
Die Basarstimme
Veröffentlicht: 2024-04-24Dieser Artikel über die Modernisierung von Legacy-Systemen ist ein Begleitartikel zu einem Vortrag, den ich kürzlich auf dem AWS Data Summit for Software Companies über die Wertschöpfung aus Daten durch die Nutzung unserer Best Practices gehalten habe, um den Erfolg von Machine-Learning-Projekten sicherzustellen. Wenn Sie möchten, können Sie hier ganz nach unten springen und es sich ansehen.
Seien wir ehrlich: Software ist einfacher zu schreiben als zu warten. Aus diesem Grund ziehen wir als Softwareentwickler es vor, einfach „es rauszureißen und von vorne zu beginnen“, anstatt zu versuchen, zu verstehen, was ein anderer Entwickler (oder unser früheres Ich) gedacht hat. Wir scheinen kollektiv vergessen zu haben, dass „Programme geschrieben werden müssen, damit Menschen sie lesen können, und nur nebenbei, damit Maschinen sie ausführen können“.
Sie wissen, es ist wahr – wir alle mussten mühsam einen Topf voller Spaghetti-Code und dünner, altmodischer Abstraktionen durchwühlen und nach dem Kern des Programms suchen, nur um am Ende unseres Tellers nichts als ein Durcheinander zu finden.
Es ist leicht, „WTF“ zu rufen und dem vorherigen Entwickler die Schuld zu geben, aber die Wahrheit ist oft komplizierter. Wir können nicht in die Zukunft blicken, daher ist es unmöglich zu verstehen, wie Anforderungen, Technologie oder Geschäftsziele wachsen werden, wenn wir ein völlig neues System entwerfen. Infolgedessen können Systeme mit zunehmendem Umfang und zunehmender Abhängigkeit des Unternehmens von ihnen unlesbar werden. Das ist ein bisschen paradox: Ältere, schwieriger zu wartende Systeme bieten oft den größten Nutzen. Es ist schwer, an ihnen zu arbeiten, weil sie mit dem Unternehmen gewachsen sind, und es ist beängstigend, daran zu arbeiten, weil es eine Katastrophe bedeuten könnte, sie zu zerstören.
Hier ist mein Aufruf an Sie: Wenn Sie auf schwierige, lohnende Probleme stehen, probieren Sie es aus. Nehmen Sie das älteste System, das Sie haben, und machen Sie es wartbar. Sie kennen das, von dem ich spreche – das, das niemand „besitzen“ wird. Darauf sind die anderen Abteilungen angewiesen, aber die Ingenieure hassen es. Die, auf der Sie zuerst Log4Shell patchen mussten. Tu es. Du traust dich ja nicht.
Ich hatte kürzlich die Gelegenheit, ein zehn Jahre altes maschinelles Lernsystem bei Bazaarvoice zu aktualisieren. Oberflächlich betrachtet klang es nicht aufregend : Dieses Ding hatte nicht einmal neuronale Netze! Wen interessiert das! Nun ja... es war wichtig. Dieses System verarbeitet nahezu jede benutzergenerierte Produktbewertung, die bei Bazaarvoice eingeht – fast 9 Millionen pro Monat – und tut dies mit 90 Millionen Rückschlussaufrufen an Modelle für maschinelles Lernen. Ja – 90 Millionen Schlussfolgerungen! Es ist riesig und ich konnte es kaum erwarten, einzutauchen.
In diesem Beitrag erzähle ich, wie wir durch die Modernisierung dieses Altsystems durch eine Neuarchitektur statt eines Neuschreibens es skalierbar und kostengünstig machen konnten, ohne den gesamten Code herausreißen und von vorne beginnen zu müssen. Das resultierende System ist serverlos, containerisiert und wartbar und reduziert gleichzeitig unsere Hosting-Kosten um fast 80 %.
Was ist ein Altsystem?
Ein Legacy-System bezieht sich auf veraltete Computersoftware und/oder Hardware, die weiterhin in Betrieb ist. Auch wenn es seinen ursprünglichen Zweck noch erfüllt, fehlt ihm die Skalierbarkeit für zukünftiges Wachstum.
