
Datenextraktion aus dynamischen Websites: Herausforderungen und Lösungen
Veröffentlicht: 2023-11-23Das Internet beherbergt ein umfangreiches und ständig wachsendes Datenreservoir, das für Unternehmen, Forscher und Einzelpersonen, die Erkenntnisse, fundierte Entscheidungen oder innovative Lösungen suchen, von enormem Wert ist. Ein erheblicher Teil dieser unschätzbar wertvollen Informationen befindet sich jedoch auf dynamischen Websites.
Im Gegensatz zu herkömmlichen statischen Websites generieren dynamische Websites dynamisch Inhalte als Reaktion auf Benutzerinteraktionen oder externe Ereignisse. Diese Websites nutzen Technologien wie JavaScript, um den Inhalt von Webseiten zu manipulieren, was eine enorme Herausforderung für herkömmliche Web-Scraping-Techniken zur effektiven Datenextraktion darstellt.
In diesem Artikel werden wir uns eingehend mit dem Bereich des dynamischen Webseiten-Scrapings befassen. Wir untersuchen die typischen Herausforderungen, die mit diesem Prozess verbunden sind, und stellen effektive Strategien und Best Practices zur Überwindung dieser Hürden vor.
Dynamische Websites verstehen
Bevor wir uns mit den Feinheiten des dynamischen Webseiten-Scrapings befassen, ist es wichtig, ein klares Verständnis davon zu entwickeln, was eine dynamische Website auszeichnet. Im Gegensatz zu statischen Gegenstücken, die überall einheitliche Inhalte bereitstellen, generieren dynamische Websites Inhalte dynamisch basierend auf verschiedenen Parametern wie Benutzerpräferenzen, Suchanfragen oder Echtzeitdaten.
Dynamische Websites nutzen oft ausgefeilte JavaScript-Frameworks, um den Inhalt der Webseite auf der Clientseite dynamisch zu ändern und zu aktualisieren. Während dieser Ansatz die Benutzerinteraktivität erheblich verbessert, bringt er Herausforderungen mit sich, wenn versucht wird, Daten programmgesteuert zu extrahieren.
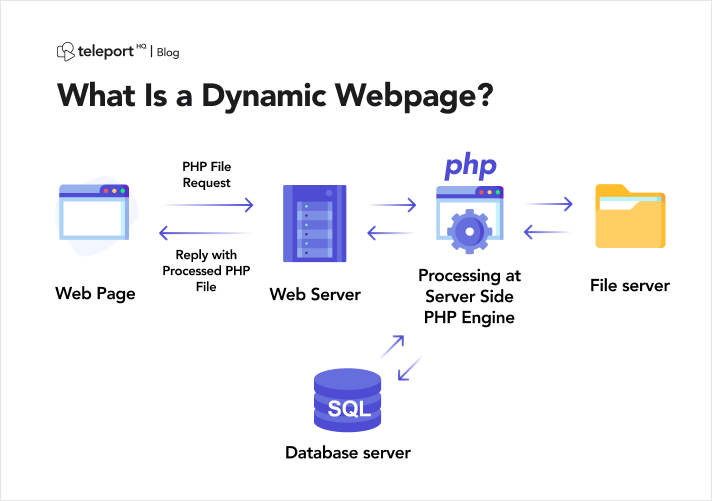
Bildquelle: https://teleporthq.io/
Häufige Herausforderungen beim dynamischen Webseiten-Scraping
