
Eine vollständige Anleitung zum Web Scraping
Veröffentlicht: 2023-09-14Im digitalen Zeitalter, in dem im Internet eine Fülle von Informationen verfügbar ist, kann es eine entmutigende Aufgabe sein, Daten von verschiedenen Websites manuell zu sammeln und zu sammeln. Hier bietet sich Web Scraping an.
Was ist Web Scraping?
Unter Web Scraping versteht man die automatisierte Extraktion von Daten aus Websites. Mit Hilfe spezieller Software, allgemein bekannt als Web Scraper oder Web Crawler, können Unternehmen Daten aus verschiedenen Online-Quellen sammeln und in ein strukturiertes Format umwandeln.
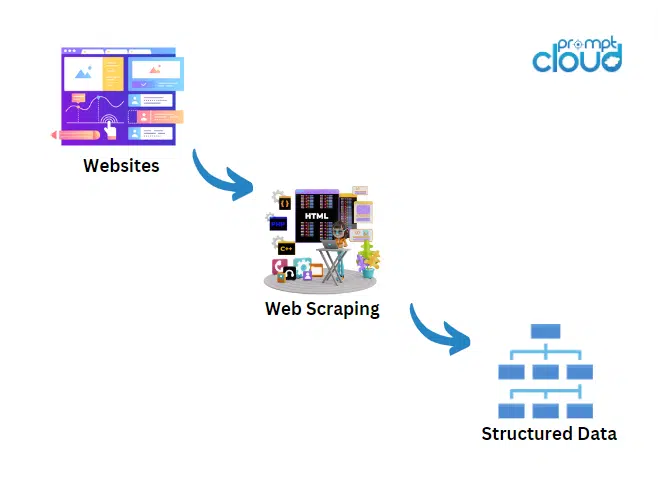
Beim Web Scraping geht es darum, durch Websites zu navigieren und spezifische Datenpunkte zu extrahieren, die für Ihre Geschäftsanforderungen relevant sind. Durch den Einsatz von Web-Scraping-Tools und -Diensten können Unternehmen den Prozess der Datenerfassung und -extraktion automatisieren und so Zeit und Ressourcen sparen.
Stellen Sie sich vor, Sie betreiben ein E-Commerce-Unternehmen und möchten die Preise Ihrer Konkurrenten im Auge behalten. Anstatt manuell die Website jedes Mitbewerbers zu besuchen und die Preise zu notieren, können Sie einen Web-Scraper verwenden, um die Preise automatisch zu extrahieren. Dadurch sparen Sie nicht nur Zeit, sondern stellen auch sicher, dass Sie über korrekte und aktuelle Informationen verfügen. Web-Scraping-Dienste können für verschiedene Zwecke genutzt werden, beispielsweise für Marktforschung, Lead-Generierung, Stimmungsanalyse und vieles mehr. Die Möglichkeiten sind endlos.
Ist Web Scraping legal?
Obwohl Web Scraping zahlreiche Vorteile bietet, ist es für Unternehmen von entscheidender Bedeutung, die rechtlichen und ethischen Richtlinien für den Einsatz zu verstehen und einzuhalten. Die Nichtbeachtung oder der Missbrauch dieser Richtlinien kann rechtliche Konsequenzen nach sich ziehen oder den Ruf eines Unternehmens schädigen. Lassen Sie uns die wichtigsten Überlegungen im Detail untersuchen.

Rechtliche Überlegungen beim Web Scraping
Bei der Durchführung von Web-Scraping-Aktivitäten ist es von entscheidender Bedeutung, die geltenden Gesetze einzuhalten, beispielsweise diejenigen, die geistige Eigentumsrechte, Website-Nutzungsbedingungen und Datenschutzbestimmungen regeln. Andernfalls kann es zu rechtlichen Konsequenzen kommen, die von Verwarnungen und Bußgeldern bis hin zu Klagen reichen können.
Geistige Eigentumsrechte schützen die Schöpfungen des menschlichen Geistes, wie Erfindungen, literarische und künstlerische Werke sowie Symbole, Namen und Bilder, die im Handel verwendet werden. Web Scraping muss diese Rechte respektieren und darf kein urheberrechtlich geschütztes Material oder Marken verletzen. Es ist wichtig, den Umfang der fairen Nutzung zu verstehen und sicherzustellen, dass der gescrapte Inhalt keine Gesetze zum Schutz des geistigen Eigentums verletzt.