Alte Legacy-Systeme
Werfen wir zunächst einen Blick darauf, womit wir es hier zu tun haben. Das alte System, das mein Team aktualisierte, moderiert benutzergenerierte Inhalte für das gesamte Bazaarvoice. Insbesondere wird festgestellt, ob jeder Inhalt für die Websites unserer Kunden geeignet ist.

Das klingt einfach – beseitigen Sie offensichtliche Verstöße wie Hassreden, Schimpfwörter oder Aufforderungen –, aber in der Praxis ist es viel nuancierter. Jeder Kunde hat individuelle Anforderungen an das, was er für angemessen hält. Biermarken würden beispielsweise Diskussionen über Alkohol erwarten, eine Kindermarke jedoch möglicherweise nicht. Wir erfassen diese kundenspezifischen Optionen, wenn wir neue Kunden gewinnen, und unser Kundendienstteam kodiert sie in eine Verwaltungsdatenbank.
Für zusätzliche Komplexität testen wir auch einen Teil unserer Inhalte, um sie von menschlichen Moderatoren moderieren zu lassen. Dadurch können wir die Leistung unserer Modelle kontinuierlich messen und Möglichkeiten für den Aufbau weiterer Modelle entdecken.
Die vollständige Architektur unseres Altsystems ist unten dargestellt:
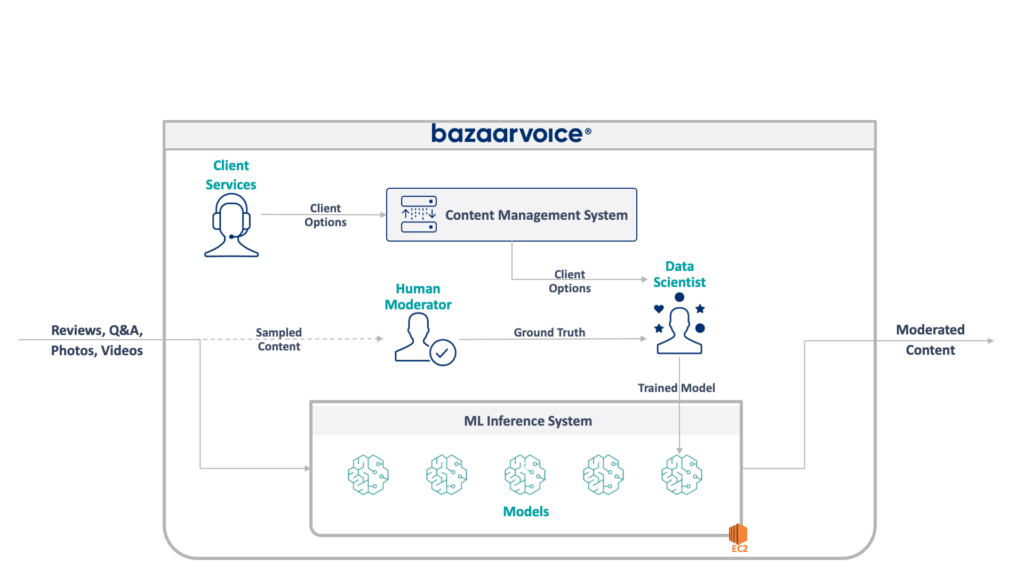
Dieses System weist einige gravierende Nachteile auf. Konkret: Alle Modelle werden auf einer einzigen EC2-Instanz gehostet. Das lag nicht an schlechter Technik, sondern lediglich an der Unfähigkeit der ursprünglichen Programmierer, den vom Unternehmen gewünschten Umfang vorherzusehen. Niemand hätte gedacht, dass es so stark wachsen würde wie es.
Darüber hinaus litt das System unter der Ablehnung der Entwickler: Es war in Scala geschrieben, was nur wenige Ingenieure verstanden. Daher wurde es bei der Verbesserung oft übersehen, da niemand es anfassen wollte.
