
Best Practices und Anwendungsfälle zum Scrapen von Daten von Websites
Veröffentlicht: 2023-12-28Beim Scrapen von Daten von einer Website ist es wichtig, die Vorschriften und Rahmenbedingungen der Zielseite zu beachten. Die Einhaltung von Best Practices ist nicht nur eine Frage der Ethik, sondern dient auch dazu, rechtliche Komplikationen zu vermeiden und die Zuverlässigkeit der Datenextraktion zu gewährleisten. Hier sind die wichtigsten Überlegungen:
- Beachten Sie robots.txt : Überprüfen Sie immer zuerst diese Datei, um zu verstehen, was der Websitebesitzer als verbotenes Scraping festgelegt hat.
- APIs nutzen : Falls verfügbar, verwenden Sie die offizielle API der Website, die eine stabilere und bewährtere Methode für den Zugriff auf Daten darstellt.
- Achten Sie auf die Anfrageraten : Übermäßiges Data Scraping kann die Website-Server belasten. Gehen Sie daher bei Ihren Anfragen mit Bedacht vor.
- Identifizieren Sie sich : Machen Sie beim Scraping durch Ihre User-Agent-Zeichenfolge Ihre Identität und Ihren Zweck transparent.
- Gehen Sie verantwortungsbewusst mit Daten um : Speichern und verwenden Sie die erfassten Daten gemäß den Datenschutzgesetzen und Datenschutzbestimmungen.
Durch die Einhaltung dieser Praktiken wird ein ethisches Scraping sichergestellt und die Integrität und Verfügbarkeit von Online-Inhalten gewahrt.
Den rechtlichen Rahmen verstehen
Beim Scrapen von Daten von einer Website ist es wichtig, die damit verbundenen rechtlichen Beschränkungen zu beachten. Zu den wichtigsten Gesetzestexten gehören:
- Der Computer Fraud and Abuse Act (CFAA): Gesetzgebung in den Vereinigten Staaten macht es illegal, ohne entsprechende Autorisierung auf einen Computer zuzugreifen.
- Datenschutz-Grundverordnung (DSGVO) der Europäischen Union : Erfordert die Zustimmung zur Nutzung personenbezogener Daten und gewährt Einzelpersonen die Kontrolle über ihre Daten.
- Der Digital Millennium Copyright Act (DMCA) : Schützt vor der Verbreitung urheberrechtlich geschützter Inhalte ohne Genehmigung.
Scraper müssen außerdem die „Nutzungsbedingungen“ von Websites respektieren, die häufig die Datenextraktion einschränken. Die Einhaltung dieser Gesetze und Richtlinien ist für die ethische und rechtliche Vernichtung von Website-Daten von entscheidender Bedeutung.
