
Fortgeschrittene Techniken zur Verbesserung des LLM-Durchsatzes
Veröffentlicht: 2024-04-02In der schnelllebigen Welt der Technologie sind Large Language Models (LLMs) zu Schlüsselfiguren bei der Art und Weise geworden, wie wir mit digitalen Informationen interagieren. Diese leistungsstarken Tools können Artikel schreiben, Fragen beantworten und sogar Gespräche führen, sind jedoch nicht ohne Herausforderungen. Je mehr wir von diesen Modellen verlangen, desto mehr stoßen wir auf Hürden, insbesondere wenn es darum geht, sie schneller und effizienter arbeiten zu lassen. In diesem Blog geht es darum, diese Hürden direkt zu meistern.
Wir beschäftigen uns mit einigen intelligenten Strategien, die darauf abzielen, die Arbeitsgeschwindigkeit dieser Modelle zu steigern, ohne die Qualität ihrer Ausgabe zu beeinträchtigen. Stellen Sie sich vor, Sie möchten die Geschwindigkeit eines Rennwagens verbessern und gleichzeitig sicherstellen, dass er weiterhin problemlos durch enge Kurven fährt – das ist unser Ziel mit großen Sprachmodellen. Wir werden uns mit Methoden wie Continuous Batching befassen, die dabei helfen, Informationen reibungsloser zu verarbeiten, und mit innovativen Ansätzen wie Paged und Flash Attention, die LLMs aufmerksamer und schneller in ihrem digitalen Denken machen.
Wenn Sie also neugierig darauf sind, die Grenzen der Möglichkeiten dieser KI-Giganten zu erweitern, sind Sie hier richtig. Lassen Sie uns gemeinsam erkunden, wie diese fortschrittlichen Techniken die Zukunft von LLMs prägen und sie schneller und besser als je zuvor machen.
Herausforderungen beim Erreichen eines höheren Durchsatzes für LLMs
Das Erreichen eines höheren Durchsatzes in Large Language Models (LLMs) steht vor mehreren erheblichen Herausforderungen, die jeweils ein Hindernis für die Geschwindigkeit und Effizienz darstellen, mit der diese Modelle arbeiten können. Ein Haupthindernis ist der reine Speicherbedarf, der für die Verarbeitung und Speicherung der riesigen Datenmengen erforderlich ist, mit denen diese Modelle arbeiten. Mit zunehmender Komplexität und Größe von LLMs steigt der Bedarf an Rechenressourcen, was es schwierig macht, die Verarbeitungsgeschwindigkeiten aufrechtzuerhalten oder gar zu steigern.
Eine weitere große Herausforderung ist die autoregressive Natur von LLMs, insbesondere in Modellen, die zur Textgenerierung verwendet werden. Dies bedeutet, dass die Ausgabe bei jedem Schritt von den vorherigen abhängt, wodurch eine sequentielle Verarbeitungsanforderung entsteht, die von Natur aus die Geschwindigkeit begrenzt, mit der Aufgaben ausgeführt werden können. Diese sequentielle Abhängigkeit führt oft zu einem Engpass, da jeder Schritt auf den Abschluss seines Vorgängers warten muss, bevor er fortfahren kann, was Bemühungen zur Erzielung eines höheren Durchsatzes behindert.
Darüber hinaus ist die Balance zwischen Genauigkeit und Geschwindigkeit eine heikle Angelegenheit. Die Steigerung des Durchsatzes ohne Beeinträchtigung der Qualität der Ausgabe ist eine Gratwanderung und erfordert innovative Lösungen, die sich in der komplexen Landschaft von Recheneffizienz und Modelleffektivität zurechtfinden.
Diese Herausforderungen bilden den Hintergrund, vor dem Fortschritte in der LLM-Optimierung gemacht werden und die Grenzen dessen, was im Bereich der Verarbeitung natürlicher Sprache und darüber hinaus möglich ist, verschieben.
