
Dynamisches Webseiten-Scraping mit Python – Anleitung
Veröffentlicht: 2024-06-08Beim dynamischen Web-Scraping werden Daten von Websites abgerufen, die Inhalte in Echtzeit über JavaScript oder Python generieren. Im Gegensatz zu statischen Webseiten werden dynamische Inhalte asynchron geladen, was herkömmliche Scraping-Techniken ineffizient macht.
Dynamisches Web-Scraping verwendet:
- AJAX-basierte Websites
- Single-Page-Anwendungen (SPAs)
- Websites mit verzögerten Ladeelementen
Wichtige Tools und Technologien:
- Selenium – Automatisiert Browserinteraktionen.
- BeautifulSoup – Analysiert HTML-Inhalte.
- Anfragen – Ruft Webseiteninhalte ab.
- lxml – Analysiert XML und HTML.
Dynamisches Web-Scraping mit Python erfordert ein tieferes Verständnis der Web-Technologien, um effektiv Echtzeitdaten zu sammeln.
Bildquelle: https://www.scrapehero.com/scrape-a-dynamic-website/
Einrichten einer Python-Umgebung
Um mit dem dynamischen Web-Scraping in Python zu beginnen, ist es wichtig, die Umgebung richtig einzurichten. Folge diesen Schritten:
- Python installieren : Stellen Sie sicher, dass Python auf dem Computer installiert ist. Die neueste Version kann von der offiziellen Python-Website heruntergeladen werden.
- Erstellen Sie eine virtuelle Umgebung :

Aktivieren Sie die virtuelle Umgebung:

- Erforderliche Bibliotheken installieren :

- Richten Sie einen Code-Editor ein : Verwenden Sie eine IDE wie PyCharm, VSCode oder Jupyter Notebook zum Schreiben und Ausführen von Skripten.
- Machen Sie sich mit HTML/CSS vertraut : Das Verständnis der Webseitenstruktur hilft beim effektiven Navigieren und Extrahieren von Daten.
Diese Schritte bilden eine solide Grundlage für dynamische Web-Scraping-Python-Projekte.
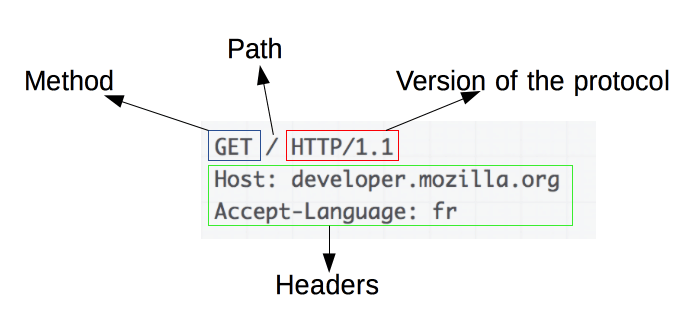
Die Grundlagen von HTTP-Anfragen verstehen
Bildquelle: https://developer.mozilla.org/en-US/docs/Web/HTTP/Overview
HTTP-Anfragen sind die Grundlage des Web Scraping. Wenn ein Client, wie ein Webbrowser oder ein Web Scraper, Informationen von einem Server abrufen möchte, sendet er eine HTTP-Anfrage. Diese Anfragen folgen einer bestimmten Struktur:
- Methode : Die auszuführende Aktion, z. B. GET oder POST.
- URL : Die Adresse der Ressource auf dem Server.
- Header : Metadaten zur Anfrage, wie Inhaltstyp und Benutzeragent.
- Text : Optionale Daten, die mit der Anfrage gesendet werden und normalerweise mit POST verwendet werden.
Für ein effektives Web Scraping ist es wichtig zu verstehen, wie diese Komponenten interpretiert und konstruiert werden. Python-Bibliotheken wie Anfragen vereinfachen diesen Prozess und ermöglichen eine präzise Kontrolle über Anfragen.
Installieren von Python-Bibliotheken
Bildquelle: https://ajaytech.co/what-are-python-libraries/
Stellen Sie für dynamisches Web-Scraping mit Python sicher, dass Python installiert ist. Öffnen Sie das Terminal oder die Eingabeaufforderung und installieren Sie die erforderlichen Bibliotheken mit pip:
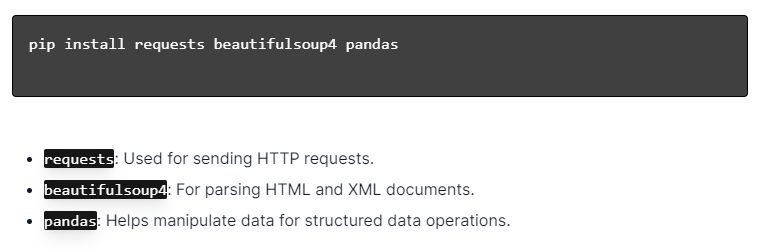
Als nächstes importieren Sie diese Bibliotheken in Ihr Skript:

