائية تفاجئ وتسهل حياتنا اليومية ، إلا أن العمل وراء ذلك هائل والتفاني جدير بالثناء.
ما هو تصنيف البيانات؟
في التعلم الآلي ، تحدد جودة ونوع بيانات الإدخال جودة ونوع المخرجات. تزيد جودة البيانات المستخدمة لتدريب الجهاز من دقة نموذج الذكاء الاصطناعي الخاص بك.
بمعنى آخر ، تسمية البيانات هي عملية لتدريب الآلة على العثور على الاختلافات والتشابهات بين مجموعات البيانات غير المهيكلة أو المنظمة عن طريق وضع العلامات عليها أو التعليق عليها.
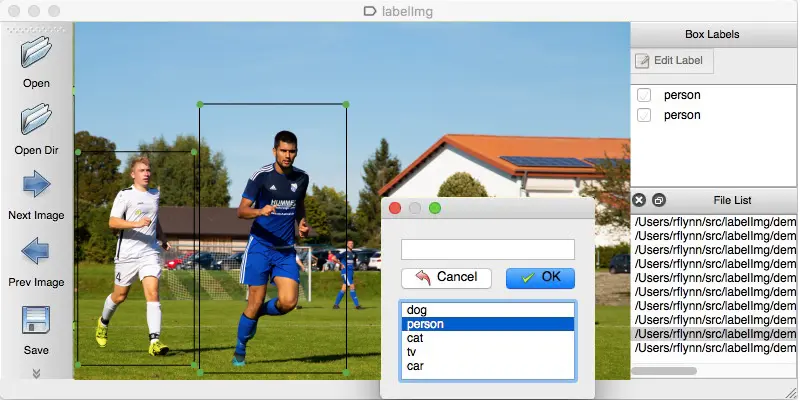
دعونا نفهم هذا بمثال. لتدريب الجهاز على أن الضوء الأحمر هو علامة التوقف ، يجب عليك وضع علامة على جميع الأضواء الحمراء في صور مختلفة حتى يتمكن الجهاز من فهم الإشارة. بناءً على ذلك ، ينشئ الذكاء الاصطناعي خوارزمية تقرأ الضوء الأحمر كإشارة توقف في كل سيناريو محدد. مثال آخر هو أنه يمكن فصل أنواع الموسيقى مع مجموعات بيانات متعددة تحت تسميات الجاز والبوب والروك والكلاسيكية والمزيد.
التحديات في وسم البيانات
أي تغييرات / تطورات جديدة في التكنولوجيا أو الهيكل تجلب فوائدها وتحدياتها. لا يختلف عن تسمية البيانات. بينما يمكن أن يؤدي تصنيف البيانات إلى تقليل وقت توسيع نطاق الأعمال بشكل كبير ، إلا أنه يأتي بتكلفة. دعونا نتناول بعض التحديات التي يجلبها تصنيف البيانات.
التكلفة من حيث الوقت والجهد
إنها مهمة صعبة في حد ذاتها للحصول على البيانات المتخصصة بكميات ضخمة. إضافة العلامات يدويًا لكل عنصر يضيف فقط إلى المهمة التي تستغرق وقتًا طويلاً بالفعل. إذا تم التعامل مع المشروع داخليًا ، فسيتم قضاء معظم وقت المشروع في المهام المتعلقة بالبيانات مثل جمع البيانات وإعدادها وتصنيفها.
لإدارة هذه المهام بشكل فعال ، حتى تحصل على العمل بشكل صحيح من أول مرة ، ستحتاج إلى واضعي ملصقات خبراء يتمتعون بهذه الخبرة المحددة. هذه أيضًا مهمة مكلفة ، مما يجعلها مكلفة ، ليس فقط من حيث الوقت ولكن أيضًا من حيث المال.