Dynamisches Webseiten-Scraping stellt aufgrund der dynamischen Natur des Inhalts mehrere Herausforderungen dar. Zu den häufigsten Herausforderungen gehören:
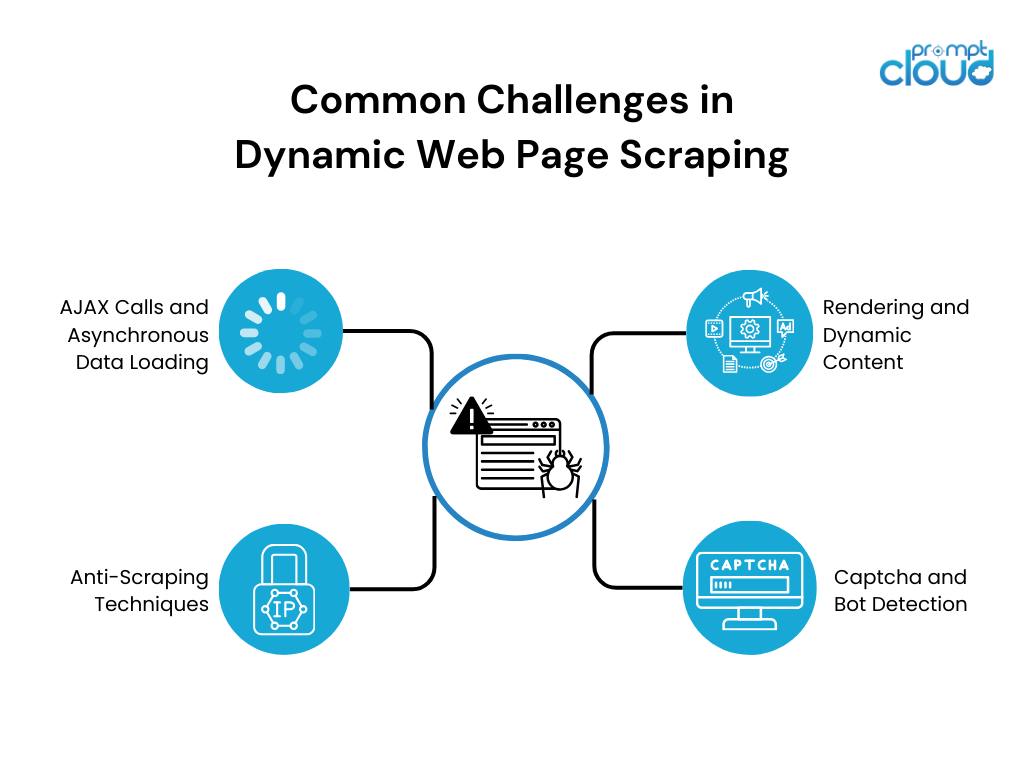
- Rendering und dynamischer Inhalt: Dynamische Websites sind stark auf JavaScript angewiesen, um Inhalte dynamisch darzustellen. Herkömmliche Web-Scraping-Tools haben Schwierigkeiten, mit JavaScript-gesteuerten Inhalten zu interagieren, was zu einer unvollständigen oder falschen Datenextraktion führt.
- AJAX-Aufrufe und asynchrones Laden von Daten: Viele dynamische Websites verwenden asynchrone JavaScript- und XML-Aufrufe (AJAX), um Daten von Webservern abzurufen, ohne die gesamte Seite neu zu laden. Dieses asynchrone Laden der Daten kann es schwierig machen, den gesamten Datensatz zu extrahieren, da er möglicherweise nach und nach geladen wird oder durch Benutzerinteraktionen ausgelöst wird.
- Captcha- und Bot-Erkennung: Um Scraping zu verhindern und Daten zu schützen, setzen Websites verschiedene Gegenmaßnahmen wie Captchas und Bot-Erkennungsmechanismen ein. Diese Sicherheitsmaßnahmen behindern Scraping-Bemühungen und erfordern zusätzliche Strategien zur Bewältigung.
- Anti-Scraping-Techniken: Websites nutzen verschiedene Anti-Scraping-Techniken wie IP-Blockierung, Ratenbegrenzung oder verschleierte HTML-Strukturen, um Scraper abzuschrecken. Diese Techniken erfordern adaptive Scraping-Strategien, um einer Erkennung zu entgehen und die gewünschten Daten erfolgreich zu scrapen.
Strategien für erfolgreiches dynamisches Webseiten-Scraping
Trotz der Herausforderungen gibt es mehrere Strategien und Techniken, mit denen die Hindernisse beim Scraping dynamischer Webseiten überwunden werden können. Zu diesen Strategien gehören:
- Verwendung von Headless-Browsern: Headless-Browser wie Puppeteer oder Selenium ermöglichen die Ausführung von JavaScript und die Darstellung dynamischer Inhalte und ermöglichen so die genaue Extraktion von Daten aus dynamischen Websites.
