
Explorative Faktorenanalyse in R
Veröffentlicht: 2017-02-16Was ist die explorative Faktorenanalyse in R?
Die explorative Faktorenanalyse (EFA) oder grob bekannt als Faktorenanalyse in R ist eine statistische Technik, die verwendet wird, um die latente relationale Struktur zwischen einer Reihe von Variablen zu identifizieren und auf eine kleinere Anzahl von Variablen einzugrenzen. Dies bedeutet im Wesentlichen, dass die Varianz einer großen Anzahl von Variablen durch wenige zusammenfassende Variablen, dh Faktoren, beschrieben werden kann. Hier ist ein Überblick über die explorative Faktorenanalyse in R.
Wie der Name schon sagt, ist EFA explorativer Natur – wir kennen die latenten Variablen nicht wirklich, und die Schritte werden wiederholt, bis wir zu einer geringeren Anzahl von Faktoren gelangen. In diesem Lernprogramm sehen wir uns EFA mit R an. Lassen Sie uns nun zunächst die Grundidee des Datensatzes verstehen.
1. Die Daten
Dieser Datensatz enthält 90 Antworten für 14 verschiedene Variablen, die Kunden beim Autokauf berücksichtigen. Die Fragen der Umfrage wurden anhand einer 5-Punkte-Likert-Skala formuliert, wobei 1 sehr niedrig und 5 sehr hoch bedeutet. Die Variablen waren die folgenden:
- Preis
- Sicherheit
- Äußeres Aussehen
- Platz und Komfort
- Technologie
- Kundendienst
- Wiederverkaufswert
- Treibstoffart
- Kraftstoffeffizienz
- Farbe
- Wartung
- Probefahrt
- Produktrezensionen
- Referenzen
Klicken Sie hier, um den codierten Datensatz herunterzuladen.
2. Webdaten importieren
Jetzt lesen wir den im CSV-Format vorliegenden Datensatz in R ein und speichern ihn als Variable.
[code language=”r”] data <- read.csv(file.choose( ),header=TRUE) [/code]
Es öffnet sich ein Fenster zur Auswahl der CSV-Datei und die Option „Header“ stellt sicher, dass die erste Zeile der Datei als Header betrachtet wird. Geben Sie Folgendes ein, um die ersten Zeilen des Datenrahmens anzuzeigen und zu bestätigen, dass die Daten korrekt gespeichert wurden.
[code language="r"] Kopf(daten) [/code]
3. Paketinstallation
Jetzt installieren wir die erforderlichen Pakete, um weitere Analysen durchzuführen. Diese Pakete sind `psych` und `GPArotation`. Im unten angegebenen Code rufen wir `install.packages()` für die Installation auf.
[code language=”r”] install.packages('psych') install.packages('GPArotation') [/code]
4. Anzahl der Faktoren
Als Nächstes ermitteln wir die Anzahl der Faktoren, die wir für die Faktorenanalyse auswählen. Diese wird über Methoden wie „Parallelanalyse“ und „Eigenwert“ usw. ausgewertet.
Parallele Analyse
Wir verwenden die Funktion `fa.parallel` des Psych-Pakets, um die parallele Analyse auszuführen. Hier geben wir den Datenrahmen und die Faktormethode (in unserem Fall „minres“) an. Führen Sie Folgendes aus, um eine akzeptable Anzahl von Faktoren zu finden und das „Screeplot“ zu erstellen:
[code language="r"] parallel <- fa.parallel(data, fm = 'minres', fa = 'fa') [/code]
Die Konsole würde die maximale Anzahl von Faktoren anzeigen, die wir berücksichtigen können. So würde es aussehen.