Die Nutzungsbedingungen der Website sind rechtliche Vereinbarungen zwischen dem Eigentümer der Website und seinen Benutzern. Diese Bedingungen enthalten häufig Bestimmungen, die Web Scraping ausdrücklich verbieten oder spezifische Einschränkungen für seine Verwendung vorsehen. Es ist wichtig, die Nutzungsbedingungen jeder Website zu überprüfen, bevor Sie sie entfernen, um die Einhaltung sicherzustellen. Ein Verstoß gegen diese Bedingungen kann rechtliche Schritte nach sich ziehen, einschließlich Unterlassungserklärungen oder sogar Klagen wegen Vertragsbruch.
Datenschutzbestimmungen , wie beispielsweise die Datenschutz-Grundverordnung (DSGVO) in der Europäischen Union, regeln die Erhebung und Verarbeitung personenbezogener Daten. Web-Scraping-Aktivitäten müssen diese Vorschriften respektieren, indem die erforderliche Zustimmung der Benutzer eingeholt wird, bevor ihre persönlichen Daten erfasst werden. Darüber hinaus müssen Unternehmen die gescrapten Daten sicher verarbeiten und speichern, um unbefugten Zugriff oder Datenschutzverletzungen zu verhindern.
Ethische Richtlinien für Web Scraping
Ethik spielt beim Web Scraping eine entscheidende Rolle. Unternehmen sollten sicherstellen, dass sie die Rechte der Website-Eigentümer respektieren und der Privatsphäre der Benutzer Priorität einräumen. Es ist wichtig, bei Bedarf die Einwilligung einzuholen und das Scrapen sensibler oder urheberrechtlich geschützter Informationen zu vermeiden.
Transparenz und Verantwortlichkeit sollten die Leitprinzipien beim Einsatz von Web Scraping für geschäftliche Zwecke sein. Eine klare Kommunikation des Zwecks der Scraping-Aktivität und die Bereitstellung der Möglichkeit für Benutzer, sich abzumelden, kann dazu beitragen, Vertrauen aufzubauen und ethische Standards einzuhalten. Darüber hinaus sollten Unternehmen Maßnahmen ergreifen, um die gescrapten Daten zu schützen und deren Missbrauch oder unbefugten Zugriff zu verhindern.
Darüber hinaus sollten Unternehmen die Auswirkungen von Web Scraping auf die Leistung der Website berücksichtigen. Übermäßiges Scraping kann den Server belasten und sich negativ auf das Benutzererlebnis für andere Besucher auswirken. Die Implementierung von Scraping-Techniken, die die Auswirkungen auf die Leistung der Website minimieren, wie z. B. die Verwendung geeigneter Scraping-Intervalle und die Berücksichtigung von robots.txt-Dateien, ist für die Aufrechterhaltung ethischer Praktiken unerlässlich.
Durch die Einhaltung gesetzlicher Anforderungen und ethischer Richtlinien können Unternehmen sicherstellen, dass ihre Web-Scraping-Aktivitäten verantwortungsvoll und ohne Schaden für andere durchgeführt werden. Es ist immer ratsam, Rechtsexperten zu konsultieren, um sicherzustellen, dass die spezifischen Gesetze und Vorschriften eingehalten werden, die für die Gerichtsbarkeit gelten, in der das Scraping stattfindet.
Wie funktioniert ein Web Scraper?
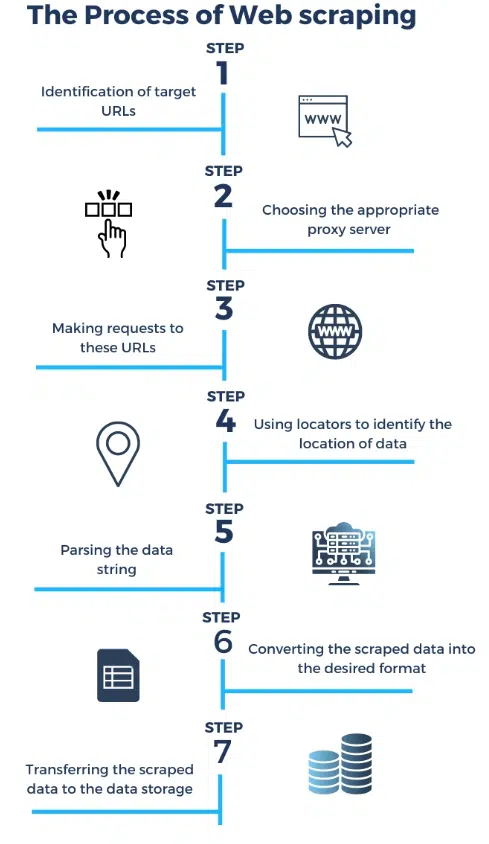
Quelle: https://research.aimultiple.co
Web Scraping folgt einem strukturierten Prozess. Der erste Schritt besteht darin , eine Anfrage an den Server einer Zielwebsite zu senden. Diese Anfrage ähnelt der, die Ihr Browser sendet, wenn Sie eine Website besuchen. Der Server antwortet dann auf die Anfrage, indem er den HTML-Code der Webseite zurücksendet.