تناقض
قد يكون للمعلقين من ذوي الخبرات المختلفة معايير مختلفة لوضع العلامات. وبالتالي ، هناك احتمال كبير لوضع علامات غير متسقة. بعد قولي هذا ، عندما يقوم العديد من الأشخاص بتسمية نفس مجموعة البيانات ، فإن معدلات دقة البيانات ستكون أعلى من ذلك بكثير.
الخبرة نطاق
بالنسبة إلى صناعات محددة ، ستشعر بالحاجة إلى توظيف مصممين ذوي خبرة في مجال معين. على سبيل المثال ، لإنشاء تطبيق ML لصناعة الرعاية الصحية ، سيجد المعلقون الذين ليس لديهم خبرة في المجال ذات الصلة صعوبة كبيرة في تمييز العناصر بشكل صحيح.
عيوب
أي عمل متكرر يقوم به البشر عرضة للأخطاء. مهما كان مستوى الخبرة الذي قد يمتلكه المصمم البشري ، فإن وضع العلامات اليدوي سيكون دائمًا في نطاق النقص. ضمان عدم وجود أخطاء هو أقرب إلى المستحيل حيث يتعين على المعلقين التعامل مع مجموعات كبيرة من البيانات الأولية لوضع العلامات.
مناهج وسم البيانات
كما هو مذكور أعلاه ، يعد تصنيف البيانات مهمة تستغرق وقتًا طويلاً وتتطلب عينًا للحصول على التفاصيل. بناءً على بيان المشكلة ، ستختلف كمية البيانات التي سيتم تمييزها ، وتعقيد البيانات ، والأسلوب ، والاستراتيجية المطبقة على البيانات التوضيحية.
دعنا نراجع الأساليب المختلفة التي يمكن لشركتك أن تختارها بناءً على الموارد المالية والوقت المتاح.
تصنيف البيانات الداخلية
استنادًا إلى نوع الصناعة ، والوقت المتاح لإكمال مشروع الذكاء الاصطناعي المحدد ، وتوافر الموارد المطلوبة ، يمكن إجراء عملية تسمية البيانات داخليًا بواسطة المؤسسات.
الايجابيات:
- دقة عالية
- جودة عالية
- تتبع مبسط
سلبيات:
- مستهلك للوقت / بطيء
- تتطلب موارد كبيرة
التعهيد الجماعي
تتوفر مجموعات بيانات الاستعانة بالمصادر التي تم تصنيفها من قبل المستقلين على منصات التعهيد الجماعي المختلفة. يمكن استخدام هذه الطريقة للتعليق على البيانات المعممة مثل الصور.
أشهر مثال على تصنيف البيانات من خلال التعهيد الجماعي هو Recaptcha. يُطلب من المستخدم تحديد أنواع معينة من الصور لإثبات أنهم بشر. يتم التحقق منها بناءً على المدخلات المقدمة من المستخدمين الآخرين. يعمل هذا كقاعدة بيانات للتسميات لمجموعة من الصور.
الايجابيات:
- سريع وسهل
- فعاله من حيث التكلفه
سلبيات:
- لا يمكن استخدامها للبيانات التي تتطلب خبرة في المجال
- الجودة ليست مضمونة
الاستعانة بمصادر خارجية
يمكن أن تكون الاستعانة بمصادر خارجية بمثابة منتصف الطريق بين تسمية البيانات الداخلية والتعهيد الجماعي. يمكن أن يساعد الاستعانة بمنظمات خارجية أو أفراد يتمتعون بخبرة في المجال المؤسسات في جميع المشاريع - طويلة الأجل وقصيرة الأجل.
