
So verhindern Sie, dass KIs Ihre Inhalte crawlen
Veröffentlicht: 2023-10-24Generative KI-Tools wie Google Bard und Bing Chat werden aus vielen Inhaltsquellen, einschließlich dem Web, erstellt. Zur Bestürzung vieler haben Suchmaschinen ihre KI-Modelle im Stillen auf alle Inhalte trainiert, die sie beim Crawlen für die traditionelle Websuche finden.
Bing und Google haben jetzt Methoden angekündigt, um die Verwendung von Inhalten für KI-Schulungen zu blockieren und gleichzeitig für die Websuche indiziert zu bleiben.
Sollten Sie also die KIs blockieren und wie gehen Sie dabei vor?
- Sollten Sie KIs blockieren?
- Wie blockiert man KI-Bots?
- So blockieren Sie Bings KI
- So blockieren Sie die KI von Google
- So blockieren Sie ChatGPT
- Testen
Sollten Sie KIs blockieren?
Unternehmen, die ihre eigenen Produkte herstellen, können es als Vorteil erachten, ihre Inhalte in KI-Modelle einzubinden. Informationen wie technische Spezifikationen oder Produktsupport können beim Verkauf helfen und die Kosten für den Kundensupport senken.
Aber für viele andere Online-Unternehmen ist der Inhalt ihr Produkt. Es gibt berechtigte Bedenken, dass die in die Erstellung von Inhalten investierte Energie zur Verbesserung der KI-Produkte der großen Technologieunternehmen verwendet wird, ohne dass dadurch ein Mehrwert in Form von Datenverkehr entsteht.
Google und Bing versuchen, Möglichkeiten zu finden, die Quellen zu nennen und etwas Empfehlungsverkehr zu liefern, aber dieser dürfte geringer ausfallen als bei der herkömmlichen Websuche und eher transaktionaler Natur sein als informelle Suchanfragen.
Es ist wichtig zu beachten, dass das Blockieren von Inhalten dieser KIs keinen Einfluss auf das Crawling-Verhalten hat. Google sagt: „Das robots.txt-User-Agent-Token wird zu Kontrollzwecken verwendet.“ Ihre Website wird wie gewohnt von den Bots gecrawlt, um ihre Suchindizes zu erstellen.
Und wenn die Suchmaschinen bereits daran gehindert sind, bestimmte Seiten zu crawlen, müssen Sie diese nicht speziell für die KIs blockieren.
Wie blockiert man KI-Bots?
Derzeit ist es möglich, Google, Bing und ChatGPT mithilfe von Methoden zu blockieren, die den meisten SEOs bekannt sind: der robots.txt-Datei und Robots-Anweisungen auf Seitenebene.
Google und ChatGPT haben sich für die robots.txt-Methode entschieden, mit der Sie URL-Muster angeben können, und Bing hat sich für die Verwendung von Robots-Anweisungen entschieden, die auf einzelne Seiten angewendet werden.
Die robots.txt-Datei hat den Vorteil, dass sie einfach an einem einzigen Ort für eine gesamte Website konfiguriert werden kann. Im Vergleich zu den Robots-Anweisungen auf Seitenebene, die durch das Abrufen jeder einzelnen Seite getestet werden müssen, ist es sehr transparent, welche URLs blockiert werden.
So blockieren Sie Bings KI
Bing sucht nach den Nocache- oder Noarchive-Robots-Anweisungen, die einer Seite als Meta-Tag oder in einem X-Robots-Tag-Antwortheader hinzugefügt werden können.
Mit Nocache können Seiten in Bing-Chat-Antworten einbezogen werden, indem beim Training der KI-Modelle von Microsoft nur URLs, Titel und Snippets verwendet werden.
Noarchive erlaubt keine Einbindung von Seiten in Bing Chat und es werden keine Inhalte zum Training der KI-Modelle von Microsoft verwendet.
Wenn eine Seite sowohl Nocache als auch Noarchive hat, hat das weniger restriktive Nocache Vorrang.
Das „ Robots “-Token wendet die Anweisung auf alle Crawler an. Dazu gehört auch Google, das verhindert, dass die Seite mit einem zwischengespeicherten Link in den Suchergebnissen erscheint.
<meta name=“robots“ content=“noarchive“>
Sie können die spezifischeren „ bingbot “- oder „ msnbot “-Tokens verwenden, um Auswirkungen auf andere Suchmaschinen zu vermeiden.
<meta name=“bingbot“ content=“nocache“>
So blockieren Sie die KI von Google
Google hat sich für die robots.txt-Methode entschieden, mit der Sie URL-Muster angeben können, um Seiten zuzuordnen, die Sie nicht in Bard und deren Vertex-API-Äquivalent verwenden möchten. Es gilt derzeit nicht für das Search Generative Experience (SGE).
