
ما هو ملف robots.txt في مُحسّنات محرّكات البحث: كيفية إنشائه وتحسينه
نشرت: 2022-04-22موضوع اليوم ليس له علاقة مباشرة بتحقيق الدخل من حركة المرور. ولكن يمكن أن يؤثر ملف robots.txt على مُحسّنات محرّكات البحث لموقعك على الويب ، وفي النهاية على مقدار حركة المرور التي يتلقاها. لقد دمر العديد من مسؤولي الويب تصنيفات مواقع الويب الخاصة بهم بسبب إدخالات robots.txt الفاشلة. سيساعدك هذا الدليل على تجنب كل تلك المزالق. تأكد من القراءة حتى النهاية!
- ما هو ملف robots.txt؟
- كيف يبدو ملف robots.txt؟
- كيف تجد ملف robots.txt الخاص بك
- كيف يعمل ملف Robots.txt؟
- بنية ملف robots.txt
- التوجيهات المعتمدة
- وكيل المستخدم*
- السماح
- عدم السماح
- خريطة الموقع
- توجيهات غير مدعومة
- تأخير الزحف
- Noindex
- لا اتباع
- هل تحتاج إلى ملف robots.txt؟
- إنشاء ملف robots.txt
- ملف Robots.txt: أفضل ممارسات تحسين محركات البحث
- استخدم سطرًا جديدًا لكل توجيه
- استخدم أحرف البدل لتبسيط التعليمات
- استخدم علامة الدولار “$” لتحديد نهاية عنوان URL
- استخدم كل وكيل مستخدم مرة واحدة فقط
- استخدم تعليمات محددة لتجنب الأخطاء غير المقصودة
- أدخل التعليقات في ملف robots.txt مع التجزئة
- استخدم ملفات robots.txt مختلفة لكل مجال فرعي
- لا تحجب المحتوى الجيد
- لا تفرط في استخدام تأخير الزحف
- انتبه لحساسية حالة الأحرف
- أفضل الممارسات الأخرى:
- استخدام ملف robots.txt لمنع فهرسة المحتوى
- استخدام ملف robots.txt لحماية المحتوى الخاص
- استخدام ملف robots.txt لإخفاء المحتوى الضار المكرر
- كل الوصول لجميع الروبوتات
- لا يوجد وصول لجميع الروبوتات
- منع دليل فرعي واحد لجميع برامج الروبوت
- حظر دليل فرعي واحد لجميع الروبوتات (مع وجود ملف واحد مسموح به)
- حظر ملف واحد لجميع الروبوتات
- حظر نوع ملف واحد (PDF) لجميع الروبوتات
- منع جميع عناوين URL ذات المعلمات لبرنامج Googlebot فقط
- كيفية اختبار ملف robots.txt بحثًا عن أخطاء
- تم حظر عنوان URL الذي تم إرساله بواسطة ملف robots.txt
- تم الحظر بواسطة ملف robots.txt
- مفهرس ، على الرغم من حظره بواسطة ملف robots.txt
- Robots.txt مقابل meta robots مقابل x-robots
- قراءة متعمقة
- تغليف
ما هو ملف robots.txt؟
يعد ملف robots.txt ، أو بروتوكول استبعاد الروبوت ، مجموعة من معايير الويب التي تتحكم في كيفية قيام روبوتات محرك البحث بالزحف إلى كل صفحة ويب ، وصولاً إلى ترميز المخطط في تلك الصفحة. إنه ملف نصي قياسي يمكنه حتى منع برامج زحف الويب من الوصول إلى موقع الويب بالكامل أو أجزاء منه.
أثناء ضبط تحسين محركات البحث وحل المشكلات الفنية ، يمكنك البدء في الحصول على دخل سلبي من الإعلانات. سطر واحد من التعليمات البرمجية على موقع الويب الخاص بك يعيد دفعات منتظمة!
إلى المحتويات ↑كيف يبدو ملف robots.txt؟
التركيب اللغوي بسيط: أنت تعطي قواعد للروبوتات من خلال تحديد وكيل المستخدم والتوجيهات. يحتوي الملف على التنسيق الأساسي التالي:
خريطة الموقع: [موقع URL لملف sitemap]
وكيل المستخدم: [bot identifier]
[التوجيه 1]
[التوجيه 2]
[توجيه ...]