Speicherbedarf
Die Dekodierungsphase generiert bei jedem Zeitschritt ein einzelnes Token, aber jedes Token hängt von den Schlüssel- und Werttensoren aller vorherigen Token ab (einschließlich der beim Vorfüllen berechneten KV-Tensoren der Eingabe-Tokens und aller neuen KV-Tensoren, die bis zum aktuellen Zeitschritt berechnet wurden). .
Um die redundanten Berechnungen jedes Mal zu minimieren und zu vermeiden, dass alle Tensoren für alle Token bei jedem Zeitschritt neu berechnet werden, ist es daher möglich, sie im GPU-Speicher zwischenzuspeichern. Wenn bei jeder Iteration neue Elemente berechnet werden, werden diese einfach zum laufenden Cache hinzugefügt, um in der nächsten Iteration verwendet zu werden. Dies wird im Wesentlichen als KV-Cache bezeichnet.
Dies reduziert den Rechenaufwand erheblich, führt jedoch zu einem Speicherbedarf sowie ohnehin schon höheren Speicheranforderungen für große Sprachmodelle, was die Ausführung auf handelsüblichen GPUs erschwert. Mit zunehmender Modellparametergröße (7B bis 33B) und höherer Präzision (fp16 bis fp32) steigt auch der Speicherbedarf. Sehen wir uns ein Beispiel für die erforderliche Speicherkapazität an:
Wie wir wissen, sind dies die beiden Hauptspeicherbelegungen
- Eigene Gewichte des Modells im Speicher, dies kommt mit Nr. von Parametern wie 7B und Datentyp jedes Parameters, z. B. 7B in fp16 (2 Byte) ~= 14 GB im Speicher
- KV-Cache: Der Cache, der für den Schlüsselwert der Selbstaufmerksamkeitsphase verwendet wird, um redundante Berechnungen zu vermeiden.
Größe des KV-Cache pro Token in Bytes = 2 * (num_layers) * (hidden_size) * precision_in_bytes
Der erste Faktor 2 berücksichtigt K- und V-Matrizen. Diese „hidden_size“ und „dim_head“ können von der Karte des Modells oder der Konfigurationsdatei abgerufen werden.
Die obige Formel gilt pro Token, also ist sie für eine Eingabesequenz seq_len * size_of_kv_per_token. Die obige Formel wird also wie folgt umgewandelt:
Gesamtgröße des KV-Cache in Bytes = (sequence_length) * 2 * (num_layers) * (hidden_size) * precision_in_bytes
Bei LLAMA 2 in fp16 beträgt die Größe beispielsweise (4096) * 2 * (32) * (4096) * 2, was ~2 GB entspricht.
Das oben Genannte gilt für eine einzelne Eingabe. Bei mehreren Eingaben nimmt die Zahl schnell zu. Diese On-Flight-Speicherzuweisung und -verwaltung wird somit zu einem entscheidenden Schritt zur Erzielung einer optimalen Leistung, wenn nicht, führt dies zu Problemen mit Speichermangel und Fragmentierung.
Manchmal ist der Speicherbedarf größer als die Kapazität unserer GPU. In diesen Fällen müssen wir uns mit der Modellparallelität und Tensorparallelität befassen, die hier nicht behandelt wird, aber Sie können sie in diese Richtung untersuchen.
Automatische Regressivität und speichergebundener Betrieb
Wie wir sehen können, ist der Teil der Ausgabegenerierung großer Sprachmodelle von Natur aus autoregressiv. Das bedeutet, dass jedes neue Token, das generiert werden soll, von allen vorherigen Token und seinen Zwischenzuständen abhängt. Da in der Ausgabestufe nicht alle Token für weitere Berechnungen verfügbar sind und es nur einen Vektor (für das nächste Token) und den Block der vorherigen Stufe gibt, ähnelt dies einer Matrix-Vektor-Operation, die die GPU-Rechenfähigkeit nicht ausreichend nutzt im Vergleich zur Vorfüllphase. Die Geschwindigkeit, mit der die Daten (Gewichte, Schlüssel, Werte, Aktivierungen) aus dem Speicher zur GPU übertragen werden, bestimmt die Latenz und nicht die tatsächliche Geschwindigkeit der Berechnungen. Mit anderen Worten: Dies ist eine speichergebundene Operation.