Auf diese Weise wird jede Bibliothek für Web-Scraping-Aufgaben wie das Senden von Anfragen, das Parsen von HTML und die effiziente Datenverwaltung verfügbar gemacht.
Erstellen eines einfachen Web-Scraping-Skripts
Um ein einfaches dynamisches Web-Scraping-Skript in Python zu erstellen, müssen zunächst die erforderlichen Bibliotheken installiert werden. Die „requests“-Bibliothek verarbeitet HTTP-Anfragen, während „BeautifulSoup“ HTML-Inhalte analysiert.
Schritte zum folgen:
- Abhängigkeiten installieren:

- Bibliotheken importieren:

- Holen Sie sich HTML-Inhalt:
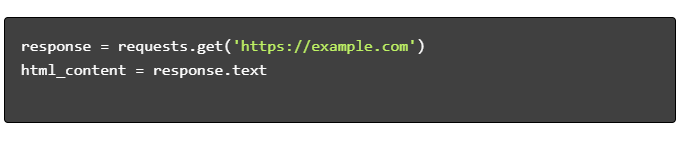
- HTML analysieren:

- Daten extrahieren:

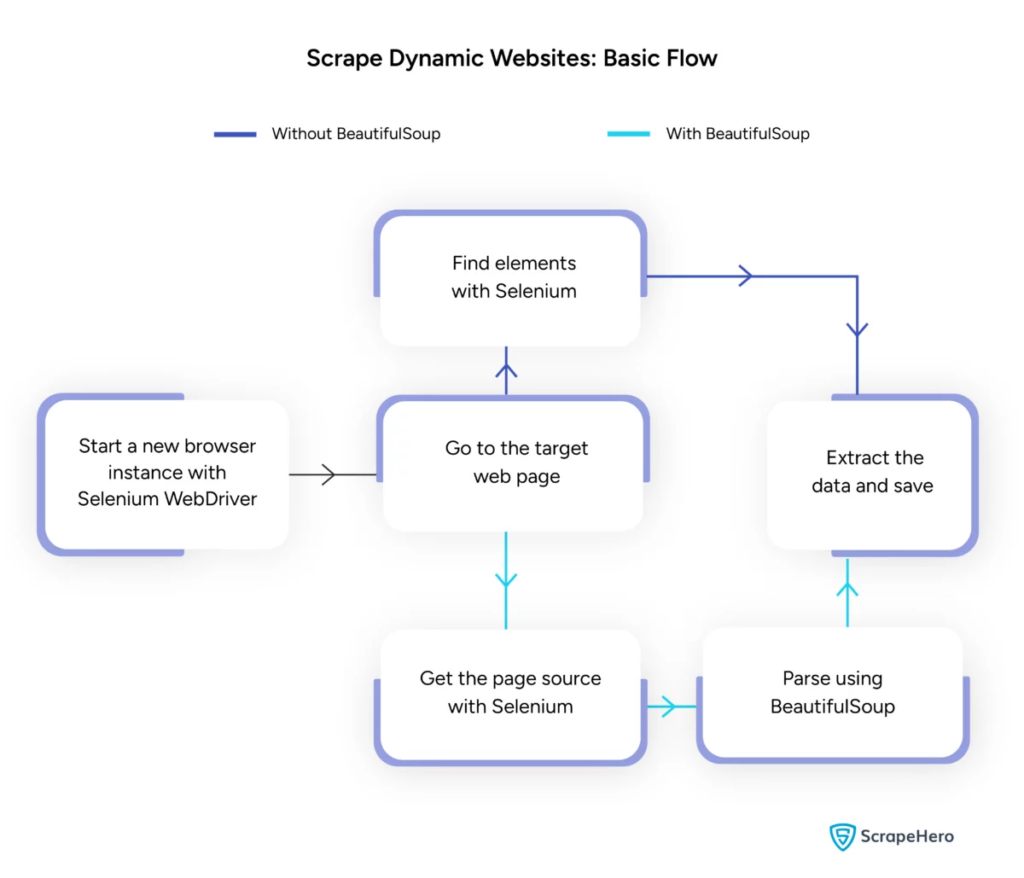
Umgang mit dynamischem Web Scraping mit Python
Dynamische Websites generieren Inhalte im Handumdrehen und erfordern oft ausgefeiltere Techniken.