- Untersuchen des Netzwerkverkehrs: Die Analyse des Netzwerkverkehrs kann Einblicke in den Datenfluss innerhalb einer dynamischen Website liefern. Dieses Wissen kann genutzt werden, um AJAX-Aufrufe zu identifizieren, Antworten abzufangen und die erforderlichen Daten zu extrahieren.
- Dynamisches Content-Parsing: Das Parsen des HTML-DOM, nachdem der dynamische Inhalt durch JavaScript gerendert wurde, kann beim Extrahieren der gewünschten Daten hilfreich sein. Tools wie Beautiful Soup oder Cheerio können zum Parsen und Extrahieren von Daten aus dem aktualisierten DOM verwendet werden.
- IP-Rotation und Proxys: Durch die Rotation von IP-Adressen und die Verwendung von Proxys können IP-Blockierungs- und Ratenbegrenzungsherausforderungen überwunden werden. Es ermöglicht verteiltes Scraping und verhindert, dass Websites den Scraper als einzelne Quelle identifizieren.
- Umgang mit Captchas und Anti-Scraping-Techniken: Bei Captchas kann der Einsatz von Captcha-Lösungsdiensten oder die Implementierung menschlicher Emulation dabei helfen, diese Maßnahmen zu umgehen. Darüber hinaus können verschleierte HTML-Strukturen mithilfe von Techniken wie DOM-Traversal oder Mustererkennung rückentwickelt werden.
Best Practices für dynamisches Web Scraping
Beim Scraping dynamischer Webseiten ist es wichtig, bestimmte Best Practices zu befolgen, um einen erfolgreichen und ethischen Scraping-Prozess sicherzustellen. Zu den Best Practices gehören:

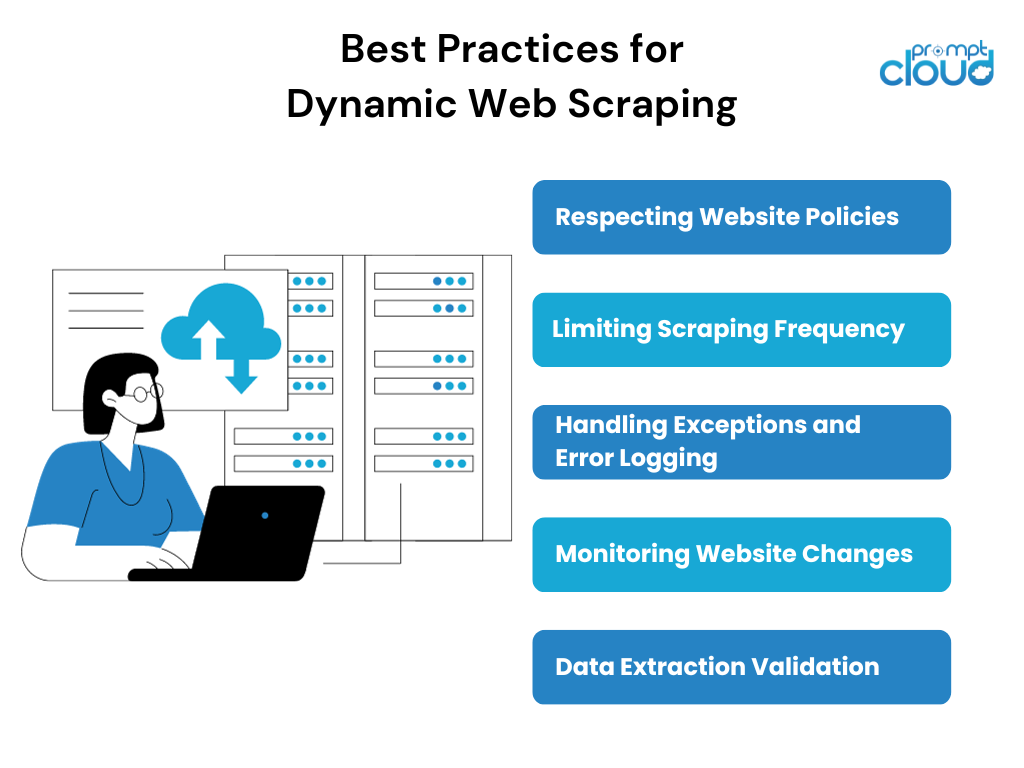
- Einhaltung der Website-Richtlinien: Vor dem Scraping einer Website ist es wichtig, die Nutzungsbedingungen der Website, die robots.txt-Datei und alle genannten spezifischen Scraping-Richtlinien zu lesen und zu respektieren.