Sobald der Web Scraper den HTML-Code erhält, beginnt er mit der Analyse, um die gewünschten Daten zu extrahieren . Beim Parsen wird die Struktur des HTML-Codes analysiert und die spezifischen Elemente identifiziert, die die für Sie interessanten Daten enthalten. Dies kann alles sein, von Produktpreisen bis hin zu Kundenbewertungen.
Nach dem Extrahieren der Daten kann der Web Scraper diese in einem strukturierten Format speichern , beispielsweise in einer Tabellenkalkulation oder einer Datenbank. Dadurch können Unternehmen einfach auf die gesammelten Daten zugreifen und diese analysieren.
Web Scraping kann ein komplexer Prozess sein, insbesondere wenn es um Websites geht, die dynamische Inhalte haben oder eine Authentifizierung erfordern. Mit den richtigen Web-Scraping-Tools und -Diensten können Unternehmen diese Herausforderungen jedoch meistern und die Leistungsfähigkeit von Web-Scraping-Diensten nutzen, um wertvolle Erkenntnisse zu gewinnen und der Konkurrenz einen Schritt voraus zu sein.
Arten von Web Scrapern
Web Scraper sind Softwaretools zum Extrahieren von Daten aus Websites. Es gibt sie in verschiedenen Ausführungen, die je nach Funktionalität, Zweck und der Art und Weise, wie sie auf Webinhalte zugreifen und diese analysieren, kategorisiert werden können. Hier sind einige verschiedene Arten von Web-Scrapern:
Grundlegende Schaber:
- HTML-Scraper : Diese scrapen Daten aus HTML-Seiten, indem sie das Markup analysieren. Sie können Text, Links und andere Elemente aus Webseiten extrahieren.
- Text Scraper : Diese konzentrieren sich auf das Extrahieren von Textinhalten aus Webseiten, wie z. B. Artikeln, Blogbeiträgen oder Nachrichtenartikeln.
Fortgeschrittene Schaber:
- Dynamic Content Scraper : Diese können Websites mit JavaScript-gesteuerten Inhalten durchsuchen. Sie verwenden Headless-Browser oder Automatisierungstools wie Selenium, um mit Webseiten zu interagieren und Daten zu extrahieren.
- API-Scraper : Diese interagieren direkt mit Web-APIs, um strukturierte Daten abzurufen. Viele Websites bieten APIs für den Zugriff auf ihre Daten in einem strukturierten Format an.
Spezialschaber:
- E-Commerce-Scraper : Entwickelt, um Produktinformationen, Preise und Bewertungen von E-Commerce-Websites zu extrahieren.
- Social-Media-Scraper : Diese scrapen Daten von Social-Media-Plattformen wie Twitter, Facebook oder Instagram, einschließlich Beiträgen, Kommentaren und Benutzerprofilen.
- News Scraper : Konzentriert sich auf das Extrahieren von Nachrichtenartikeln, Schlagzeilen und zugehörigen Informationen von Nachrichten-Websites.
- Job Scraper : Sammeln Sie Stellenangebote und zugehörige Daten von Websites zur Jobsuche.
- Real Estate Scraper : Extrahieren Sie Immobilienangebote, Preise und Details von Immobilien-Websites.
Bild- und Medienschaber:
- Image Scraper : Laden Sie Bilder von Websites herunter, die häufig für Bilddatensätze oder Stockfotos-Sammlungen verwendet werden.
- Video Scraper : Sammeln Sie Videoinhalte und Metadaten von Websites wie YouTube oder Vimeo.
Überwachungs- und Alarm-Scraper:
- Change Detection Scraper : Überwachen Sie Websites kontinuierlich auf Änderungen und benachrichtigen Sie Benutzer, wenn bestimmte Kriterien erfüllt sind (z. B. Preissenkungen, Inhaltsaktualisierungen).
Maßgeschneiderte Schaber:
- Maßgeschneiderte Schaber, die für spezifische, einzigartige Anwendungsfälle entwickelt wurden. Diese werden häufig von Web-Scraping-Dienstleistern erstellt, um bestimmte Anforderungen an die Datenextraktion zu erfüllen.