الايجابيات:
- مثالي للمشاريع المؤقتة عالية المستوى
- توفر شركات الاستعانة بمصادر خارجية تابعة لجهات خارجية موظفين تم فحصهم
- يوفر كلاً من أدوات وسم البيانات المبنية مسبقًا والمخصصة وفقًا لاحتياجات عملك
- يمكن الحصول على خيار خبراء تصنيف البيانات المتخصصة
سلبيات:
- يمكن أن تستغرق إدارة الطرف الثالث وقتًا طويلاً
قائم على الآلة
يعد التعليق التوضيحي المستند إلى الآلة أحد أحدث أشكال وضع العلامات على البيانات والتعليقات التوضيحية المستخدمة على نطاق واسع والمقبولة من قبل الصناعات. تعمل أتمتة عملية وضع العلامات على البيانات بمساعدة برنامج وضع العلامات على البيانات ، على تقليل التدخل البشري وزيادة السرعة التي يمكن بها وضع العلامات. باستخدام تقنية تسمى التعلم النشط ، يمكن تمييز البيانات بناءً على العلامات التي يمكن إضافتها إلى مجموعات بيانات التدريب تلقائيًا.
الايجابيات:
- معالجة البيانات ووضع العلامات بشكل أسرع
- ينطوي على تدخل بشري أقل
سلبيات:
- على الرغم من الجودة الأفضل ولكن لا تتساوى مع العلامات البشرية
- في حالة وجود أخطاء ، لا يزال التدخل البشري مطلوبًا

كيف يعمل تصنيف البيانات؟
بناءً على احتياجات عملك ، يمكنك اختيار الطريقة التي تناسب متطلباتك بشكل أفضل. ومع ذلك ، فإن عملية وسم البيانات تعمل بالترتيب التالي ترتيبًا زمنيًا.
جمع البيانات
قاعدة أي مشروع للتعلم الآلي هي البيانات. يشتمل جمع المقدار الصحيح من البيانات الأولية بتنسيقات مختلفة على الخطوة الأولى في تصنيف البيانات. يمكن أن يكون جمع البيانات من شكلين - أحدهما قامت الشركة بجمعه داخليًا ، والآخر يتم جمعه من مصادر خارجية متاحة للجمهور.
نظرًا لكون هذه البيانات في النموذج الأولي ، فإنها تتطلب التنظيف والمعالجة قبل إنشاء ملصقات لمجموعات البيانات. ثم يتم تغذية هذه البيانات التي تم تنظيفها ومعالجتها مسبقًا إلى النموذج للتدريب. كلما كانت البيانات أكبر وأكثر تنوعًا ، كانت النتائج أكثر دقة.

شرح البيانات
بمجرد تنظيف البيانات ، يتصفح خبراء المجال البيانات ويضيفون تسميات باتباع أساليب وسم البيانات المختلفة. يتم إرفاق السياق الهادف بالنموذج الذي يمكن استخدامه كحقيقة أساسية . هذه هي المتغيرات المستهدفة مثل الصور التي تريد أن يتنبأ بها النموذج.
تاكيد الجودة
يعتمد نجاح تدريب نموذج ML بشكل كبير على جودة البيانات التي يجب أن تكون موثوقة ودقيقة ومتسقة. لضمان دقة وسمات البيانات هذه ، يجب إجراء فحوصات منتظمة لضمان الجودة. باستخدام خوارزميات ضمان الجودة مثل اختبار التوافق واختبار كرونباخ ألفا ، يمكن تحديد دقة هذه التعليقات التوضيحية. تساهم فحوصات ضمان الجودة المنتظمة بشكل كبير في دقة النتائج.
تدريب النموذج والاختبار
لا يكون تنفيذ جميع الخطوات المذكورة أعلاه منطقيًا إلا إذا تم اختبار البيانات للتأكد من دقتها. إدخال مجموعة البيانات غير المهيكلة لمعرفة ما إذا كانت تقدم النتائج المتوقعة سيختبر العملية.
حالات الاستخدام الصناعية لوصف البيانات
الآن بعد أن أصبحنا على دراية بمفهوم تصنيف البيانات وكيف يعمل ، فلنراجع حالات الاستخدام الأكثر بروزًا.
الرؤية الحاسوبية (CV)
هذه مجموعة فرعية من الذكاء الاصطناعي تمكّن الآلات من استنباط تفسير ذي مغزى من المدخلات المقدمة في شكل مرئيات ومقاطع فيديو (الصور الثابتة المستخرجة من أجل وضع العلامات).