وكيل المستخدم: [معرّف روبوت آخر]
[التوجيه 1]
[التوجيه 2]
[توجيه ...]
كيف تجد ملف robots.txt الخاص بك
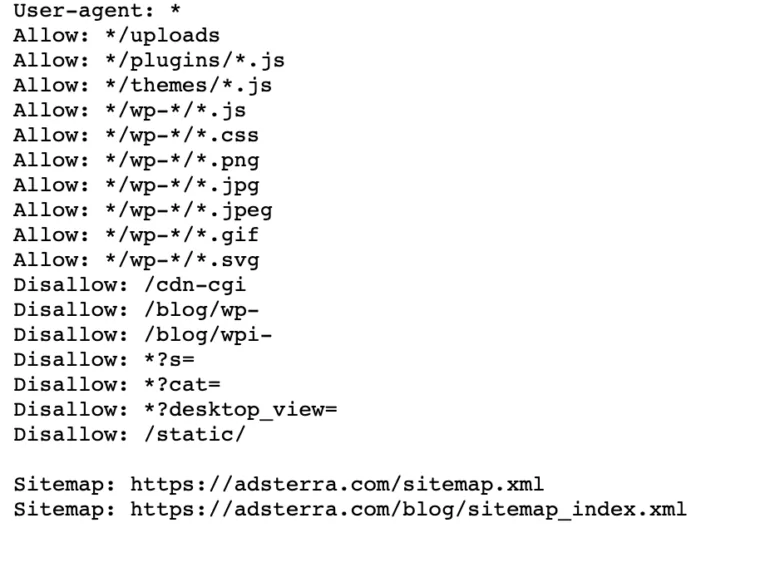
إذا كان موقع الويب الخاص بك يحتوي بالفعل على ملف robot.txt ، فيمكنك العثور عليه بالانتقال إلى عنوان URL هذا: https://yourdomainname.com/robots.txt في متصفحك. على سبيل المثال ، هذا ملفنا
كيف يعمل ملف Robots.txt؟
ملف robots.txt هو ملف نصي عادي لا يحتوي على أي كود ترميز HTML (ومن هنا يأتي الامتداد .txt). يتم تخزين هذا الملف ، مثل جميع الملفات الأخرى الموجودة على موقع الويب ، على خادم الويب. من غير المحتمل أن يزور المستخدمون هذه الصفحة لأنها غير مرتبطة بأي من صفحاتك ، ولكن معظم برامج تتبع برامج تتبع الروابط على الويب تبحث عنها قبل الزحف إلى موقع الويب بأكمله.
يمكن أن يقدم ملف robots.txt تعليمات الروبوتات ولكن لا يمكنه تنفيذ هذه التعليمات. سيتحقق الروبوت الجيد ، مثل متتبع ارتباطات الويب أو روبوت موجز الأخبار ، من الملف ويتبع الإرشادات قبل زيارة أي صفحة مجال. لكن الروبوتات الخبيثة إما ستتجاهل أو تعالج الملف للعثور على صفحات الويب المحظورة.
في حالة احتواء ملف robots.txt على أوامر متعارضة ، سيستخدم الروبوت مجموعة التعليمات الأكثر تحديدًا.
إلى المحتويات ↑بنية ملف robots.txt
يتكون ملف robots.txt من عدة أقسام من "التوجيهات" ، يبدأ كل منها بوكيل مستخدم. يحدد وكيل المستخدم روبوت الزحف الذي يتواصل معه الرمز. يمكنك إما معالجة جميع محركات البحث في وقت واحد أو إدارة محركات البحث الفردية.
عندما يزحف روبوت إلى موقع ويب ، فإنه يعمل على أجزاء الموقع التي تتصل به.
وكيل المستخدم: *
عدم السماح: /
وكيل المستخدم: Googlebot
عدم السماح:
وكيل المستخدم: Bingbot
Disallow: / not-for-bing /
التوجيهات المعتمدة
التوجيهات هي إرشادات تريد من وكلاء المستخدم الذين تصرّح باتباعها. تدعم Google حاليًا التوجيهات التالية.