Betrachten Sie die folgenden Schritte:
- Zielelemente identifizieren : Untersuchen Sie die Webseite, um dynamische Inhalte zu finden.
- Wählen Sie ein Python-Framework : Nutzen Sie Bibliotheken wie Selenium oder Playwright.
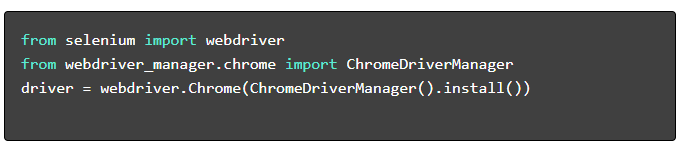
- Erforderliche Pakete installieren :
- WebDriver einrichten :

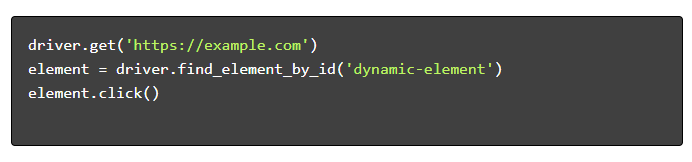
- Navigieren und interagieren :
Best Practices für Web Scraping
Es wird empfohlen, die Best Practices für Web Scraping zu befolgen, um Effizienz und Rechtmäßigkeit sicherzustellen. Nachfolgend finden Sie wichtige Richtlinien und Strategien zur Fehlerbehandlung:
- Respektieren Sie Robots.txt : Überprüfen Sie immer die robots.txt-Datei der Zielseite.
- Drosselung : Implementieren Sie Verzögerungen, um eine Serverüberlastung zu verhindern.
- User-Agent : Verwenden Sie eine benutzerdefinierte User-Agent-Zeichenfolge, um potenzielle Blockaden zu vermeiden.
- Wiederholungslogik : Verwenden Sie Try-Exception-Blöcke und richten Sie eine Wiederholungslogik für die Behandlung von Server-Timeouts ein.
- Protokollierung : Führen Sie umfassende Protokolle zum Debuggen.
- Ausnahmebehandlung : Netzwerkfehler, HTTP-Fehler und Analysefehler werden gezielt abgefangen.
- Captcha-Erkennung : Integrieren Sie Strategien zum Erkennen und Lösen oder Umgehen von CAPTCHAs.
Häufige Herausforderungen beim dynamischen Web Scraping
Captchas
Viele Websites verwenden CAPTCHAs, um automatisierte Bots zu verhindern. Um dies zu umgehen:
- Nutzen Sie CAPTCHA-Lösungsdienste wie 2Captcha.
- Implementieren Sie menschliches Eingreifen zur CAPTCHA-Lösung.
- Verwenden Sie Proxys, um die Anfrageraten zu begrenzen.
IP-Blockierung
Websites blockieren möglicherweise IP-Adressen, die zu viele Anfragen stellen. Wirken Sie dem entgegen, indem Sie:
- Verwendung rotierender Proxys.
- Implementierung der Anforderungsdrosselung.
- Einsatz von User-Agent-Rotationsstrategien.
JavaScript-Rendering
Einige Websites laden Inhalte über JavaScript. Gehen Sie diese Herausforderung an, indem Sie:
- Verwendung von Selenium oder Puppeteer zur Browser-Automatisierung.
- Verwendung von Scrapy-Splash zum Rendern dynamischer Inhalte.
- Erkundung kopfloser Browser zur Interaktion mit JavaScript.
Rechtsfragen
Web Scraping kann manchmal gegen die Nutzungsbedingungen verstoßen. Stellen Sie die Einhaltung sicher, indem Sie:
- Rechtsberatung.
- Scraping öffentlich zugänglicher Daten.