Python: Das ultimative Tool für Web Scraping
Python hat sich zur bevorzugten Sprache für Web Scraping entwickelt, und das ist kein Zufall. Seine Beliebtheit in diesem Bereich wird durch mehrere zwingende Gründe untermauert.
Vielseitigkeit und einfache Lernfähigkeit
Die Einfachheit und Lesbarkeit von Python machen es unabhängig von Ihrer Programmiererfahrung zur idealen Wahl für Web Scraping. Der Code ähnelt einfachem Englisch und ist sowohl für Anfänger als auch für erfahrene Entwickler zugänglich.

Reichhaltiges Ökosystem von Bibliotheken
Python verfügt über eine Fülle von Bibliotheken, die speziell für das Web-Scraping entwickelt wurden. Unter ihnen stechen BeautifulSoup und Scrapy hervor. Diese Bibliotheken abstrahieren komplexe Aufgaben wie das Parsen von HTML und das Senden von HTTP-Anfragen und rationalisieren so den Scraping-Prozess erheblich.
Aktive Community-Unterstützung
Python wird von einer lebendigen und enthusiastischen Entwickler-Community unterstützt. Unzählige Online-Ressourcen, Tutorials und Foren stehen zur Verfügung, um bei Web-Scraping-Herausforderungen zu helfen und sicherzustellen, dass Sie nie ohne Anleitung stecken bleiben.
Plattformübergreifende Kompatibilität
Python läuft nahtlos auf verschiedenen Betriebssystemen, von Windows über macOS bis hin zu Linux. Diese plattformübergreifende Kompatibilität bedeutet, dass Ihre Web-Scraping-Skripte in verschiedenen Umgebungen konsistent funktionieren können.
Robustes Datenparsing
Mit seinen Funktionen zur String-Manipulation eignet sich Python hervorragend zum Navigieren und Extrahieren von Daten aus Webseiten, selbst wenn es sich um komplizierte Seitenstrukturen handelt. Insbesondere BeautifulSoup vereinfacht das Parsen von HTML- und XML-Dokumenten.
HTTP-Anforderungsverarbeitung
Die „Requests“-Bibliothek von Python optimiert den Prozess der Erstellung von HTTP-Anfragen, der für das Web-Scraping von grundlegender Bedeutung ist. Es übernimmt häufige Aufgaben wie GET- und POST-Anfragen, Cookie-Verwaltung und Weiterleitungen und macht Ihre Scraping-Aufgaben zum Kinderspiel. Python-Web-Scraping ist heutzutage weit verbreitet.
Integration mit Automatisierungstools
Für Websites mit dynamischen Inhalten lässt sich Python gut mit Automatisierungstools wie Selenium kombinieren. Dadurch können Sie wie ein menschlicher Benutzer mit Seiten interagieren und so den Zugriff auf Inhalte sicherstellen, die eine Benutzerinteraktion erfordern.
Datenverarbeitung und -analyse
Die Datenverarbeitungs- und Analysebibliotheken von Python, wie Pandas und NumPy, erleichtern die Bereinigung, Transformation und Analyse der beim Web Scraping extrahierten Daten. Das bedeutet, dass Sie Rohdaten in umsetzbare Erkenntnisse umwandeln können.
Ethische Scraping-Praktiken
Die Flexibilität von Python ermöglicht die Implementierung ethischer Scraping-Praktiken. Sie können die Nutzungsbedingungen der Website respektieren, sich an die robots.txt-Richtlinien halten und die Anfrageraten verwalten, um das Risiko einer IP-Blockierung zu minimieren.
Integration mit Datenbanken und APIs
Die Vielseitigkeit von Python erstreckt sich auch auf die Fähigkeit, eine Verbindung mit verschiedenen Datenbanken und Web-APIs herzustellen. Auf diese Weise können Sie Scraped-Daten zur weiteren Analyse oder Integration in Ihre Anwendungen speichern und abrufen.
Geschäftsvorteile von Web Scraping
Web Scraping bietet zahlreiche Vorteile, die sich erheblich auf Unternehmen in verschiedenen Branchen auswirken können. Lassen Sie uns einige Schlüsselbereiche erkunden, in denen Web Scraping von unschätzbarem Wert sein kann.