وكيل المستخدم*
عندما يتصل أحد البرامج بخادم ويب (روبوت أو متصفح ويب عادي) ، فإنه يرسل عنوان HTTP يسمى "وكيل المستخدم" يحتوي على معلومات أساسية حول هويته. لكل محرك بحث وكيل مستخدم. تُعرف روبوتات Google باسم Googlebot و Yahoo - باسم Slurp و Bing's - باسم BingBot. يبدأ وكيل المستخدم سلسلة من التوجيهات ، والتي يمكن أن تنطبق على وكلاء مستخدم معينين أو جميع وكلاء المستخدم.
السماح
يخبر التوجيه allow محركات البحث بالزحف إلى صفحة أو دليل فرعي ، حتى إلى دليل مقيد. على سبيل المثال ، إذا كنت تريد ألا تتمكن محركات البحث من الوصول إلى جميع منشورات مدونتك باستثناء واحدة ، فقد يبدو ملف robots.txt الخاص بك كما يلي:
وكيل المستخدم: *
Disallow: / blog
السماح: / blog / allowed-post
ومع ذلك ، يمكن لمحركات البحث الوصول إلى / blog / allowed-post لكن لا يمكنهم الوصول إلى:
/ بلوق / وظيفة أخرى
/ بلوق / بعد آخر-وظيفة
/blog/download-me.pd
عدم السماح
أمر عدم السماح (الذي يضاف إلى ملف robots.txt الخاص بموقع الويب) يخبر محركات البحث بعدم الزحف إلى صفحة معينة. في معظم الحالات ، سيمنع هذا أيضًا الصفحة من الظهور في نتائج البحث.
يمكنك استخدام هذا التوجيه لإرشاد محركات البحث إلى عدم الزحف إلى الملفات والصفحات الموجودة في مجلد معين تخفيه عن عامة الناس. على سبيل المثال ، المحتوى الذي لا تزال تعمل عليه ولكن تم نشره عن طريق الخطأ. قد يبدو ملف robots.txt الخاص بك بهذا الشكل إذا كنت تريد منع جميع محركات البحث من الوصول إلى مدونتك:
وكيل المستخدم: *
Disallow: / blog
هذا يعني أنه لن يتم أيضًا الزحف إلى جميع الأدلة الفرعية في دليل / blog. سيؤدي هذا أيضًا إلى منع Google من الوصول إلى عناوين URL التي تحتوي على / blog.
إلى المحتويات ↑خريطة الموقع
خرائط المواقع هي قائمة بالصفحات التي تريد أن تقوم محركات البحث بالزحف إليها وفهرستها. إذا كنت تستخدم توجيه خريطة الموقع ، فستعرف محركات البحث موقع خريطة موقع XML الخاصة بك. الخيار الأفضل هو إرسالها إلى أدوات مشرفي المواقع لمحركات البحث لأن كل منها يمكن أن يوفر معلومات قيمة حول موقع الويب الخاص بك للزوار.
من المهم ملاحظة أن تكرار توجيه خريطة الموقع لكل وكيل مستخدم غير ضروري ، ولا ينطبق على وكيل بحث واحد. أضف توجيهات ملف Sitemap في بداية ملف robots.txt أو نهايته.
مثال على توجيه خريطة الموقع في الملف:
خريطة الموقع: https://www.domain.com/sitemap.xml
وكيل المستخدم: Googlebot
Disallow: / blog /
السماح: / blog / post-title /
وكيل المستخدم: Bingbot
عدم السماح: / خدمات /
إلى المحتويات ↑توجيهات غير مدعومة
فيما يلي التوجيهات التي لم تعد Google تدعمها - وبعضها لم يتم اعتماده من الناحية الفنية.
تأخير الزحف
تستجيب Yahoo و Bing و Yandex بسرعة لفهرسة مواقع الويب وتتفاعل مع توجيه تأخير الزحف ، مما يبقيهم تحت المراقبة لبعض الوقت.
قم بتطبيق هذا الخط على كتلتك:
وكيل المستخدم: Bingbot
تأخير الزحف: 10
هذا يعني أنه يمكن لمحركات البحث الانتظار لمدة عشر ثوانٍ قبل الزحف إلى موقع الويب أو عشر ثوانٍ قبل إعادة الوصول إلى موقع الويب بعد الزحف ، وهو نفس الشيء ولكنه يختلف قليلاً اعتمادًا على وكيل المستخدم المستخدم.