- Berücksichtigung der robots.txt-Anweisungen.
Datenanalyse
Der Umgang mit inkonsistenten Datenstrukturen kann eine Herausforderung sein. Zu den Lösungen gehören:
- Verwendung von Bibliotheken wie BeautifulSoup für die HTML-Analyse.
- Verwendung regulärer Ausdrücke zur Textextraktion.
- Verwendung von JSON- und XML-Parsern für strukturierte Daten.
Speichern und Analysieren von Scraped-Daten
Das Speichern und Analysieren von Scraping-Daten sind entscheidende Schritte beim Web Scraping. Die Entscheidung, wo die Daten gespeichert werden sollen, hängt vom Volumen und Format ab. Zu den gängigen Speicheroptionen gehören:
- CSV-Dateien : Einfach für kleine Datensätze und einfache Analysen.
- Datenbanken : SQL-Datenbanken für strukturierte Daten; NoSQL für unstrukturiert.
Nach der Speicherung können Daten mithilfe von Python-Bibliotheken analysiert werden:
- Pandas : Ideal für die Datenmanipulation und -bereinigung.
- NumPy : Effizient für numerische Operationen.
- Matplotlib und Seaborn : Geeignet für die Datenvisualisierung.
- Scikit-learn : Bietet Tools für maschinelles Lernen.
Eine ordnungsgemäße Datenspeicherung und -analyse verbessert die Datenzugänglichkeit und Erkenntnisse.
Fazit und nächste Schritte
Nach dem Durchlaufen eines dynamischen Web-Scraping-Python ist es unbedingt erforderlich, das Verständnis der hervorgehobenen Tools und Bibliotheken zu verfeinern.
- Überprüfen Sie den Code : Konsultieren Sie das endgültige Skript und modularisieren Sie es, wo möglich, um die Wiederverwendbarkeit zu verbessern.
- Zusätzliche Bibliotheken : Entdecken Sie erweiterte Bibliotheken wie Scrapy oder Splash für komplexere Anforderungen.
- Datenspeicherung : Erwägen Sie robuste Speicheroptionen – SQL-Datenbanken oder Cloud-Speicher für die Verwaltung großer Datensätze.
- Rechtliche und ethische Überlegungen : Bleiben Sie über rechtliche Richtlinien zum Web Scraping auf dem Laufenden, um mögliche Verstöße zu vermeiden.
- Nächste Projekte : Die Bewältigung neuer Web-Scraping-Projekte mit unterschiedlicher Komplexität wird diese Fähigkeiten weiter festigen.
Möchten Sie professionelles dynamisches Web-Scraping mit Python in Ihr Projekt integrieren? Für Teams, die eine Datenextraktion in großem Maßstab ohne die Komplexität ihrer internen Handhabung benötigen, bietet PromptCloud maßgeschneiderte Lösungen. Entdecken Sie die Dienste von PromptCloud für eine robuste, zuverlässige Lösung. Kontaktiere uns heute!