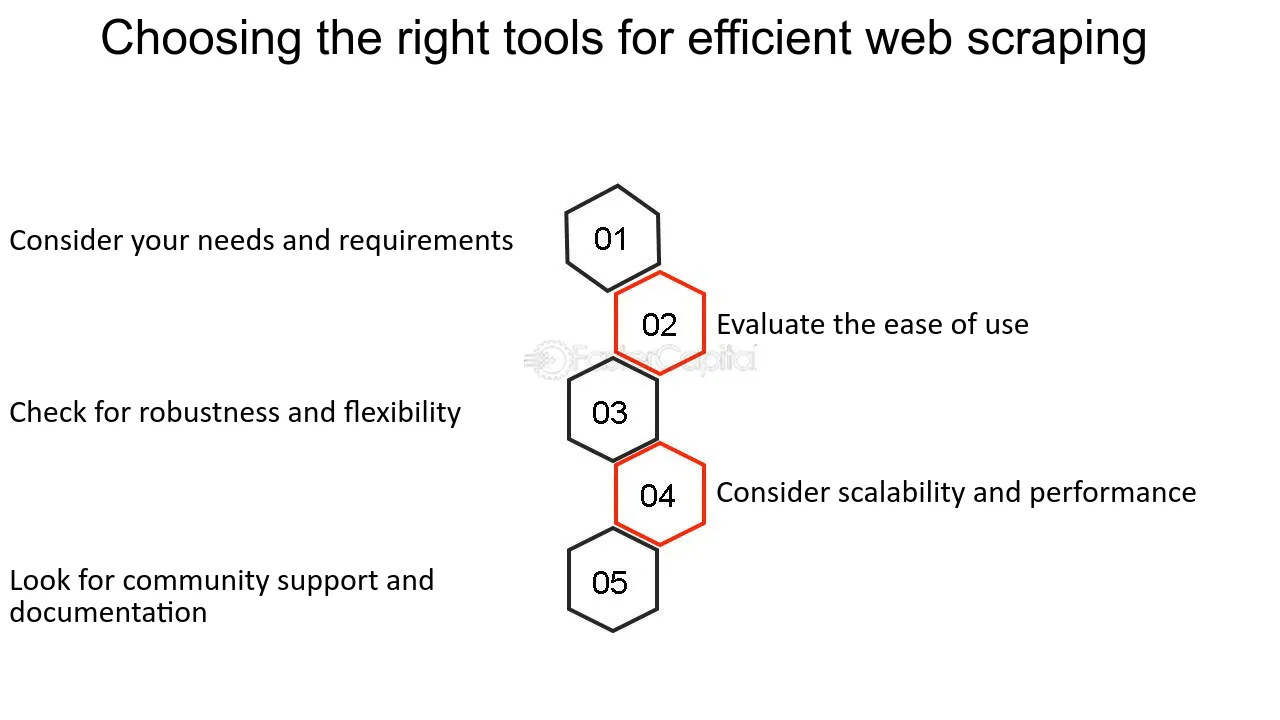
Auswahl der richtigen Werkzeuge zum Schaben
Bei der Initiierung eines Web-Scraping-Projekts ist die Auswahl der richtigen Tools von entscheidender Bedeutung. Zu den zu berücksichtigenden Faktoren gehören:
- Komplexität der Website : Dynamische Websites erfordern möglicherweise Tools wie Selenium, die mit JavaScript interagieren können.
- Datenmenge : Für großflächiges Scraping sind Tools mit verteilten Scraping-Funktionen wie Scrapy empfehlenswert.
- Legalität und Ethik : Wählen Sie Tools mit Funktionen aus, die robots.txt respektieren, und legen Sie Benutzeragentenzeichenfolgen fest.
- Benutzerfreundlichkeit : Anfänger bevorzugen möglicherweise benutzerfreundliche Schnittstellen, die in Software wie Octoparse zu finden sind.
- Programmierkenntnisse : Nicht-Programmierer tendieren möglicherweise zu Software mit grafischer Benutzeroberfläche, während Programmierer sich für Bibliotheken wie BeautifulSoup entscheiden könnten.
Bildquelle: https://fastercapital.com/
Best Practices zum effektiven Scrapen von Daten von der Website
Befolgen Sie diese Richtlinien, um Daten effizient und verantwortungsvoll von einer Website zu entfernen:
- Respektieren Sie robots.txt-Dateien und Website-Bedingungen, um rechtliche Probleme zu vermeiden.
- Verwenden Sie Header und rotierende Benutzeragenten, um menschliches Verhalten nachzuahmen.
- Implementieren Sie eine Verzögerung zwischen Anfragen, um die Serverlast zu reduzieren.
- Nutzen Sie Proxys, um IP-Verbote zu verhindern.
- Scrapen Sie außerhalb der Hauptverkehrszeiten, um Unterbrechungen der Website zu minimieren.
- Speichern Sie Daten stets effizient und vermeiden Sie doppelte Einträge.
- Stellen Sie die Richtigkeit der gecrackten Daten durch regelmäßige Überprüfungen sicher.
- Beachten Sie bei der Speicherung und Nutzung von Daten die Datenschutzgesetze.
- Halten Sie Ihre Scraping-Tools auf dem neuesten Stand, um Website-Änderungen bewältigen zu können.
- Seien Sie immer darauf vorbereitet, Scraping-Strategien anzupassen, wenn Websites ihre Struktur aktualisieren.