Innovative Lösungen zur Bewältigung von Durchsatzherausforderungen
Kontinuierliche Dosierung
Der sehr einfache Schritt zur Reduzierung der Speicherbindung der Dekodierungsphase besteht darin, die Eingaben zu stapeln und Berechnungen für mehrere Eingaben gleichzeitig durchzuführen. Eine einfache konstante Stapelverarbeitung hat jedoch aufgrund der Art der erzeugten unterschiedlichen Sequenzlängen zu einer schlechten Leistung geführt. Hier hängt die Latenz eines Stapels von der längsten Sequenz ab, die in einem Stapel generiert wird, und außerdem mit einem wachsenden Speicherbedarf, da mehrere Eingaben erforderlich sind jetzt sofort bearbeitet.
Daher ist eine einfache statische Dosierung wirkungslos und es kommt zur kontinuierlichen Dosierung. Sein Kern liegt darin, eingehende Anforderungsstapel dynamisch zu aggregieren, sich an schwankende Eingangsraten anzupassen und Möglichkeiten zur Parallelverarbeitung zu nutzen, wann immer dies möglich ist. Dies optimiert auch die Speichernutzung, indem Sequenzen ähnlicher Länge in jedem Stapel gruppiert werden, was den für kürzere Sequenzen erforderlichen Auffüllaufwand minimiert und die Verschwendung von Rechenressourcen durch übermäßiges Auffüllen vermeidet.

Es passt die Stapelgröße adaptiv an, basierend auf Faktoren wie der aktuellen Speicherkapazität, den Rechenressourcen und den Längen der Eingabesequenzen. Dadurch wird sichergestellt, dass das Modell unter wechselnden Bedingungen optimal funktioniert, ohne dass die Speicherbeschränkungen überschritten werden. Dies hilft bei der ausgelagerten Aufmerksamkeit (siehe unten) und trägt dazu bei, die Latenz zu reduzieren und den Durchsatz zu erhöhen.
Lesen Sie weiter: Wie kontinuierliches Batching einen 23-fachen Durchsatz bei der LLM-Inferenz ermöglicht und gleichzeitig die p50-Latenz reduziert
Ausgeblätterte Aufmerksamkeit
Da wir zur Verbesserung des Durchsatzes eine Stapelverarbeitung durchführen, geht dies auch mit einem erhöhten Bedarf an KV-Cache-Speicher einher, da wir jetzt mehrere Eingaben gleichzeitig verarbeiten. Diese Sequenzen können die Speicherkapazität der verfügbaren Rechenressourcen überschreiten, sodass es unpraktisch ist, sie vollständig zu verarbeiten.
Es wird auch beobachtet, dass die naive Speicherzuweisung des KV-Cache zu einer starken Speicherfragmentierung führt, genau wie wir es in Computersystemen aufgrund der ungleichmäßigen Speicherzuweisung beobachten. vLLM führte Paged Attention ein, eine Speicherverwaltungstechnik, die von Betriebssystemkonzepten wie Paging und virtuellem Speicher inspiriert ist, um den wachsenden Bedarf an KV-Cache effizient zu bewältigen.
Paged Attention behebt Speicherbeschränkungen, indem es den Aufmerksamkeitsmechanismus in kleinere Seiten oder Segmente unterteilt, die jeweils eine Teilmenge der Eingabesequenz abdecken. Anstatt Aufmerksamkeitswerte für die gesamte Eingabesequenz auf einmal zu berechnen, konzentriert sich das Modell jeweils auf eine Seite und verarbeitet sie nacheinander.
Während der Inferenz oder des Trainings durchläuft das Modell jede Seite der Eingabesequenz, berechnet Aufmerksamkeitswerte und generiert entsprechend eine Ausgabe. Sobald eine Seite verarbeitet wurde, werden die Ergebnisse gespeichert und das Modell geht zur nächsten Seite über.