Infolgedessen wuchs das System kontinuierlich weiter. Nachdem wir es geschafft hatten, die Architektur neu zu gestalten, lief es auf einer einzelnen x1e.8xlarge-Instanz. Dieses Ding verfügte über fast ein Terabyte RAM und kostete im Betrieb etwa 5.000 US-Dollar pro Monat (ohne Reservierung). Aber keine Sorge, wir haben gerade ein zweites für Redundanz und ein drittes für Qualitätssicherung eingeführt.
Der Betrieb dieses Systems war kostspielig und einem hohen Ausfallrisiko ausgesetzt (ein einziges fehlerhaftes Modell kann den gesamten Dienst lahmlegen). Darüber hinaus wurde die Codebasis nicht aktiv weiterentwickelt und war daher mit modernen Data-Science-Paketen deutlich veraltet und entsprach nicht unseren Standardpraktiken für in Scala geschriebene Dienste.
Ein neues System
Bei der Neugestaltung dieses Systems hatten wir ein klares Ziel: es skalierbar zu machen. Die Reduzierung der Betriebskosten war ein sekundäres Ziel, ebenso wie die Vereinfachung der Modell- und Codeverwaltung.
Das neue Design, das wir entwickelt haben, ist unten dargestellt:

Unser Ansatz zur Lösung all dieser Probleme bestand darin, jedes maschinelle Lernmodell auf einem isolierten SageMaker Serverless-Endpunkt zu platzieren. Wie AWS Lambda-Funktionen schalten sich serverlose Endpunkte aus, wenn sie nicht verwendet werden – was uns Laufzeitkosten für selten verwendete Modelle erspart. Sie können auch schnell auf steigenden Datenverkehr reagieren.

Darüber hinaus haben wir die Client-Optionen einem einzigen Microservice zugänglich gemacht, der Inhalte an die entsprechenden Modelle weiterleitet. Dies war der Großteil des neuen Codes, den wir schreiben mussten: eine kleine API, die leicht zu warten war und unseren Datenwissenschaftlern die Aktualisierung und Bereitstellung neuer Modelle erleichterte.
Dieser Ansatz hat folgende Vorteile:
- Die Wertschöpfungszeit wurde um mehr als das Sechsfache verkürzt. Insbesondere erfolgt die Weiterleitung des Datenverkehrs zu vorhandenen Modellen sofort und die Bereitstellung neuer Modelle kann in weniger als 5 statt 30 Minuten erfolgen
- Unbegrenzte Skalierung – wir haben derzeit 400 Modelle, planen aber eine Skalierung auf Tausende, um die Menge an Inhalten, die wir automatisch moderieren können, weiter zu erhöhen
- Durch die Abkehr von EC2 konnten wir eine Kostenreduzierung von 82 % erzielen, da die Funktionen ausgeschaltet werden, wenn sie nicht verwendet werden, und wir zahlen nicht für Spitzenmaschinen, die nicht ausreichend ausgelastet sind
Das einfache Entwerfen einer idealen Architektur ist jedoch nicht der wirklich interessante und schwierige Teil des Neuaufbaus eines Altsystems – Sie müssen darauf migrieren .
Unsere erste Herausforderung bei der Migration bestand darin, herauszufinden, wie man ein Java-WEKA-Modell so migrieren kann, dass es auf SageMaker läuft, ganz zu schweigen von SageMaker Serverless.
Glücklicherweise stellt SageMaker Modelle in Docker-Containern bereit, sodass wir zumindest die Java- und Abhängigkeitsversionen einfrieren konnten, um sie an unseren alten Code anzupassen. Dies würde dazu beitragen, sicherzustellen, dass die im neuen System gehosteten Modelle dieselben Ergebnisse liefern wie das alte.