Branchenübergreifende Anwendungsfälle für Data Scraping
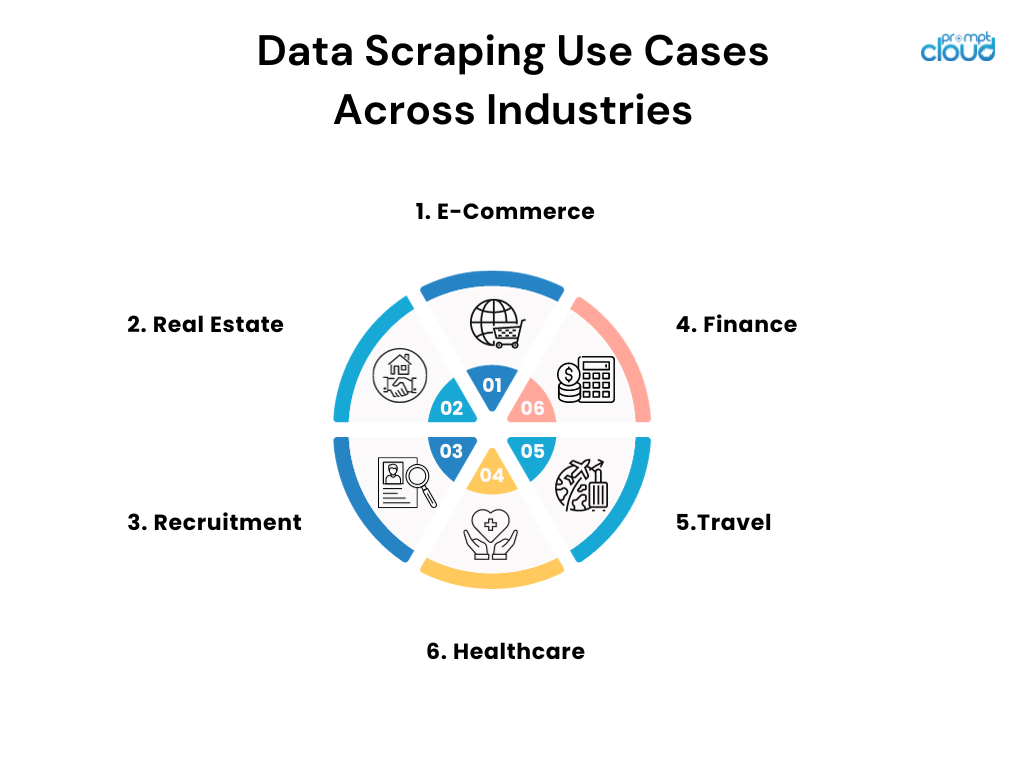
- E-Commerce: Online-Händler nutzen Scraping, um die Preise der Konkurrenz zu überwachen und ihre Preisstrategien entsprechend anzupassen.
- Immobilien: Makler und Unternehmen durchsuchen Einträge, um Immobilieninformationen, Trends und Preisdaten aus verschiedenen Quellen zusammenzufassen.
- Rekrutierung: Unternehmen durchsuchen Jobbörsen und soziale Medien, um potenzielle Kandidaten zu finden und Arbeitsmarkttrends zu analysieren.
- Finanzen: Analysten durchsuchen öffentliche Aufzeichnungen und Finanzdokumente, um Anlagestrategien zu informieren und die Marktstimmung zu verfolgen.
- Reisen: Agenturen senken die Flug- und Hotelpreise, um Kunden die bestmöglichen Angebote und Pakete anzubieten.
- Gesundheitswesen: Forscher durchsuchen medizinische Datenbanken und Fachzeitschriften, um über die neuesten Erkenntnisse und klinischen Studien auf dem Laufenden zu bleiben.