Noindex
تعد علامة noindex الوصفية طريقة رائعة لمنع محركات البحث من فهرسة إحدى صفحاتك. تسمح العلامة للروبوتات بالوصول إلى صفحات الويب ، لكنها تخبر الروبوتات أيضًا بعدم فهرستها.
- رأس استجابة HTTP بعلامة noindex. يمكنك تنفيذ هذه العلامة بطريقتين: رأس استجابة HTTP بعلامة X-Robots-Tag أو علامة <meta> موضوعة في قسم <head>. هكذا يجب أن تبدو علامة <meta> الخاصة بك:
<meta name = ”robots” content = ”noindex”>
- رمز حالة HTTP 404 و 410. تشير رموز الحالة 404 و 410 إلى أن الصفحة لم تعد متوفرة. بعد الزحف إلى صفحات 404/410 ومعالجتها ، يتم إزالتها تلقائيًا من فهرس Google. لتقليل مخاطر صفحات الخطأ 404 و 410 ، قم بالزحف إلى موقع الويب الخاص بك بانتظام واستخدم عمليات إعادة التوجيه 301 لتوجيه حركة المرور إلى صفحة موجودة عند الضرورة.
لا اتباع
يوجه Nofollow محركات البحث إلى عدم اتباع الروابط الموجودة على الصفحات والملفات الموجودة ضمن مسار معين. منذ 1 مارس 2020 ، لم تعد Google تعتبر سمات nofollow كإرشادات. بدلاً من ذلك ، ستكون تلميحات ، مثل العلامات الأساسية. إذا كنت تريد السمة "nofollow" لجميع الروابط الموجودة على الصفحة ، فاستخدم العلامة الوصفية للروبوت ، أو رأس x-robots ، أو سمة الرابط rel = "nofollow" .
في السابق كان بإمكانك استخدام التوجيه التالي لمنع Google من تتبع جميع الروابط الموجودة في مدونتك:
وكيل المستخدم: Googlebot
Nofollow: / مدونة /
هل تحتاج إلى ملف robots.txt؟
العديد من المواقع الأقل تعقيدًا لا تحتاج إلى واحد. بينما لا يقوم محرك بحث Google عادةً بفهرسة صفحات الويب المحظورة بواسطة ملف robots.txt ، إلا أنه لا توجد طريقة لضمان عدم ظهور هذه الصفحات في نتائج البحث. يمنحك وجود هذا الملف مزيدًا من التحكم والأمان في المحتوى على موقع الويب الخاص بك عبر محركات البحث.

تساعدك ملفات الروبوتات أيضًا على إنجاز ما يلي:
- منع الزحف إلى المحتوى المكرر.
- الحفاظ على الخصوصية لأقسام الموقع المختلفة.
- تقييد الزحف إلى نتائج البحث الداخلية.
- منع التحميل الزائد للخادم.
- منع هدر "ميزانية الزحف".
- احتفظ بالصور ومقاطع الفيديو وملفات الموارد بعيدًا عن نتائج بحث Google.
تؤثر هذه الإجراءات في النهاية على تكتيكات تحسين محركات البحث الخاصة بك. على سبيل المثال ، المحتوى المكرر يربك محركات البحث ويجبرها على اختيار أي من الصفحتين تحتل المرتبة الأولى. بغض النظر عمن قام بإنشاء المحتوى ، قد لا تحدد Google الصفحة الأصلية لأهم نتائج البحث.
في الحالات التي يكتشف فيها محرك بحث Google وجود محتوى مكرر يهدف إلى خداع المستخدمين أو التلاعب بالترتيب ، فسيتم تعديل فهرسة وترتيب موقع الويب الخاص بك. نتيجة لذلك ، قد يتأثر ترتيب موقعك أو تتم إزالته بالكامل من فهرس Google ، ويختفي من نتائج البحث.
يؤدي الحفاظ على الخصوصية لأقسام مواقع الويب المختلفة أيضًا إلى تحسين أمان موقع الويب وحمايته من المتسللين. على المدى الطويل ، ستجعل هذه الإجراءات موقع الويب الخاص بك أكثر أمانًا وجدارة بالثقة وربحًا.