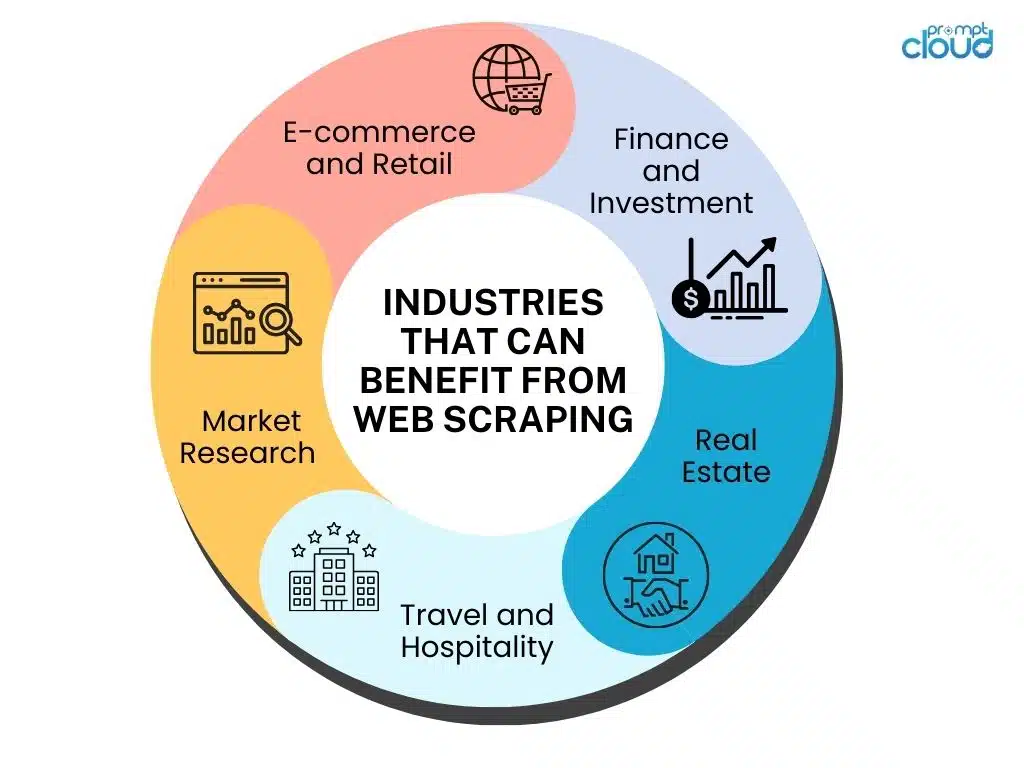
Verbesserung der Marktforschung – Marktforschung bildet die Grundlage jedes erfolgreichen Unternehmens. Mit Web Scraping können Unternehmen eine Fülle von Informationen über ihre Konkurrenten, Markttrends, Preisstrategien und Kundenpräferenzen sammeln. Durch die Analyse dieser Daten können Unternehmen fundiertere Entscheidungen treffen und effektive Strategien entwickeln, um der Konkurrenz einen Schritt voraus zu sein.
Beispielsweise kann Web Scraping Unternehmen dabei helfen, die Preisstrategien ihrer Konkurrenten in Echtzeit zu verfolgen. Durch die Überwachung der Preise ähnlicher Produkte oder Dienstleistungen können Unternehmen ihre eigenen Preisstrategien anpassen, um wettbewerbsfähig zu bleiben. Darüber hinaus kann Web Scraping Einblicke in die Kundenstimmung liefern, indem es Online-Bewertungen und Social-Media-Beiträge analysiert. Diese Informationen können Unternehmen dabei helfen, Kundenpräferenzen zu verstehen und ihre Produkte oder Dienstleistungen entsprechend anzupassen.
Förderung der Lead-Generierung – Die Generierung hochwertiger Leads ist für das Geschäftswachstum von entscheidender Bedeutung. Mit Web Scraping können Unternehmen Kontaktinformationen wie E-Mail-Adressen und Telefonnummern aus Websites und Verzeichnissen extrahieren. Diese Daten können dann für gezielte Marketingkampagnen genutzt werden und so die Chancen erhöhen, potenzielle Kunden zu erreichen und Leads zu generieren.
Darüber hinaus kann Web Scraping Unternehmen dabei helfen, potenzielle Leads zu identifizieren, indem es Online-Foren, Social-Media-Plattformen und branchenspezifische Websites überwacht. Durch die Analyse von Diskussionen und Interaktionen können Unternehmen Einzelpersonen oder Organisationen identifizieren, die einen Bedarf oder ein Interesse an ihren Produkten oder Dienstleistungen zum Ausdruck bringen. Dieser proaktive Ansatz zur Lead-Generierung kann die Konversionsraten erheblich verbessern und das Geschäftswachstum vorantreiben.