„Parallelanalyse legt nahe, dass die Anzahl der Faktoren = 5 und die Anzahl der Komponenten = NA“
Unten in dem aus dem obigen Code generierten "Scree Plot" angegeben:
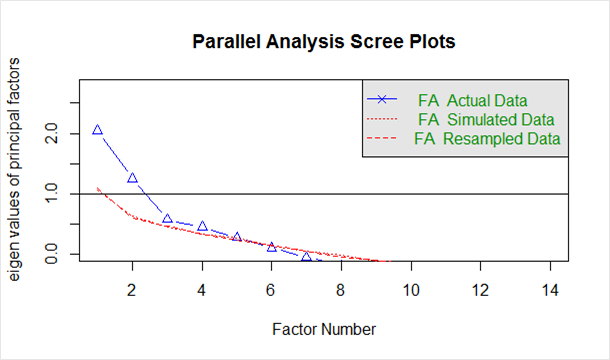
Die blaue Linie zeigt Eigenwerte der tatsächlichen Daten und die beiden roten Linien (übereinander gelegt) zeigen simulierte und neu abgetastete Daten. Hier sehen wir uns die großen Einbrüche in den tatsächlichen Daten an und erkennen den Punkt, an dem sie nach rechts abflachen. Außerdem lokalisieren wir den Wendepunkt – den Punkt, an dem die Lücke zwischen simulierten Daten und tatsächlichen Daten tendenziell minimal ist.

Wenn Sie sich dieses Diagramm und die parallele Analyse ansehen, wären 2 bis 5 Faktoren eine gute Wahl.
Faktorenanalyse
Da wir nun bei einer wahrscheinlichen Anzahl von Faktoren angelangt sind, beginnen wir mit 3 als Anzahl der Faktoren. Um eine Faktorenanalyse durchzuführen, verwenden wir die Funktion „fa()“ des „psych“-Pakets. Nachfolgend sind die Argumente aufgeführt, die wir liefern:
- r – Rohdaten oder Korrelations- oder Kovarianzmatrix
- nfactors – Anzahl der zu extrahierenden Faktoren
- Rotation – Obwohl es verschiedene Arten von Rotationen gibt, sind „Varimax“ und „Oblimin“ die beliebtesten
- fm – Eine der Faktorextraktionstechniken wie „Minimum Residual (OLS)“, „Maximum Liklihood“, „Principal Axis“ usw.
In diesem Fall wählen wir die schräge Rotation (rotieren = „oblimin“), da wir glauben, dass es eine Korrelation zwischen den Faktoren gibt. Beachten Sie, dass die Varimax-Rotation unter der Annahme verwendet wird, dass die Faktoren vollständig unkorreliert sind. Wir werden die „Ordinary Least Squared/Minres“-Faktorisierung (fm = „minres“) verwenden, da sie bekanntermaßen ähnliche Ergebnisse wie „Maximum Likelihood“ liefert, ohne eine multivariate Normalverteilung anzunehmen, und Lösungen durch iterative Eigenzerlegung wie eine Hauptachse ableitet.
Führen Sie Folgendes aus, um die Analyse zu starten.
[code language=”r”] threefactor <- fa(data,nfactors = 3, rotieren = „oblimin“,fm=“minres“) print(dreifaktor) [/code]
Hier ist die Ausgabe mit Faktoren und Ladungen:
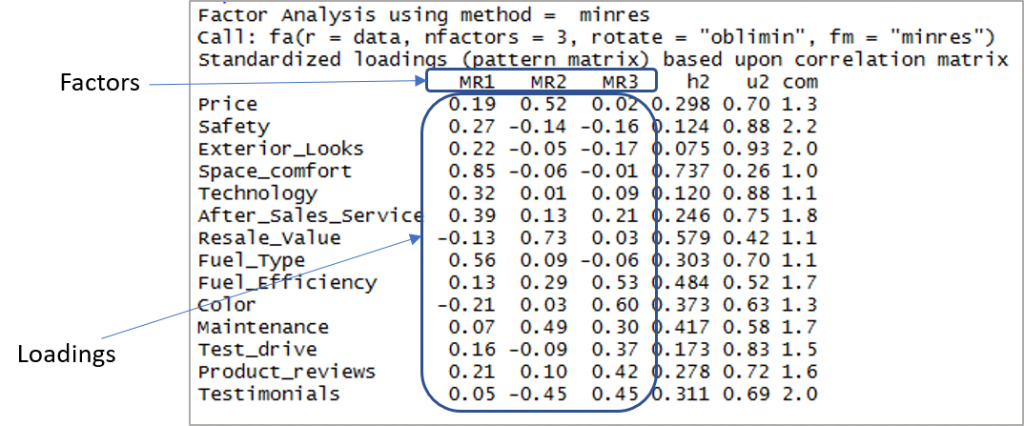
Jetzt müssen wir die Ladungen von mehr als 0,3 berücksichtigen und nicht auf mehr als einen Faktor laden. Beachten Sie, dass negative Werte hier akzeptabel sind. Legen wir also zunächst den Cut-Off fest, um die Sichtbarkeit zu verbessern.
