
Wie funktioniert ein Webcrawler?
Veröffentlicht: 2023-12-05Webcrawler spielen eine wichtige Rolle bei der Indexierung und Strukturierung der umfangreichen Informationen im Internet. Ihre Aufgabe besteht darin, Webseiten zu durchsuchen, Daten zu sammeln und sie durchsuchbar zu machen. Dieser Artikel befasst sich mit der Mechanik eines Webcrawlers und bietet Einblicke in seine Komponenten, Abläufe und verschiedenen Kategorien. Tauchen wir ein in die Welt der Webcrawler!
Was ist ein Webcrawler?
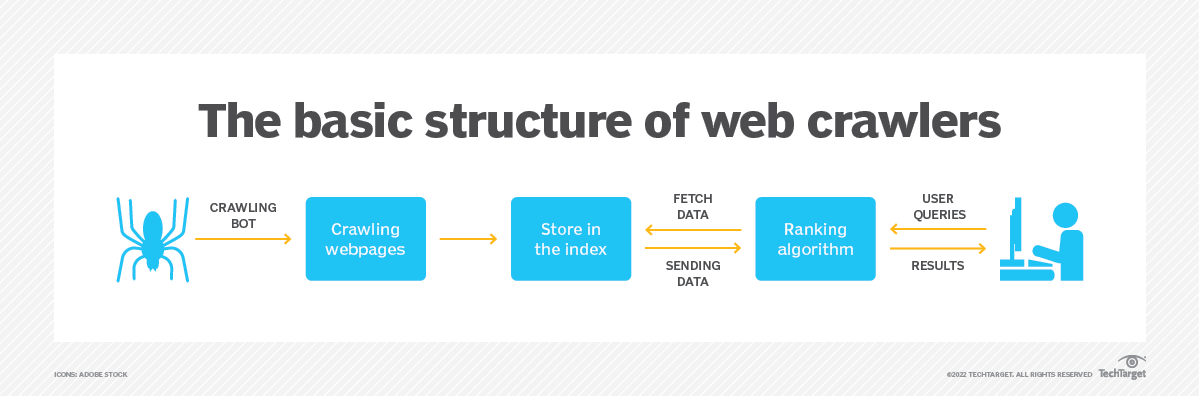
Ein Webcrawler, auch Spider oder Bot genannt, ist ein automatisiertes Skript oder Programm, das für die systematische Navigation durch Internet-Websites konzipiert ist. Es beginnt mit einer Start-URL und folgt dann HTML-Links, um andere Webseiten zu besuchen, wodurch ein Netzwerk miteinander verbundener Seiten entsteht, die indiziert und analysiert werden können.
Bildquelle: https://www.techtarget.com/
Der Zweck eines Webcrawlers
Das Hauptziel eines Webcrawlers besteht darin, Informationen von Webseiten zu sammeln und einen durchsuchbaren Index für einen effizienten Abruf zu erstellen. Große Suchmaschinen wie Google, Bing und Yahoo verlassen sich beim Aufbau ihrer Suchdatenbanken stark auf Webcrawler. Durch die systematische Untersuchung von Webinhalten können Suchmaschinen den Nutzern relevante und aktuelle Suchergebnisse liefern.
Es ist wichtig zu beachten, dass die Anwendung von Webcrawlern über Suchmaschinen hinausgeht. Sie werden auch von verschiedenen Organisationen für Aufgaben wie Data Mining, Inhaltsaggregation, Website-Überwachung und sogar Cybersicherheit verwendet.
Die Komponenten eines Webcrawlers
Ein Webcrawler besteht aus mehreren Komponenten, die zusammenarbeiten, um seine Ziele zu erreichen. Hier sind die Schlüsselkomponenten eines Webcrawlers:
- URL Frontier: Diese Komponente verwaltet die Sammlung von URLs, die auf das Crawlen warten. Es priorisiert URLs basierend auf Faktoren wie Relevanz, Aktualität oder Website-Wichtigkeit.
- Downloader: Der Downloader ruft Webseiten basierend auf den von der URL-Grenze bereitgestellten URLs ab. Es sendet HTTP-Anfragen an Webserver, empfängt Antworten und speichert die abgerufenen Webinhalte zur weiteren Verarbeitung.
- Parser: Der Parser verarbeitet die heruntergeladenen Webseiten und extrahiert nützliche Informationen wie Links, Text, Bilder und Metadaten. Es analysiert die Struktur der Seite und extrahiert die URLs verlinkter Seiten, die der URL-Grenze hinzugefügt werden sollen.
- Datenspeicherung: Die Datenspeicherkomponente speichert die gesammelten Daten, einschließlich Webseiten, extrahierter Informationen und Indexierungsdaten. Diese Daten können in verschiedenen Formaten wie einer Datenbank oder einem verteilten Dateisystem gespeichert werden.