Optimierung der Datenerfassung – Daten sind ein wesentlicher Bestandteil der Entscheidungsfindung, und Web Scraping vereinfacht den Prozess der Datenerfassung. Anstatt mehrere Websites manuell zu besuchen und Informationen zu kopieren, können Unternehmen den Datenextraktionsprozess automatisieren. Mit Web Scraping können Unternehmen schnell und effizient große Datenmengen sammeln und so genauere Analysen und schnellere Erkenntnisse gewinnen.
Mithilfe von Web Scraping können beispielsweise Daten von E-Commerce-Websites gesammelt werden, um Produkttrends, Kundenverhalten und Preismuster zu analysieren. Diese Informationen können Unternehmen dabei helfen, ihr Produktangebot zu optimieren, die Kundenzufriedenheit zu verbessern und neue Marktchancen zu erkennen. Darüber hinaus kann Web Scraping verwendet werden, um Daten von Nachrichten-Websites, Blogs und Branchenpublikationen zu sammeln und Unternehmen aktuelle Informationen zu Branchenentwicklungen und -trends bereitzustellen.
Web-Scraping-Dienste spielen eine entscheidende Rolle bei der Verbesserung der Marktforschung, der Förderung der Lead-Generierung und der Rationalisierung der Datenerfassung für Unternehmen. Durch die Nutzung der Leistungsfähigkeit von Web Scraping können Unternehmen einen Wettbewerbsvorteil erlangen, fundierte Entscheidungen treffen und das Wachstum in der heutigen digitalen Landschaft vorantreiben.
Erste Schritte mit Web Scraping
Lassen Sie uns auf einige wichtige Aspekte eingehen, die Sie bei der Integration von Web Scraping in Ihre Abläufe berücksichtigen sollten.
Auswahl der besten Web-Scraping-Tools
Wenn es um Web Scraping geht, haben Sie im Wesentlichen zwei Möglichkeiten: Sie können Web Scraping-Tools verwenden oder die Aufgabe an Web Scraping-Dienstleister auslagern. Beginnen wir mit der Erkundung der verschiedenen Aspekte von Web-Scraping-Tools:
Es gibt eine große Auswahl an Web-Scraping-Tools auf dem Markt. Es ist wichtig, Ihre Geschäftsanforderungen zu bewerten und ein Tool auszuwählen, das die erforderlichen Funktionen, Skalierbarkeit und Benutzerfreundlichkeit bietet. Führen Sie gründliche Recherchen durch und berücksichtigen Sie Faktoren wie Datenextraktionsfunktionen, Anpassungsoptionen und Kundensupport, bevor Sie eine Entscheidung treffen. Einige zu berücksichtigende Faktoren sind:
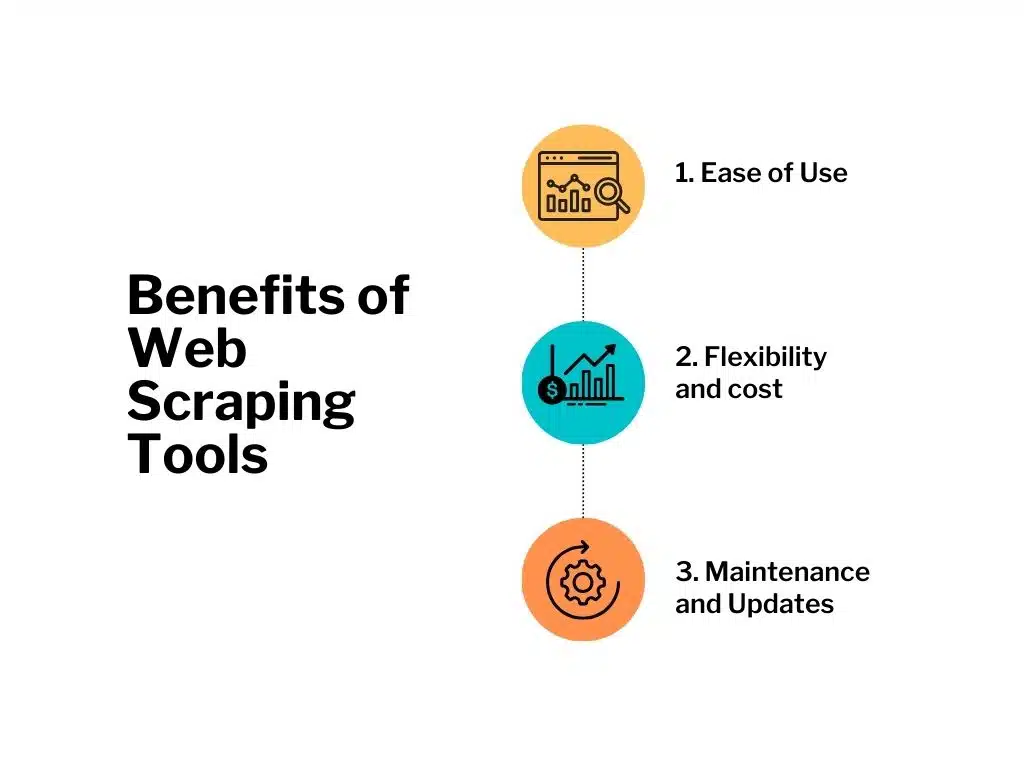
- Benutzerfreundlichkeit : Web-Scraping-Tools verfügen über benutzerfreundliche Oberflächen und erfordern nur minimale Programmierkenntnisse. Sie bieten eine visuelle Scraping-Funktion, mit der Sie die benötigten Daten einfach von einer Website auswählen können. Zu den beliebten Web-Scraping-Tools gehören Beautiful Soup, Scrapy und Octoparse.