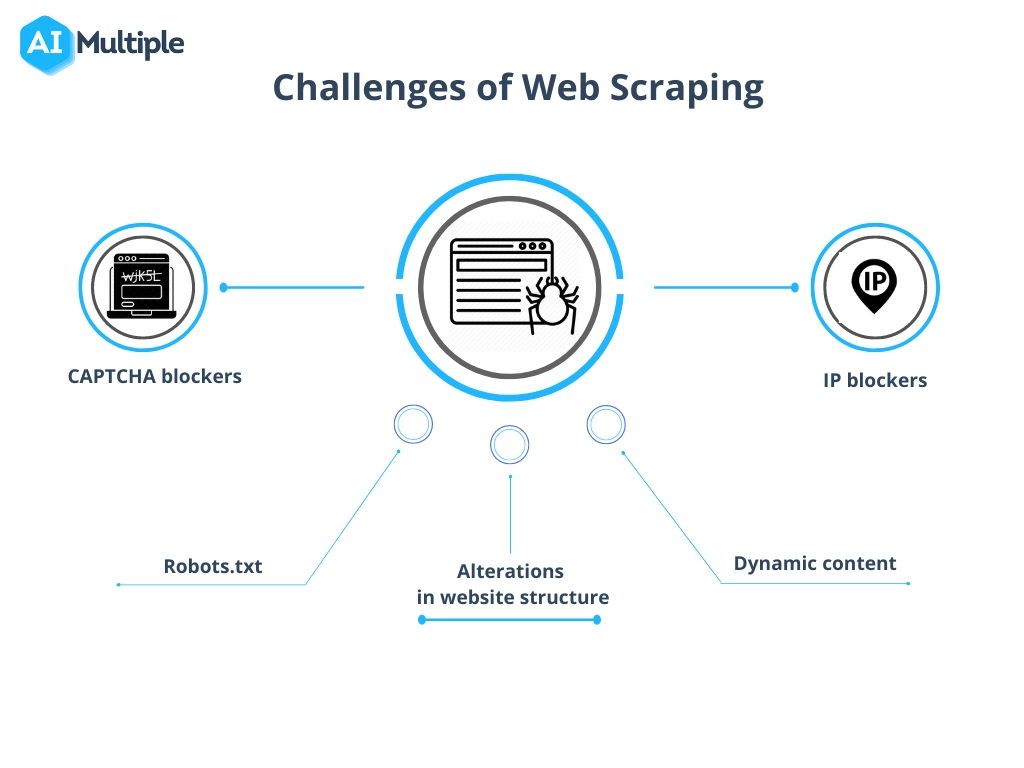
Bewältigung häufiger Herausforderungen beim Data Scraping
Der Prozess des Scrapings von Daten von einer Website ist zwar äußerst wertvoll, erfordert jedoch häufig die Überwindung von Hindernissen wie Änderungen in der Website-Struktur, Anti-Scraping-Maßnahmen und Bedenken hinsichtlich der Datenqualität.

Bildquelle: https://research.aimultiple.com/
Um diese effektiv zu navigieren:
- Bleiben Sie anpassungsfähig : Aktualisieren Sie Scraping-Skripte regelmäßig, um sie an Website-Updates anzupassen. Der Einsatz von maschinellem Lernen kann dabei helfen, sich dynamisch an strukturelle Veränderungen anzupassen.
- Respektieren Sie rechtliche Grenzen : Verstehen und befolgen Sie die Gesetzmäßigkeiten des Scrapings, um Rechtsstreitigkeiten zu vermeiden. Lesen Sie unbedingt die robots.txt-Datei und die Nutzungsbedingungen auf einer Website.
- Topform
- Menschliche Interaktion nachahmen : Websites blockieren möglicherweise Scraper, die Anfragen zu schnell senden. Implementieren Sie Verzögerungen und zufällige Intervalle zwischen Anfragen, um weniger roboterhaft zu wirken.
- Umgang mit CAPTCHAs : Es stehen Tools und Dienste zur Verfügung, mit denen CAPTCHAs gelöst oder umgangen werden können. Allerdings muss ihre Verwendung im Hinblick auf ethische und rechtliche Aspekte abgewogen werden.
- Bewahren Sie die Datenintegrität : Stellen Sie die Genauigkeit der extrahierten Daten sicher. Validieren Sie Daten regelmäßig und bereinigen Sie sie, um Qualität und Nützlichkeit aufrechtzuerhalten.
Diese Strategien helfen bei der Überwindung häufiger Scraping-Hürden und erleichtern die Extraktion wertvoller Daten.
Abschluss
Das effiziente Extrahieren von Daten aus Websites ist eine wertvolle Methode mit vielfältigen Anwendungen, die von der Marktforschung bis zur Wettbewerbsanalyse reichen. Es ist wichtig, sich an Best Practices zu halten, die Legalität sicherzustellen, die robots.txt-Richtlinien zu respektieren und die Scraping-Häufigkeit sorgfältig zu kontrollieren, um eine Serverüberlastung zu verhindern.