هل أنت صاحب موقع تريد الاستفادة من حركة المرور؟ مع Adsterra ، ستحصل على دخل سلبي من أي موقع ويب!
إلى المحتويات ↑إنشاء ملف robots.txt
ستحتاج إلى محرر نصوص مثل المفكرة.
- أنشئ ورقة جديدة ، واحفظ الصفحة الفارغة باسم "robots.txt" ، وابدأ في كتابة التوجيهات في مستند .txt فارغ.
- قم بتسجيل الدخول إلى cPanel ، وانتقل إلى الدليل الجذر للموقع ، وابحث عن المجلد public_html .
- اسحب الملف إلى هذا المجلد ثم تحقق مرة أخرى من تعيين إذن الملف بشكل صحيح.
يمكنك كتابة الملف وقراءته وتحريره باعتبارك المالك ، ولكن لا يُسمح للأطراف الثالثة. يجب أن يظهر رمز الإذن "0644" في الملف. إذا لم يكن كذلك ، فانقر بزر الماوس الأيمن فوق الملف واختر "إذن الملف".
ملف Robots.txt: أفضل ممارسات تحسين محركات البحث
استخدم سطرًا جديدًا لكل توجيه
تحتاج إلى التصريح عن كل توجيه في سطر منفصل. خلاف ذلك ، سيتم الخلط بين محركات البحث.
وكيل المستخدم: *
Disallow: / دليل /
Disallow: / another-directory /
استخدم أحرف البدل لتبسيط التعليمات
يمكنك استخدام أحرف البدل (*) لجميع وكلاء المستخدم وأنماط عنوان URL المطابقة عند إعلان التوجيهات. يعمل حرف البدل جيدًا مع عناوين URL التي لها نمط موحد. على سبيل المثال ، قد ترغب في منع الزحف إلى جميع صفحات التصفية التي تحتوي على علامة استفهام (؟) في عناوين URL الخاصة بها.
وكيل المستخدم: *
عدم السماح: /*؟
استخدم علامة الدولار “$” لتحديد نهاية عنوان URL
لا يمكن لمحركات البحث الوصول إلى عناوين URL التي تنتهي بامتدادات مثل pdf. هذا يعني أنهم لن يتمكنوا من الوصول إلى /file.pdf ، لكنهم سيكونون قادرين على الوصول إلى /file.pdf؟id=68937586 ، والذي لا ينتهي بـ “.pdf”. على سبيل المثال ، إذا كنت تريد منع محركات البحث من الوصول إلى جميع ملفات PDF على موقع الويب الخاص بك ، فقد يبدو ملف robots.txt الخاص بك كما يلي:
وكيل المستخدم: *
Disallow: /*.pdf$
استخدم كل وكيل مستخدم مرة واحدة فقط
في Google ، لا يهم إذا كنت تستخدم نفس وكيل المستخدم أكثر من مرة. ستقوم ببساطة بتجميع جميع القواعد من الإعلانات المختلفة في توجيه واحد واتباعها. ومع ذلك ، فإن الإعلان عن كل وكيل مستخدم مرة واحدة فقط أمر منطقي لأنه أقل إرباكًا.
يؤدي الحفاظ على توجيهاتك مرتبة وبسيطة إلى تقليل مخاطر الأخطاء الجسيمة. على سبيل المثال ، إذا احتوى ملف robots.txt على وكلاء المستخدم والتوجيهات التالية.
وكيل المستخدم: Googlebot
عدم السماح: / أ /
وكيل المستخدم: Googlebot
عدم السماح: / ب /
استخدم تعليمات محددة لتجنب الأخطاء غير المقصودة
عند تعيين التوجيهات ، يمكن أن يؤدي الفشل في تقديم إرشادات محددة إلى حدوث أخطاء يمكن أن تضر تحسين محركات البحث لديك. افترض أن لديك موقعًا متعدد اللغات وتعمل على إصدار ألماني للمجلد الفرعي / de /.