- Flexibilität: Mit Web-Scraping-Tools können Sie Ihre Scraping-Skripte an Ihre spezifischen Anforderungen anpassen. Sie bieten die Flexibilität, Daten von mehreren Websites gleichzeitig zu extrahieren, komplexe Webseiten zu verarbeiten und Daten in verschiedenen Formaten wie CSV, JSON oder XML zu extrahieren.
- Kosten : Web-Scraping-Tools sind im Allgemeinen kostengünstiger als die Auslagerung der Aufgabe an Dienstleister. Die meisten Tools bieten kostenlose Versionen mit eingeschränkten Funktionen an, während kostenpflichtige Versionen erweiterte Funktionen und Support bieten.
- Wartung und Updates : Da sich die Technologie weiterentwickelt, ändern Websites häufig ihre Struktur, was eine Aktualisierung der Scraping-Skripte erforderlich macht. Web-Scraping-Tools erfordern regelmäßige Wartung und Updates, um eine genaue und kontinuierliche Datenextraktion zu gewährleisten.
Bewertung von Web-Scraping-Dienstleistern
Während Web-Scraping-Tools eine ausgezeichnete Wahl für Einzelpersonen oder kleine Projekte sein können, sind sie möglicherweise nicht immer die beste Lösung für Unternehmen mit komplexen Scraping-Anforderungen. Um eine fundierte Entscheidung zu treffen, berücksichtigen Sie bei der Bewertung von Web-Scraping-Dienstleistern die folgenden Faktoren:
- Skalierbarkeit : Dienstanbieter verfügen über die Infrastruktur und Ressourcen, um groß angelegte Web-Scraping-Projekte effizient abzuwickeln. Sie können gleichzeitige Scrapes verarbeiten, Zugriff auf mehrere Proxyserver ermöglichen, um Website-Einschränkungen zu umgehen, und eine unterbrechungsfreie Datenextraktion gewährleisten.
- Datenqualität : Web-Scraping-Dienstleister sind auf die Bereitstellung hochwertiger und genauer Daten spezialisiert. Sie können Herausforderungen wie CAPTCHA, dynamische Websites und sich ändernde Seitenstrukturen effektiver bewältigen, was zu zuverlässigen und konsistenten Daten führt.
- Einhaltung gesetzlicher Vorschriften : Web Scraping kann eine rechtliche Grauzone sein, und Dienstanbieter sind mit der Bewältigung der rechtlichen Komplexität bestens vertraut. Sie stellen die Einhaltung der Website-Nutzungsbedingungen, Urheberrechtsgesetze und Datenschutzbestimmungen sicher und verringern so das Risiko rechtlicher Konsequenzen.
- Anpassung und Support : Dienstleister bieten maßgeschneiderte Lösungen, um Ihre spezifischen Scraping-Anforderungen zu erfüllen. Sie können komplexe Datenextraktionsaufgaben bewältigen, benutzerdefinierte Datenformatierungen bereitstellen und fortlaufenden technischen Support bieten.
Warum sollten Sie sich für Web-Scraping-Dienstleister statt für Tools entscheiden?