[code language="r"] print(dreifaktor$ladungen,cutoff = 0,3) [/code]
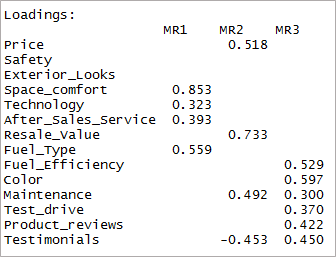
Wie Sie sehen können, sind zwei Variablen unbedeutend geworden und zwei andere haben doppelte Ladung. Als nächstes betrachten wir die „4“ Faktoren.
[code language=”r”] fourfactor <- fa(data,nfactors = 4, Rotate = „oblimin“, fm = „minres“) print(fourfactor$loadings, cutoff = 0.3) [/code]
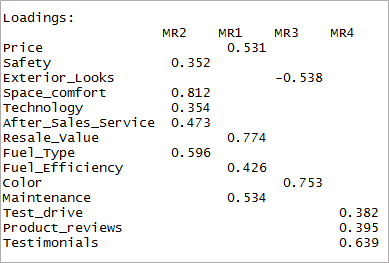
Wir können sehen, dass dies nur zu einem einmaligen Laden führt. Dies ist als einfache Struktur bekannt.
Klicken Sie auf Folgendes, um sich die Faktorzuordnung anzusehen.
[code language="r"] fa.diagramm(vierfaktor) [/code]
Angemessenheitstest
Nachdem wir nun eine einfache Struktur erreicht haben, ist es an der Zeit, unser Modell zu validieren. Schauen wir uns die Ausgabe der Faktoranalyse an, um fortzufahren.

Die Wurzel bedeutet, dass das Quadrat der Residuen (RMSR) 0,05 beträgt. Dies ist akzeptabel, da dieser Wert näher bei 0 liegen sollte. Als nächstes sollten wir den RMSEA-Index (Root Mean Square Error of Approximation) überprüfen. Sein Wert 0,001 zeigt eine gute Modellanpassung, da er unter 0,05 liegt. Schließlich liegt der Tucker-Lewis-Index (TLI) bei 0,93 – ein akzeptabler Wert, wenn man bedenkt, dass er über 0,9 liegt.
Benennen der Faktoren

Nachdem wir die Angemessenheit der Faktoren festgestellt haben, ist es an der Zeit, die Faktoren zu benennen. Dies ist die theoretische Seite der Analyse, wo wir die Faktoren in Abhängigkeit von den Variablenladungen bilden. In diesem Fall können die Faktoren wie folgt erstellt werden.
Fazit
In diesem Tutorial zur Analyse in r haben wir die Grundidee der EFA (explorative Faktorenanalyse in R), die parallele Analyse und die Scree-Plot-Interpretation behandelt. Dann sind wir zur Faktoranalyse in R übergegangen, um eine einfache Struktur zu erreichen und diese zu validieren, um die Angemessenheit des Modells sicherzustellen. Endlich bei den Namen der Faktoren aus den Variablen angekommen. Probieren Sie es jetzt aus und posten Sie Ihre Ergebnisse im Kommentarbereich.