لا تريد أن تتمكن محركات البحث من الوصول إليه لأنه ليس جاهزًا بعد. سيمنع ملف robots.txt التالي محركات البحث من فهرسة هذا المجلد الفرعي ومحتوياته:
وكيل المستخدم: *
عدم السماح: / de
ومع ذلك ، فإنه سيقيد محركات البحث من الزحف إلى أي صفحات أو ملفات تبدأ بـ / de. في هذه الحالة ، فإن إضافة شرطة مائلة هو الحل البسيط.
وكيل المستخدم: *
عدم السماح: / de /
إلى المحتويات ↑أدخل التعليقات في ملف robots.txt مع التجزئة
تساعد التعليقات المطورين وربما أنت أيضًا على فهم ملف robots.txt الخاص بك. ابدأ السطر بعلامة التجزئة (#) لتضمين تعليق. تتجاهل الزواحف الأسطر التي تبدأ بعلامة تجزئة.
# هذا يوجه Bing bot إلى عدم الزحف إلى موقعنا.
وكيل المستخدم: Bingbot
عدم السماح: /
استخدم ملفات robots.txt مختلفة لكل مجال فرعي
لا يؤثر ملف robots.txt إلا في الزحف على نطاقه المضيف. ستحتاج إلى ملف آخر لتقييد الزحف على نطاق فرعي مختلف. على سبيل المثال ، إذا كنت تستضيف موقع الويب الرئيسي الخاص بك على example.com ومدونتك على blog.example.com ، فستحتاج إلى ملفي robots.txt. ضع واحدًا في الدليل الجذر للنطاق الرئيسي ، بينما يجب أن يكون الملف الآخر في الدليل الجذر للمدونة.
لا تحجب المحتوى الجيد
لا تستخدم ملف robots.txt أو علامة noindex لمنع أي محتوى عالي الجودة تريد جعله عامًا لتجنب الآثار السلبية على نتائج تحسين محركات البحث. تحقق بدقة من علامات noindex وعدم السماح بالقواعد على صفحاتك.
لا تفرط في استخدام تأخير الزحف
لقد أوضحنا تأخير الزحف ، لكن لا يجب عليك استخدامه بشكل متكرر لأنه يحد من الزحف إلى كل الصفحات. قد تعمل مع بعض مواقع الويب ، ولكن قد تضر بترتيبك وحركة المرور إذا كان لديك موقع ويب كبير.
انتبه لحساسية حالة الأحرف
يعتبر ملف Robots.txt حساسًا لحالة الأحرف ، لذلك تحتاج إلى التأكد من إنشاء ملف robots بالتنسيق الصحيح. يجب تسمية ملف الروبوتات "robots.txt" بجميع الأحرف الصغيرة. عدا ذلك ، لن ينجح الأمر.
أفضل الممارسات الأخرى:
- تأكد من أنك لا تحظر محتوى أو أقسام موقع الويب الخاص بك من الزحف.
- لا تستخدم ملف robots.txt لإبقاء البيانات الحساسة (معلومات المستخدم الخاصة) خارج نتائج SERP. استخدم طريقة مختلفة ، مثل تشفير البيانات أو التوجيه الوصفي noindex ، لتقييد الوصول إذا كانت الصفحات الأخرى مرتبطة مباشرةً بالصفحة الخاصة.
- تحتوي بعض محركات البحث على أكثر من وكيل مستخدم واحد. يستخدم Google ، على سبيل المثال ، Googlebot لعمليات البحث المجانية و Googlebot-Image للصور. لا يعد تحديد التوجيهات لبرامج الزحف المتعددة لكل محرك بحث أمرًا ضروريًا لأن معظم وكلاء المستخدم من نفس محرك البحث يتبعون القواعد نفسها.
- يقوم محرك البحث بتخزين محتويات ملف robots.txt مؤقتًا ولكنه يقوم بتحديثها يوميًا. إذا قمت بتغيير الملف وأردت تحديثه بشكل أسرع ، يمكنك إرسال عنوان URL للملف إلى Google.
استخدام ملف robots.txt لمنع فهرسة المحتوى
يعد تعطيل الصفحة الطريقة الأكثر فاعلية لمنع برامج التتبع من الزحف إليها مباشرة. ومع ذلك ، لن يعمل في المواقف التالية:
- إذا كان هناك مصدر آخر يحتوي على روابط للصفحة ، فستستمر برامج الروبوت في الزحف إليها وفهرستها.