- Begrenzung der Scraping-Häufigkeit: Übermäßiges Scraping kann sowohl die Ressourcen des Scrapers als auch die Website, die gescrapt wird, belasten. Die Implementierung angemessener Scraping-Häufigkeitsgrenzen und die Berücksichtigung der von der Website festgelegten Ratengrenzen können dazu beitragen, einen harmonischen Scraping-Prozess aufrechtzuerhalten.
- Umgang mit Ausnahmen und Fehlerprotokollierung: Beim dynamischen Web-Scraping geht es um den Umgang mit unvorhersehbaren Szenarien wie Netzwerkfehlern, Captcha-Anfragen oder Änderungen in der Website-Struktur. Die Implementierung geeigneter Ausnahmebehandlungs- und Fehlerprotokollierungsmechanismen hilft dabei, diese Probleme zu identifizieren und zu beheben.
- Überwachen von Website-Änderungen: Dynamische Websites werden häufig aktualisiert oder neu gestaltet, wodurch bestehende Scraping-Skripte beschädigt werden können. Eine regelmäßige Überwachung der Zielwebsite auf etwaige Änderungen und eine zeitnahe Anpassung der Scraping-Strategie können eine unterbrechungsfreie Datenextraktion gewährleisten.
- Validierung der Datenextraktion: Die Validierung und Querverweise der extrahierten Daten mit der Benutzeroberfläche der Website können dazu beitragen, die Richtigkeit und Vollständigkeit der extrahierten Informationen sicherzustellen. Dieser Validierungsschritt ist besonders wichtig, wenn dynamische Webseiten mit sich entwickelnden Inhalten gescannt werden.
Abschluss
Die Leistungsfähigkeit des dynamischen Webseiten-Scrapings eröffnet eine Welt voller Möglichkeiten, auf wertvolle Daten zuzugreifen, die in dynamischen Websites verborgen sind. Die Bewältigung der mit dem Scraping dynamischer Websites verbundenen Herausforderungen erfordert eine Kombination aus technischem Fachwissen und der Einhaltung ethischer Scraping-Praktiken.
Durch das Verständnis der Feinheiten des dynamischen Webseiten-Scrapings und die Umsetzung der in diesem Artikel beschriebenen Strategien und Best Practices können Unternehmen und Einzelpersonen das volle Potenzial von Webdaten ausschöpfen und sich in verschiedenen Bereichen einen Wettbewerbsvorteil verschaffen.
Eine weitere Herausforderung beim dynamischen Webseiten-Scraping ist die Menge der Daten, die extrahiert werden müssen. Dynamische Webseiten enthalten oft eine große Menge an Informationen, was es schwierig macht, relevante Daten effizient zu extrahieren und zu extrahieren.
Um diese Hürde zu überwinden, können Unternehmen die Expertise von Web-Scraping-Dienstleistern nutzen. Die leistungsstarke Scraping-Infrastruktur und die fortschrittlichen Datenextraktionstechniken von PromptCloud ermöglichen es Unternehmen, große Scraping-Projekte problemlos abzuwickeln.
Mit der Unterstützung von PromptCloud können Unternehmen wertvolle Erkenntnisse aus dynamischen Webseiten extrahieren und diese in umsetzbare Informationen umwandeln. Erleben Sie noch heute die Leistungsfähigkeit des dynamischen Webseiten-Scrapings durch eine Partnerschaft mit PromptCloud. Kontaktieren Sie uns unter sales@promptcloud.com.