Durch die Aufteilung des Aufmerksamkeitsmechanismus in Seiten ermöglicht Paged Attention dem großen Sprachmodell, Eingabesequenzen beliebiger Länge zu verarbeiten, ohne die Speicherbeschränkungen zu überschreiten. Dadurch wird der für die Verarbeitung langer Sequenzen erforderliche Speicherbedarf effektiv reduziert, sodass die Arbeit mit großen Dokumenten und Stapeln möglich ist.
Lesen Sie weiter: Schnelles LLM-Serving mit vLLM und PagedAttention
Blitzende Aufmerksamkeit
Da der Aufmerksamkeitsmechanismus für Transformatormodelle, auf denen die großen Sprachmodelle basieren, von entscheidender Bedeutung ist, hilft er dem Modell, sich bei Vorhersagen auf relevante Teile des Eingabetextes zu konzentrieren. Da transformatorbasierte Modelle jedoch größer und komplexer werden, wird der Selbstaufmerksamkeitsmechanismus immer langsamer und speicherintensiver, was, wie bereits erwähnt, zu einem Speicherengpassproblem führt. Flash Attention ist eine weitere Optimierungstechnik, die darauf abzielt, dieses Problem durch die Optimierung von Aufmerksamkeitsvorgängen zu entschärfen und so ein schnelleres Training und Schlussfolgerungen zu ermöglichen.
Hauptmerkmale von Flash Attention:
Kernel Fusion: Es ist wichtig, nicht nur die GPU-Rechennutzung zu maximieren, sondern sie auch so effizient wie möglich zu gestalten. Flash Attention kombiniert mehrere Rechenschritte in einem einzigen Vorgang und reduziert so die Notwendigkeit sich wiederholender Datenübertragungen. Dieser optimierte Ansatz vereinfacht den Implementierungsprozess und erhöht die Recheneffizienz.
Tiling: Flash Attention unterteilt die geladenen Daten in kleinere Blöcke und unterstützt so die Parallelverarbeitung. Diese Strategie optimiert die Speichernutzung und ermöglicht skalierbare Lösungen für Modelle mit größeren Eingabegrößen.
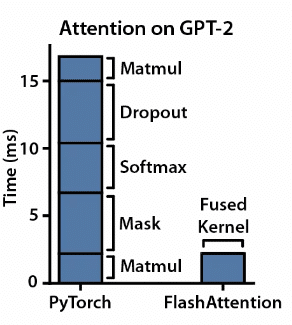
(Fusierter CUDA-Kernel, der zeigt, wie Kacheln und Fusion die für die Berechnung erforderliche Zeit reduzieren, Bildquelle: FlashAttention: Schnelle und speichereffiziente exakte Aufmerksamkeit mit IO-Awareness)
Speicheroptimierung: Flash Attention lädt Parameter nur für die letzten paar Token und verwendet Aktivierungen von kürzlich berechneten Token wieder. Dieser Schiebefenster-Ansatz reduziert die Anzahl der E/A-Anfragen zum Laden von Gewichten und maximiert den Flash-Speicherdurchsatz.
Reduzierte Datenübertragungen: Flash Attention minimiert die hin- und hergehenden Datenübertragungen zwischen Speichertypen, wie z. B. High Bandwidth Memory (HBM) und SRAM (Static Random-Access Memory). Durch das einmalige Laden aller Daten (Abfragen, Schlüssel und Werte) wird der Overhead durch wiederholte Datenübertragungen reduziert.
Fallstudie – Optimierung der Inferenz durch spekulative Dekodierung
Eine weitere Methode zur Beschleunigung der Textgenerierung im autoregressiven Sprachmodell ist die spekulative Dekodierung. Das Hauptziel der spekulativen Dekodierung besteht darin, die Textgenerierung zu beschleunigen und gleichzeitig die Qualität des generierten Textes auf einem Niveau zu halten, das mit dem der Zielverteilung vergleichbar ist.