Sie werden mit einem von Google erweiterten User-Agent-Token abgeglichen. Die Groß-/Kleinschreibung des Tokens spielt keine Rolle.
Benutzeragent: Google-Extended
Nicht zulassen: /
Wenn kein spezieller Regelblock für das Google-Extended-Token vorhanden ist, wird dieser mit dem Wildcard-Token (*) abgeglichen.

User-Agent: *
Nicht zulassen: /
Seien Sie vorsichtig, wenn Sie einen bestimmten Regelblock für den Googlebot und einen separaten Platzhalterblock haben. Google-extended entspricht dem Wildcard-Block, nicht dem Googlebot-Block.
Benutzeragent: Googlebot
Erlauben: /
User-Agent: *
Nicht zulassen: /
Um genauer zu sein, können Sie mehrere Benutzeragenten vor den Regelblöcken auflisten.
Benutzeragent: Google-Extended
Benutzeragent: Googlebot
Erlauben: /
User-Agent: *
Nicht zulassen: /
So blockieren Sie ChatGPT
ChatGPT hat sich auch für die robots.txt-Methode entschieden.
Chat GPT verfügt über zwei verschiedene Benutzeragenten-Tokens: ChatGPT-User für Abfragen im Namen von ChatGPT-Benutzern und GPTBot, den Webcrawler von OpenAI, der zum Erstellen ihrer Modelle verwendet wird.
Das Opt-out-System behandelt derzeit beide Benutzeragenten gleich, sodass jede robots.txt-Verweigerung für einen Agenten beide abdeckt. Dies kann sich in Zukunft ändern. Wir empfehlen daher, sie separat zu blockieren.
Benutzeragent: GPTBot
Benutzeragent: ChatGPT-Benutzer
Nicht zulassen: /
Testen
Das Testen ist einfach, wenn Sie Ihre gesamte Website blockieren.
Um zu überprüfen, ob Google und ChatGPT blockiert sind, müssen Sie prüfen, ob Ihre robots.txt-Datei eine Regel „Alles zulassen“ für die Bots enthält, die Sie blockieren möchten.
Benutzeragent: Google-Extended
Benutzeragent: GPTbot
Nicht zulassen: /
Wenn Sie nur einige URLs blockieren möchten, sind möglicherweise komplexere robots.txt-Anweisungen erforderlich. Sie können erwägen, eine Reihe von URLs zu testen, von denen Sie erwarten, dass sie blockiert und nicht blockiert werden.
Tomo ist unser kostenloses robots.txt-Tool, mit dem Sie testen können, ob bestimmte URLs in robots.txt blockiert sind. Sie können Tests in Form einer Liste von URLs und dem erwarteten Nichtzulassungsstatus für jede URL definieren.
Es kann mit den User-Agent-Tokens Google-Extended, GPTBot und ChatGPT-User konfiguriert werden, um Ihnen anzuzeigen, welche URLs jeweils blockiert sind und ob dies mit dem erwarteten Testergebnis übereinstimmt.
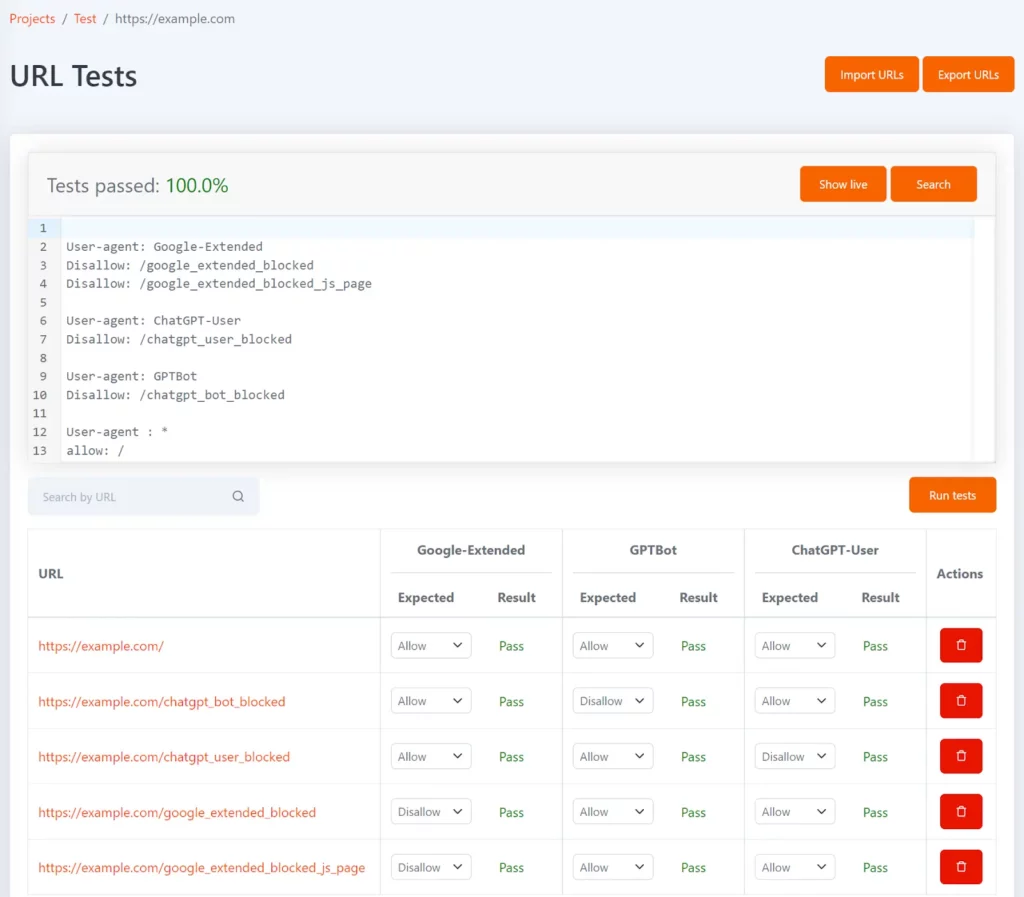
Immer wenn Ihre robots.txt-Datei aktualisiert wird, werden die Tests erneut ausgeführt und Sie werden benachrichtigt, wenn die Ergebnisse nicht den Erwartungen entsprechen.