يمكن استخدام شرح الرؤية الحاسوبية في مختلف الصناعات لتنفيذ الفوائد العملية للذكاء الاصطناعي.
- في صناعة السيارات ، فإن وضع العلامات على الصور ومقاطع الفيديو لتقسيم الطرق والمباني والمشاة والأشياء الأخرى سيساعد المركبات المستقلة على التمييز بين هذه الكيانات لتجنب الاتصال في الحياة الواقعية.
- في صناعة الرعاية الصحية ، يمكن تقسيم أعراض المرض إلى شرائح في الأشعة السينية والتصوير بالرنين المغناطيسي والأشعة المقطعية. بمساعدة الصور المجهرية ، يمكن تشخيص معظم الأمراض الحرجة في مرحلة مبكرة.
- يمكن استخدام أكواد QR ، والباركود الملصق ، وما إلى ذلك كتسميات في صناعة النقل واللوجستيات لتتبع البضائع.
معالجة اللغة الطبيعية (NLP)
هذه مجموعة فرعية تمكن آلات الذكاء الاصطناعي من تفسير لغة الإنسان والإحصاءات. اشتقاق المعنى من النص والكلام ، يمكن للخوارزمية تحليل الجوانب اللغوية المختلفة.
يستخدم البرمجة اللغوية العصبية بشكل متزايد في العديد من حلول المؤسسات .
- يتم استخدامه بشكل شائع في جميع الصناعات كمساعد للبريد الإلكتروني ، وميزة الإكمال التلقائي ، والمدقق الإملائي ، وفصل البريد الإلكتروني العشوائي ورسائل البريد الإلكتروني غير العشوائية ، وأكثر من ذلك بكثير.
- في شكل روبوتات المحادثة ، يتم تفسير الاستفسارات الأساسية التي يطرحها العملاء والإجابة عليها دون تدخل بشري في الوقت الفعلي. من المتوقع أن تتم إدارة 70٪ من تفاعلات العملاء بواسطة روبوتات المحادثة وتطبيقات الرسائل المحمولة بحلول عام 2023.
- يتم فهم القطبية السلبية والإيجابية للنص لالتقاط معنويات العملاء من خلال وضع العلامات على البيانات في التجارة الإلكترونية.
نجحت شركة Appinventiv في بناء تطبيق وسائط اجتماعية لـ Vyrb والذي يمكّن المستخدمين من إرسال واستقبال الرسائل الصوتية المحسّنة لأجهزة Bluetooth القابلة للارتداء.

نظرة عامة على سوق وسم بيانات الذكاء الاصطناعي
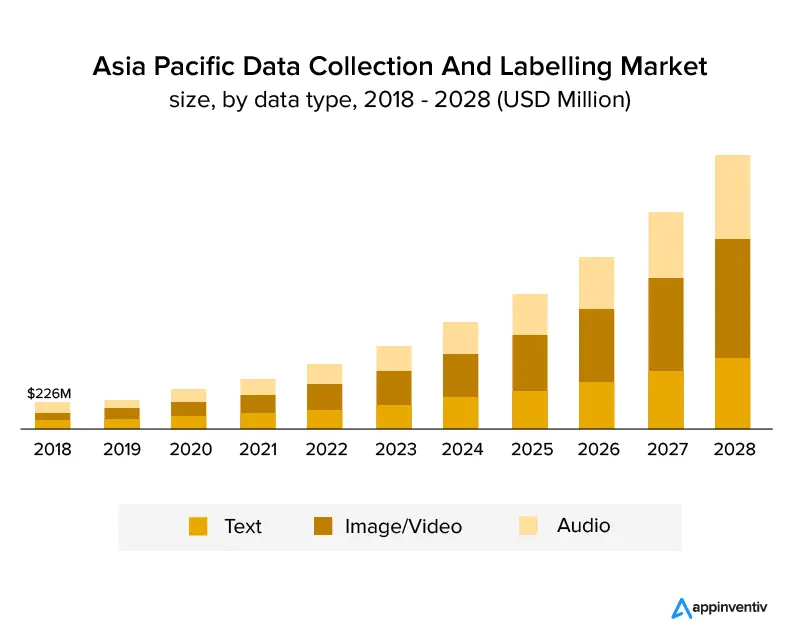
يعد وضع العلامات على البيانات صناعة مزدهرة ولدت من تكنولوجيا الذكاء الاصطناعي . نظرًا لأن تصنيف البيانات يعتمد إلى حد كبير على البيانات الدقيقة التي يتم تغذيتها للتعلم الآلي ، فمن المحتم أن تنمو في السنوات القليلة المقبلة.