Wie funktioniert ein Webcrawler?
Nachdem wir einen Einblick in die beteiligten Elemente gewonnen haben, wollen wir uns mit dem sequentiellen Verfahren befassen, das die Funktionsweise eines Webcrawlers erläutert:
- Seed-URL: Der Crawler beginnt mit einer Seed-URL, bei der es sich um eine beliebige Webseite oder eine Liste von URLs handeln kann. Diese URL wird zur URL-Grenze hinzugefügt, um den Crawling-Prozess zu starten.
- Abrufen: Der Crawler wählt eine URL aus der URL-Grenze aus und sendet eine HTTP-Anfrage an den entsprechenden Webserver. Der Server antwortet mit dem Webseiteninhalt, der dann von der Downloader-Komponente abgerufen wird.
- Parsen: Der Parser verarbeitet die abgerufene Webseite und extrahiert relevante Informationen wie Links, Text und Metadaten. Außerdem werden auf der Seite gefundene neue URLs identifiziert und zur URL-Grenze hinzugefügt.
- Link-Analyse: Der Crawler priorisiert und fügt die extrahierten URLs basierend auf bestimmten Kriterien wie Relevanz, Aktualität oder Wichtigkeit zur URL-Grenze hinzu. Dies hilft dabei, die Reihenfolge zu bestimmen, in der der Crawler die Seiten besucht und crawlt.
- Vorgang wiederholen: Der Crawler setzt den Vorgang fort, indem er URLs aus der URL-Grenze auswählt, deren Webinhalte abruft, die Seiten analysiert und weitere URLs extrahiert. Dieser Vorgang wird wiederholt, bis keine URLs mehr zum Crawlen vorhanden sind oder ein vordefiniertes Limit erreicht ist.
- Datenspeicherung: Während des Crawling-Prozesses werden die gesammelten Daten in der Datenspeicherkomponente gespeichert. Diese Daten können später zur Indizierung, Analyse oder für andere Zwecke verwendet werden.
Arten von Webcrawlern
Webcrawler gibt es in verschiedenen Varianten und für spezifische Anwendungsfälle. Hier sind einige häufig verwendete Arten von Webcrawlern:

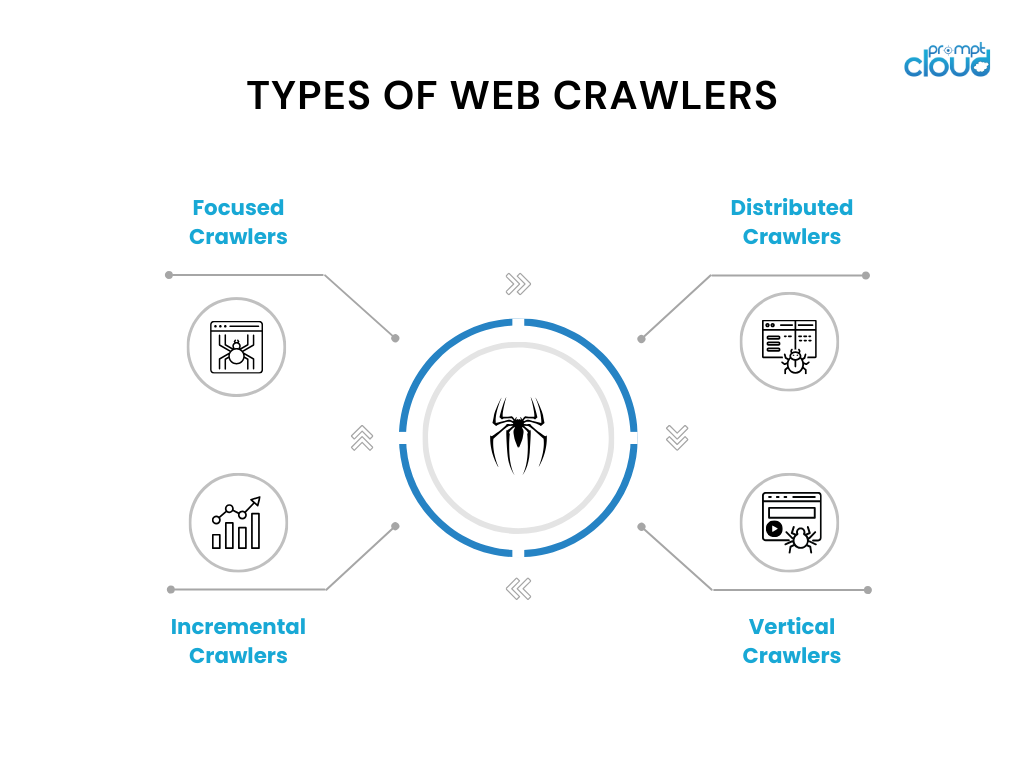
- Fokussierte Crawler: Diese Crawler arbeiten innerhalb einer bestimmten Domain oder eines bestimmten Themas und crawlen für diese Domain relevante Seiten. Beispiele hierfür sind thematische Crawler, die für Nachrichten-Websites oder Forschungsarbeiten verwendet werden.