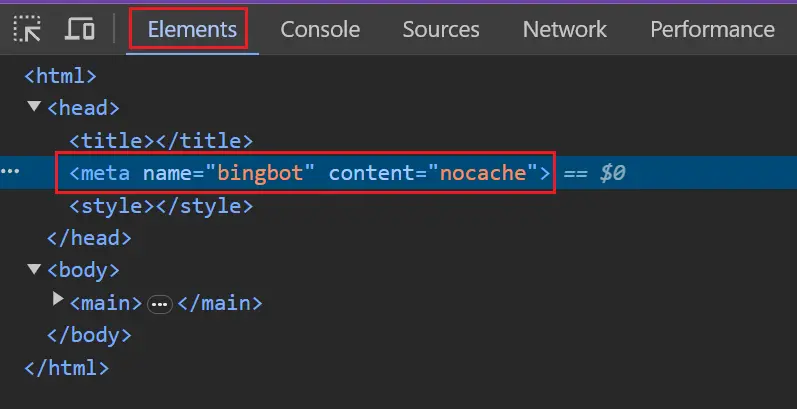
Um zu testen, ob Bing blockiert ist, können Sie Ihre wichtigsten Seitenvorlagen im Browser überprüfen und bestätigen, dass sie über das Robots-Tag verfügen.
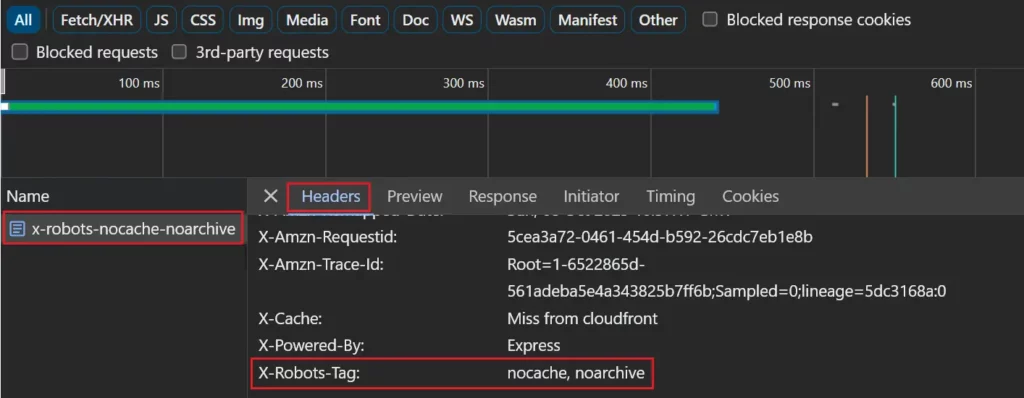
Wenn Sie einen X-Robots-Tag-Antwortheader verwenden, können Sie ihn auf der Registerkarte „Netzwerk“ anzeigen, indem Sie die Seite in der Liste der Netzwerkanforderungen auswählen und die Registerkarte „Header“ anzeigen.
Das Testen wird komplizierter, wenn Sie eine bestimmte Gruppe von Seiten blockieren, aber es gibt einige Tools, die dabei helfen können.
Der Lumar-Crawler meldet jetzt auch automatisch alle Seiten, auf denen die KIs von Google und Bing blockiert sind.
Benötigen Sie zusätzliche technische Unterstützung? Erfahren Sie mehr über das Technologieangebot von Semetrical oder kontaktieren Sie uns für weitere Informationen!