- ستستمر برامج التتبع غير الشرعية في الزحف إلى المحتوى وفهرسته.
استخدام ملف robots.txt لحماية المحتوى الخاص
لا يزال من الممكن فهرسة بعض المحتويات الخاصة ، مثل ملفات PDF أو صفحات الشكر ، حتى إذا قمت بحظر الروبوتات. يعد وضع جميع صفحاتك الحصرية خلف معلومات تسجيل دخول أحد أفضل الطرق لتقوية توجيه عدم السماح. سيظل المحتوى الخاص بك متاحًا ، لكن زوار موقعك سوف يتخذون خطوة إضافية للوصول إليه.
استخدام ملف robots.txt لإخفاء المحتوى الضار المكرر
المحتوى المكرر إما متطابق أو مشابه جدًا لمحتوى آخر باللغة نفسها. يحاول Google فهرسة الصفحات ذات المحتوى الفريد وإظهارها. على سبيل المثال ، إذا كان موقعك يحتوي على إصدارات "عادية" و "طابعة" من كل مقالة ولا تحظر علامة noindex أيًا منهما ، فسيتم إدراج أحدهما.
أمثلة على ملفات robots.txt
فيما يلي بعض نماذج ملفات robots.txt. هذه للأفكار بشكل أساسي ، ولكن إذا كان أحدها يلبي احتياجاتك ، فانسخه والصقه في مستند نصي ، واحفظه باسم "robots.txt" ، ثم قم بتحميله إلى الدليل المناسب.
كل الوصول لجميع الروبوتات
هناك عدة طرق لإخبار محركات البحث بالوصول إلى جميع الملفات ، بما في ذلك وجود ملف robots.txt فارغ أو عدم وجوده.
وكيل المستخدم: *
عدم السماح:
لا يوجد وصول لجميع الروبوتات
يوجه ملف robots.txt التالي جميع محركات البحث لتجنب الوصول إلى الموقع بأكمله:
وكيل المستخدم: *
عدم السماح: /
منع دليل فرعي واحد لجميع برامج الروبوت
وكيل المستخدم: *
Disallow: / مجلد /
حظر دليل فرعي واحد لجميع الروبوتات (مع وجود ملف واحد مسموح به)
وكيل المستخدم: *
Disallow: / مجلد /
السماح: /folder/page.html
حظر ملف واحد لجميع الروبوتات
وكيل المستخدم: *
Disallow: /this-is-a-file.pdf
حظر نوع ملف واحد (PDF) لجميع الروبوتات
وكيل المستخدم: *
Disallow: /*.pdf$
منع جميع عناوين URL ذات المعلمات لبرنامج Googlebot فقط
وكيل المستخدم: Googlebot
عدم السماح: /*؟
كيفية اختبار ملف robots.txt بحثًا عن أخطاء
يمكن أن تكون الأخطاء في ملف robots.txt خطيرة ، لذا من المهم مراقبتها. تحقق من تقرير "التغطية" في Search Console بانتظام للتعرف على المشكلات المتعلقة بملف robot.txt. بعض الأخطاء التي قد تواجهها ، وما تعنيه ، وكيفية إصلاحها مذكورة أدناه.
تم حظر عنوان URL الذي تم إرساله بواسطة ملف robots.txt
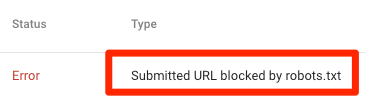
يشير هذا إلى أن ملف robots.txt قد حظر واحدًا على الأقل من عناوين URL في ملف (ملفات) Sitemap الخاص بك. إذا كان ملف Sitemap الخاص بك صحيحًا ولا يتضمن صفحات متعارف عليها أو بدون فهرسة أو تمت إعادة توجيهها ، فيجب ألا يحظر ملف robots.txt أية صفحات ترسلها. إذا كانت كذلك ، فحدد الصفحات المتأثرة وقم بإزالة الحظر من ملف robots.txt الخاص بك.
يمكنك استخدام أداة اختبار ملف robots.txt من Google لتحديد أمر المنع. كن حذرًا عند تحرير ملف robots.txt الخاص بك لأن خطأً ما يمكن أن يؤثر على صفحات أو ملفات أخرى.