Obwohl Web-Scraping-Tools ihre Vorzüge haben, gibt es überzeugende Gründe, warum Unternehmen die Auslagerung von Web-Scraping an Dienstleister in Betracht ziehen sollten:
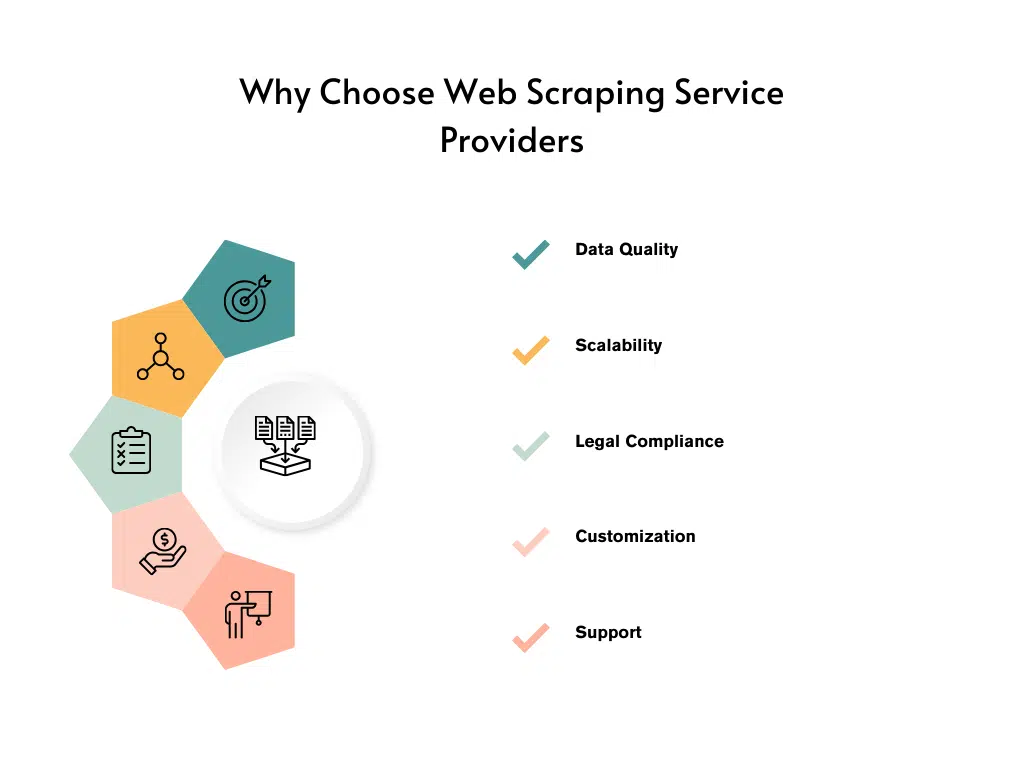
- Fachwissen und Erfahrung : Web-Scraping-Dienstleister sind auf die Datenextraktion spezialisiert und verfügen über umfangreiche Erfahrung in der Abwicklung einer Vielzahl von Scraping-Projekten. Sie verfügen über das nötige Fachwissen, um Herausforderungen zu meistern und verlässliche Ergebnisse zu liefern.
- Fokus auf Kernkompetenzen : Durch die Auslagerung von Web Scraping können sich Unternehmen auf ihre Kernkompetenzen konzentrieren, anstatt Zeit und Ressourcen in die Beherrschung von Scraping-Tools und -Techniken zu investieren. Dies ermöglicht es Unternehmen, ihre Kernaktivitäten zu priorisieren und das Wachstum voranzutreiben.
- Kostengünstig : Entgegen der landläufigen Meinung können Web-Scraping-Dienstleister auf lange Sicht oft Kosteneinsparungen bieten. Sie können präzise und relevante Daten schneller liefern, sodass Unternehmen zeitnah datengesteuerte Entscheidungen treffen können, was zu einer verbesserten betrieblichen Effizienz führt.
- Spart Zeit und Mühe : Web-Scraping-Dienstleister kümmern sich um den gesamten Web-Scraping-Prozess, von der Datenextraktion bis hin zur Handhabung von Wartung und Aktualisierungen. Dies entlastet Ihr Team von Zeit und Aufwand und ermöglicht es ihm, sich auf die Analyse der extrahierten Daten und die Ableitung wertvoller Erkenntnisse zu konzentrieren.
Web Scraping ist ein wertvolles Tool für Unternehmen, die die Leistungsfähigkeit von Daten nutzen möchten. Während Web-Scraping-Tools für kleine Projekte nützlich sein können, bietet die Auslagerung an Web-Scraping-Dienstleister zahlreiche Vorteile, darunter Skalierbarkeit, Datenqualität, Rechtskonformität, Anpassung und professioneller Support. Indem Sie Ihre Anforderungen sorgfältig bewerten und diese Faktoren berücksichtigen, können Sie eine fundierte Entscheidung treffen, die Ihren Geschäftsanforderungen am besten entspricht.