- Inkrementelle Crawler: Inkrementelle Crawler konzentrieren sich auf das Crawlen neuer oder aktualisierter Inhalte seit dem letzten Crawl. Sie nutzen Techniken wie Zeitstempelanalyse oder Änderungserkennungsalgorithmen, um geänderte Seiten zu identifizieren und zu crawlen.
- Verteilte Crawler: Bei verteilten Crawlern laufen mehrere Instanzen des Crawlers parallel und teilen sich die Arbeitslast beim Crawlen einer großen Anzahl von Seiten. Dieser Ansatz ermöglicht ein schnelleres Crawling und eine verbesserte Skalierbarkeit.
- Vertikale Crawler: Vertikale Crawler zielen auf bestimmte Arten von Inhalten oder Daten innerhalb von Webseiten ab, beispielsweise Bilder, Videos oder Produktinformationen. Sie dienen dazu, bestimmte Datentypen für spezialisierte Suchmaschinen zu extrahieren und zu indizieren.
Wie oft sollten Sie Webseiten crawlen?
Die Häufigkeit des Crawlens von Webseiten hängt von mehreren Faktoren ab, darunter der Größe und Aktualisierungshäufigkeit der Website, der Bedeutung der Seiten und den verfügbaren Ressourcen. Einige Websites müssen möglicherweise häufig gecrawlt werden, um sicherzustellen, dass die neuesten Informationen indiziert werden, während andere möglicherweise weniger häufig gecrawlt werden.
Bei stark frequentierten Websites oder Websites mit sich schnell ändernden Inhalten ist häufigeres Crawlen unerlässlich, um die Informationen auf dem neuesten Stand zu halten. Andererseits können kleinere Websites oder Seiten mit seltenen Updates seltener gecrawlt werden, was den Arbeitsaufwand und die erforderlichen Ressourcen reduziert.
Interner Web-Crawler im Vergleich zu Web-Crawling-Tools
Wenn Sie über die Erstellung eines Webcrawlers nachdenken, ist es wichtig, die Komplexität, Skalierbarkeit und die erforderlichen Ressourcen zu bewerten. Das Erstellen eines Crawlers von Grund auf kann ein zeitintensives Unterfangen sein und Aktivitäten wie die Verwaltung der Parallelität, die Überwachung verteilter Systeme und die Beseitigung von Infrastrukturhindernissen umfassen. Auf der anderen Seite kann die Entscheidung für Web-Crawling-Tools oder -Frameworks eine schnellere und effektivere Lösung bieten.
Alternativ kann die Verwendung von Web-Crawling-Tools oder Frameworks eine schnellere und effizientere Lösung bieten. Diese Tools bieten Funktionen wie anpassbare Crawling-Regeln, Datenextraktionsfunktionen und Datenspeicheroptionen. Durch die Nutzung vorhandener Tools können sich Entwickler auf ihre spezifischen Anforderungen konzentrieren, beispielsweise auf die Datenanalyse oder die Integration mit anderen Systemen.
Es ist jedoch wichtig, die Einschränkungen und Kosten zu berücksichtigen, die mit der Verwendung von Tools von Drittanbietern verbunden sind, wie z. B. Einschränkungen bei der Anpassung, dem Dateneigentum und potenziellen Preismodellen.
Abschluss
Suchmaschinen sind in hohem Maße auf Webcrawler angewiesen, die maßgeblich an der Organisation und Katalogisierung der umfangreichen Informationen im Internet beteiligt sind. Das Verständnis der Mechanismen, Komponenten und verschiedenen Kategorien von Webcrawlern ermöglicht ein tieferes Verständnis der komplexen Technologie, die diesem grundlegenden Prozess zugrunde liegt.
Unabhängig davon, ob Sie sich dafür entscheiden, einen Webcrawler von Grund auf zu erstellen oder bereits vorhandene Tools für das Webcrawlen zu nutzen, ist es unerlässlich, einen Ansatz zu wählen, der auf Ihre spezifischen Bedürfnisse zugeschnitten ist. Dabei müssen Faktoren wie Skalierbarkeit, Komplexität und die Ihnen zur Verfügung stehenden Ressourcen berücksichtigt werden. Wenn Sie diese Elemente berücksichtigen, können Sie Web-Crawling effektiv nutzen, um wertvolle Daten zu sammeln und zu analysieren und so Ihr Unternehmen oder Ihre Forschungsbemühungen voranzutreiben .
Bei PromptCloud sind wir auf die Extraktion von Webdaten spezialisiert und beziehen Daten aus öffentlich zugänglichen Online-Ressourcen. Kontaktieren Sie uns unter sales@promptcloud.com