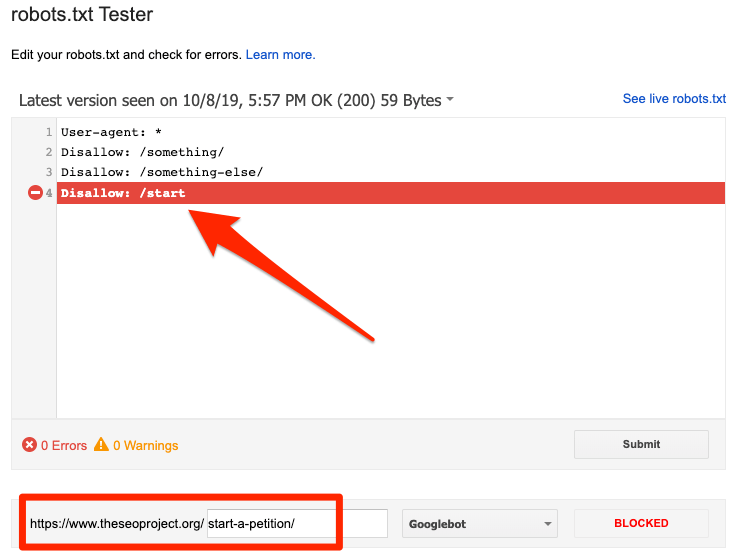
تم الحظر بواسطة ملف robots.txt
يشير هذا الخطأ إلى أن ملف robots.txt قد حظر محتوى لا يمكن لـ Google فهرسته. قم بإزالة منع الزحف في ملف robots.txt إذا كان هذا المحتوى مهمًا ويجب فهرسته. (تحقق أيضًا من أن المحتوى ليس noindexed.)
إذا كنت ترغب في استبعاد محتوى من فهرس Google ، فاستخدم العلامة الوصفية لروبوت أو رأس x-robots وأزل منع الزحف. هذه هي الطريقة الوحيدة لإبقاء المحتوى خارج فهرس Google.
مفهرس ، على الرغم من حظره بواسطة ملف robots.txt
هذا يعني أن Google لا يزال يفهرس بعض المحتوى المحظور بواسطة ملف robots.txt. Robots.txt ليس هو الحل لمنع عرض المحتوى الخاص بك في نتائج بحث Google.
لمنع الفهرسة ، أزل كتلة الزحف واستبدلها بعلامة برامج الروبوت الوصفية أو رأس HTTP بعلامة x-robots-tag. إذا حظرت هذا المحتوى عن طريق الخطأ وتريد من Google فهرسته ، فقم بإزالة منع الزحف في ملف robots.txt. يمكن أن يساعد في تحسين رؤية المحتوى في عمليات بحث Google.
Robots.txt مقابل meta robots مقابل x-robots
ما الذي يميز أوامر الروبوت الثلاثة هذه؟ يعد ملف Robots.txt ملفًا نصيًا بسيطًا ، بينما تعد meta و x-robots عبارة عن توجيهات وصفية. بالإضافة إلى أدوارهم الأساسية ، فإن الثلاثة لديهم وظائف متميزة. يحدد ملف robots.txt سلوك الزحف لموقع الويب أو الدليل بأكمله ، بينما تحدد meta و x-robots سلوك الفهرسة للصفحات الفردية (أو عناصر الصفحة).
قراءة متعمقة
موارد مفيدة
- ويكيبيديا: بروتوكول استبعاد الروبوتات
- وثائق Google على ملف Robots.txt
- وثائق Bing (و Yahoo) على Robots.txt
- وأوضح التوجيهات
- وثائق Yandex على ملف Robots.txt
تغليف
نأمل أن تكون قد أدركت تمامًا أهمية ملف robot.txt ومساهماته في ممارسة تحسين محركات البحث بشكل عام وربحية موقع الويب. إذا كنت لا تزال تكافح من أجل الحصول على دخل من موقع الويب الخاص بك ، فلن تحتاج إلى الترميز لبدء الكسب باستخدام إعلانات Adsterra. ضع رمز إعلان على موقع الويب بتنسيق HTML أو WordPress أو Blogger وابدأ في جني الأرباح اليوم!