Um den Container mit SageMaker kompatibel zu machen, müssen Sie lediglich einige spezifische HTTP-Endpunkte implementieren:
-
POST /invocation– Eingaben akzeptieren, Schlussfolgerungen durchführen und Ergebnisse zurückgeben. -
GET /ping– gibt 200 zurück, wenn der JVM-Server fehlerfrei ist
(Wir haben uns entschieden, den ganzen Kram rund um BYO-Multimodell-Container und das SageMaker-Inferenz-Toolkit zu ignorieren.)
Ein paar kurze Abstraktionen rund um com.sun.net.httpserver.HttpServer und schon konnte es losgehen.
Und weisst du was? Das hat wirklich ziemlich viel Spaß gemacht. Das Herumspielen mit Docker-Containern und das Erzwingen von etwas, das 10 Jahre alt ist, in SageMaker Serverless hatte etwas von einer Bastelatmosphäre. Es war ziemlich aufregend, als wir es zum Laufen brachten – insbesondere als wir den Legacy-Systemcode bekamen, um es in unserem neuen SBT-Stack statt in Maven zu erstellen.
Der neue SBT-Stack erleichterte die Arbeit und die Containerisierung sorgte dafür, dass wir bei der Ausführung in der SageMaker-Umgebung das richtige Verhalten erzielen konnten.
Migration auf ein neues System
Wir haben die Modelle also in Containern und können sie in SageMaker bereitstellen – fast fertig, oder? Nicht ganz.
Die schwierige Lektion bei der Migration auf eine neue Architektur ist, dass Sie das Dreifache Ihres tatsächlichen Systems erstellen müssen, nur um die Migration zu unterstützen. Zusätzlich zum neuen System mussten wir bauen:
- Eine Datenerfassungspipeline im alten System zur Aufzeichnung von Eingaben und Ausgaben des Modells. Wir haben diese verwendet, um zu bestätigen, dass das neue System die gleichen Ergebnisse liefern würde
- Eine Datenverarbeitungspipeline im neuen System, um Ergebnisse zu berechnen und sie mit den Daten aus dem alten System zu vergleichen. Dies erforderte umfangreiche Messungen mit Datadog und musste die Möglichkeit bieten, Daten wiederzugeben, wenn wir Unstimmigkeiten fanden
- Ein vollständiges Modellbereitstellungssystem, um Auswirkungen auf die Benutzer des alten Systems zu vermeiden (das einfach Modelle auf S3 hochladen würde). Wir wussten, dass wir sie irgendwann auf eine API umstellen wollten, aber für die erste Version mussten wir dies nahtlos tun
All dies war Wegwerfcode, von dem wir wussten, dass wir ihn wegwerfen konnten, sobald wir die Migration aller Benutzer abgeschlossen hatten, aber wir mussten ihn trotzdem erstellen und sicherstellen, dass die Ausgaben des neuen Systems mit denen des alten übereinstimmten.
Erwarten Sie dies im Voraus.
Obwohl die Entwicklung der Migrationstools und -systeme bei diesem Projekt sicherlich mehr als 60 % unserer Engineering-Zeit in Anspruch nahm, war es auch eine unterhaltsame Erfahrung. Unit-Tests ähnelten eher datenwissenschaftlichen Experimenten: Wir haben ganze Suiten geschrieben, um sicherzustellen, dass unsere Ergebnisse genau übereinstimmten. Es war eine andere Denkweise, die die Arbeit noch mehr Spaß machte. Wenn Sie so wollen, ein Schritt über unsere normalen Grenzen hinaus.
Modernisierung veralteter Systeme durch eine Neuarchitektur
Wenn Sie das nächste Mal versucht sind, ein System vom Code aufwärts neu zu erstellen, möchte ich Sie ermutigen, zu versuchen, die Architektur statt des Codes zu migrieren. Sie werden auf interessante und lohnende technische Herausforderungen stoßen und es wird Ihnen wahrscheinlich viel mehr Spaß machen, als unerwartete Randfälle Ihres neuen Codes zu debuggen.
Möchten Sie mehr erfahren? Sehen Sie sich unten den Vortrag an, den ich auf dem AWS Data Summit gehalten habe und der sich mit der MLOps-Seite befasst.