Bei der spekulativen Dekodierung wird ein kleines Modell/Entwurfsmodell eingeführt, das die nachfolgenden Token in der Sequenz vorhersagt, die dann vom Hauptmodell basierend auf vordefinierten Kriterien akzeptiert/abgelehnt werden. Die Integration eines kleineren Entwurfsmodells in das Zielmodell erhöht die Geschwindigkeit der Textgenerierung erheblich, was auf die Art des Speicherbedarfs zurückzuführen ist. Da das Entwurfsmodell klein ist, ist weniger Nein erforderlich. der zu ladenden Neuronengewichte und die Anzahl. Der Rechenaufwand ist jetzt im Vergleich zum Hauptmodell ebenfalls geringer, was die Latenz reduziert und den Ausgabegenerierungsprozess beschleunigt. Das Hauptmodell wertet dann die generierten Ergebnisse aus und stellt sicher, dass sie in die Zielverteilung des nächsten wahrscheinlichen Tokens passen.
Im Wesentlichen rationalisiert die spekulative Dekodierung den Textgenerierungsprozess, indem sie ein kleineres, schnelleres Entwurfsmodell nutzt, um die nachfolgenden Token vorherzusagen, wodurch die Gesamtgeschwindigkeit der Textgenerierung beschleunigt wird und gleichzeitig die Qualität des generierten Inhalts nahe an der Zielverteilung gehalten wird.
Es ist sehr wichtig, dass die von kleineren Modellen generierten Token nicht immer ständig abgelehnt werden. In diesem Fall führt dies zu einem Leistungsabfall statt zu einer Verbesserung. Durch Experimente und die Art der Anwendungsfälle können wir ein kleineres Modell auswählen/spekulative Dekodierung in den Inferenzprozess einführen.
Abschluss
Die Reise durch die fortschrittlichen Techniken zur Verbesserung des Durchsatzes des Large Language Model (LLM) beleuchtet einen Weg nach vorne im Bereich der Verarbeitung natürlicher Sprache und zeigt nicht nur die Herausforderungen, sondern auch die innovativen Lösungen auf, mit denen diese direkt bewältigt werden können. Diese Techniken, von Continuous Batching über Paged und Flash Attention bis hin zum faszinierenden Ansatz der Speculative Decoding, sind mehr als nur inkrementelle Verbesserungen. Sie stellen bedeutende Fortschritte in unserer Fähigkeit dar, große Sprachmodelle schneller, effizienter und letztendlich für eine Vielzahl von Anwendungen zugänglicher zu machen.
Die Bedeutung dieser Fortschritte kann nicht genug betont werden. Bei der Optimierung des LLM-Durchsatzes und der Verbesserung der Leistung optimieren wir nicht nur die Motoren dieser leistungsstarken Modelle; Wir definieren das Mögliche in Bezug auf Verarbeitungsgeschwindigkeit und Effizienz neu. Dies wiederum eröffnet neue Horizonte für die Anwendung großer Sprachmodelle, von Sprachübersetzungsdiensten in Echtzeit, die mit der Konversationsgeschwindigkeit arbeiten können, bis hin zu fortschrittlichen Analysetools, die riesige Datensätze mit beispielloser Geschwindigkeit verarbeiten können.
Darüber hinaus unterstreichen diese Techniken die Bedeutung eines ausgewogenen Ansatzes zur Optimierung großer Sprachmodelle – einer, der das Zusammenspiel zwischen Geschwindigkeit, Genauigkeit und Rechenressourcen sorgfältig berücksichtigt. Während wir die Grenzen der LLM-Fähigkeiten erweitern, wird die Wahrung dieses Gleichgewichts von entscheidender Bedeutung sein, um sicherzustellen, dass diese Modelle weiterhin als vielseitige und zuverlässige Werkzeuge in einer Vielzahl von Branchen dienen können.
Die fortschrittlichen Techniken zur Verbesserung des Durchsatzes großer Sprachmodelle sind mehr als nur technische Errungenschaften; Sie sind Meilensteine in der Weiterentwicklung der künstlichen Intelligenz. Sie versprechen, LLMs anpassungsfähiger, effizienter und leistungsfähiger zu machen und den Weg für zukünftige Innovationen zu ebnen, die unsere digitale Landschaft weiter verändern werden.
Lesen Sie mehr über die GPU-Architektur für die Inferenzoptimierung großer Sprachmodelle in unserem aktuellen Blogbeitrag