يوضح الرسم البياني أدناه بوضوح أن الصناعة قد نمت وستستمر في النمو في السنوات القادمة. من المتوقع أن ينمو بمعدل نمو سنوي مركب بنسبة 25.6٪ ويصل إلى حجم سوق يبلغ 8.22 مليار دولار أمريكي بحلول عام 2028. ويظهر الرسم البياني أدناه النمو حسب نوع البيانات.
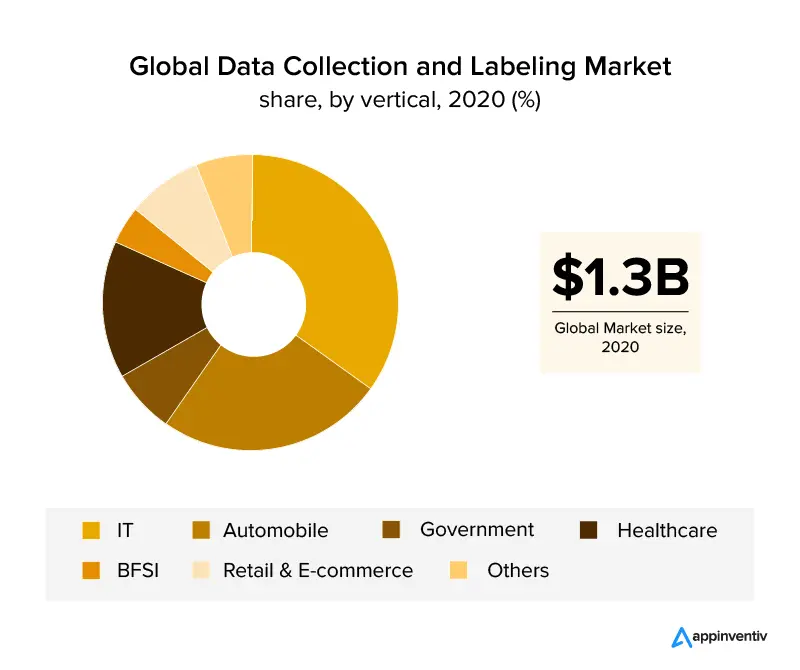
نظرة عامة على قطاعات الأعمال التي استغلت تصنيف البيانات هي قطاعي تكنولوجيا المعلومات والسيارات ، والتي تغطي أكثر من 30٪ من الإيرادات العالمية. مع نمو صناعة الرعاية الصحية ، من المتوقع أن تزدهر تسمية البيانات بسبب متطلبات البيانات الدقيقة للتطبيقات الفعالة القائمة على الذكاء الاصطناعي في هذا القطاع. بمساعدة وضع العلامات على الصور ، حصلت صناعات البيع بالتجزئة والتجارة الإلكترونية أيضًا على حصة سوقية كبيرة في صناعة ملصقات البيانات.
بيانات التسمية باستخدام Appinventiv
من الناحية الإستراتيجية ، تقوم الشركات بالاستعانة بمصادر خارجية لخدمات جمع البيانات ووضع العلامات لبناء نماذج قوية للتعلم الآلي.