Die verantwortungsvolle Anwendung dieser Methoden öffnet die Tür zu reichhaltigen Datenquellen, die umsetzbare Erkenntnisse liefern und fundierte Entscheidungen für Unternehmen und Einzelpersonen gleichermaßen fördern können. Die ordnungsgemäße Umsetzung gepaart mit ethischen Überlegungen stellt sicher, dass Data Scraping ein leistungsstarkes Werkzeug in der digitalen Landschaft bleibt.
Sind Sie bereit, Ihre Erkenntnisse zu erweitern, indem Sie Daten von der Website extrahieren? Suchen Sie nicht weiter! PromptCloud bietet ethische und zuverlässige Web-Scraping-Dienste, die auf Ihre Bedürfnisse zugeschnitten sind. Kontaktieren Sie uns unter sales@promptcloud.com, um Rohdaten in verwertbare Informationen umzuwandeln. Lassen Sie uns gemeinsam Ihre Entscheidungsfindung verbessern!
Häufig gestellte Fragen
Ist es akzeptabel, Daten von Websites zu extrahieren?
Daten-Scraping ist auf jeden Fall in Ordnung, aber Sie müssen sich an die Regeln halten. Bevor Sie sich in ein Scraping-Abenteuer stürzen, werfen Sie einen genauen Blick auf die Nutzungsbedingungen und die robots.txt-Datei der betreffenden Website. Ein gewisser Respekt vor dem Layout der Website, die Einhaltung von Häufigkeitsgrenzen und die Wahrung ethischer Grundsätze sind allesamt der Schlüssel zu verantwortungsvollem Data-Scraping-Praktiken.
Wie kann ich Benutzerdaten durch Scraping von einer Website extrahieren?
Das Extrahieren von Benutzerdaten durch Scraping erfordert einen sorgfältigen Ansatz im Einklang mit rechtlichen und ethischen Normen. Wann immer möglich, wird für den Datenabruf die Nutzung öffentlich verfügbarer APIs empfohlen, die von der Website bereitgestellt werden. Wenn keine API vorhanden ist, muss unbedingt sichergestellt werden, dass die verwendeten Scraping-Methoden den Datenschutzgesetzen, Nutzungsbedingungen und den auf der Website festgelegten Richtlinien entsprechen, um mögliche rechtliche Konsequenzen abzumildern
Gilt das Scrapen von Website-Daten als illegal?
Die Rechtmäßigkeit von Web Scraping hängt von mehreren Faktoren ab, darunter dem Zweck, der Methodik und der Einhaltung einschlägiger Gesetze. Obwohl Web Scraping an sich nicht grundsätzlich illegal ist, können unbefugter Zugriff, ein Verstoß gegen die Nutzungsbedingungen einer Website oder die Missachtung von Datenschutzgesetzen rechtliche Konsequenzen nach sich ziehen. Verantwortungsvolles und ethisches Verhalten bei Web-Scraping-Aktivitäten ist von größter Bedeutung und erfordert ein ausgeprägtes Bewusstsein für rechtliche Grenzen und ethische Überlegungen.
Können Websites Fälle von Web Scraping erkennen?
Websites haben Mechanismen implementiert, um Web-Scraping-Aktivitäten zu erkennen und zu verhindern und Elemente wie User-Agent-Strings, IP-Adressen und Anforderungsmuster zu überwachen. Um die Erkennung zu verringern, umfassen Best Practices den Einsatz von Techniken wie rotierenden Benutzeragenten, der Verwendung von Proxys und der Implementierung zufälliger Verzögerungen zwischen Anfragen. Es ist jedoch wichtig zu beachten, dass Versuche, Erkennungsmaßnahmen zu umgehen, gegen die Nutzungsbedingungen einer Website verstoßen und möglicherweise rechtliche Konsequenzen nach sich ziehen können. Verantwortungsvolle und ethische Web-Scraping-Praktiken legen Wert auf Transparenz und die Einhaltung rechtlicher und ethischer Standards.