Appinventiv هي شركة تطوير الذكاء الاصطناعي والتعلم الآلي والتي تساعد المؤسسات على فتح الفرص من خلال الحلول القائمة على الذكاء الاصطناعي لسنوات عديدة حتى الآن . مع ما يقرب من عقد من الخبرة في تحويل الأعمال التجارية ، نجحنا في تنفيذ العديد من مشاريع الذكاء الاصطناعي المعقدة لمختلف الصناعات.
على سبيل المثال ، نجحت شركة Appinventiv في أتمتة العملية المصرفية لأحد البنوك الرائدة في أوروبا. ساعدت عملية الأتمتة البنك في تحسين الدقة بنسبة 50٪ ومستويات خدمة الصراف الآلي بنسبة 92٪.
مثال آخر حيث ساعد Appinventiv YouCOMM في بناء حل ثوري لتحويل التواصل مع المريض داخل المستشفى من خلال توفير الوصول في الوقت الفعلي إلى المساعدة الطبية. من خلال نظام رسائل المريض القابل للتخصيص ، يمكن للمرضى إخطار الموظفين بسهولة باحتياجاتهم من خلال الأوامر الصوتية واستخدام إيماءات الرأس.
من خلال خبرتنا وفريقنا الذي يركز على العملاء ، نقدم خدمات تصنيف البيانات التي ستساعدك على التغلب على التحديات التي توفر لك خدمات تصنيف البيانات الشاملة بناءً على احتياجاتك ومتطلباتك الخاصة.
من خلال الاستفادة من المجموعة الواسعة من الأدوات اللازمة لوضع العلامات والتعليقات التوضيحية على البيانات ، يمكن لـ Appinventiv تحسين عمليات تدريب البيانات لتبسيط النماذج المعقدة. يتيح لنا ذلك التفوق في الأداء من حيث دقة التجزئة والتصنيف ومن ثم تصنيف البيانات التي ستكون سريعة وسهلة.
تغليف!
"قوة الذكاء الاصطناعي مذهلة للغاية ، وسوف تغير المجتمع في بعض النواحي العميقة للغاية." - بيل جيتس
الذكاء الاصطناعي لديه القدرة على جعل حياة الإنسان أسهل وبالتالي عمل الخير للمجتمع. وقد ساعدت قدرتها على فرز كميات ضخمة من البيانات في تعليمات مفيدة بمساعدة تصنيف البيانات على مساعدة الصناعات على التقدم والنمو على قدم وساق.
التعليمات
س: ما هي أفضل الممارسات لإتقان تسمية البيانات؟
أ. بناءً على النهج الذي تتبعه لتصنيف البيانات ، هناك بعض أفضل الممارسات التي يمكنك اتباعها:
- تأكد من أن البيانات التي تم جمعها كافية ومنقحة ومعالجة بشكل صحيح.
- بناءً على الصناعة ، قم بتعيين الوظيفة لمصنعي بيانات خبراء المجال فقط.
- تأكد من اتباع الفريق لنهج موحد من خلال تزويدهم بمعايير تقنيات التعليقات التوضيحية التي يجب اتباعها.
- اتبع عملية صانع المدقق عن طريق تعيين العديد من المعلقين التوضيحيين لوضع العلامات المتقاطعة.
س: ما هي فوائد وسم البيانات؟
يساعد تصنيف البيانات في توفير وضوح أفضل للسياق والجودة وسهولة الاستخدام لعمل تنبؤ دقيق للبيانات. وهذا بدوره يساعد في تحسين إمكانية استخدام البيانات للمتغيرات في النموذج.
س: ما هي العناصر المختلفة التي يجب مراعاتها أثناء وضع قائمة مختصرة لشركات تصنيف البيانات؟
ج: هناك خمسة معلمات يجب مراعاتها عند اختيار خدمات تسمية البيانات للتعلم الآلي.
- قابلية التوسع في عملية وسم البيانات
- تكلفة خدمة لصق البيانات
- أمن البيانات
- منصة وسم البيانات