
Jarvis Rising – Wie Google „on the fly“ ein Modell für maschinelles Lernen generieren könnte, um Antworten vorherzusagen, wenn die Suche dies nicht kann, und wie es diese Modelle indizieren könnte, um Antworten für zukünftige Anfragen vorherzusagen [Paten
Veröffentlicht: 2023-07-13
Nachdem ich ein Google-Patent im Zusammenhang mit PAA und PASF analysiert hatte, begann ich, andere kürzlich erteilte Patente zu prüfen. Und es dauerte nicht lange, bis ich auf ein weiteres sehr interessantes Thema zum Einsatz von Modellen für maschinelles Lernen stieß. Das Patent, das ich gerade analysiert habe, konzentriert sich auf die Verwendung und/oder Generierung eines maschinellen Lernmodells als Antwort auf eine Anfrage (wenn Google eine Antwort vorhersagen muss, da die Standardsuchergebnisse keine angemessene Antwort liefern konnten). Nach mehrmaliger Lektüre des Patents wurde deutlich, wie ausgefeilt die Systeme von Google sein können, wenn es darum geht, Nutzern eine qualitativ hochwertige Antwort (oder Vorhersage) bereitzustellen.
Wie bei jedem Patent wissen wir nie, ob Google tatsächlich umgesetzt hat, was das Patent abdeckt, aber es ist immer möglich. Und wenn es implementiert würde, könnte Google nicht nur ein trainiertes Modell für maschinelles Lernen verwenden, um eine Antwort auf eine Anfrage vorherzusagen , sondern es kann diese Modelle für maschinelles Lernen auch indizieren , sie mit verschiedenen Entitäten, Webseiten usw. verknüpfen und dann und abrufen Verwenden Sie diese Modelle für nachfolgende verwandte Suchen. Denken Sie darüber nach, wie leistungsstark und skalierbar das für Google sein kann.
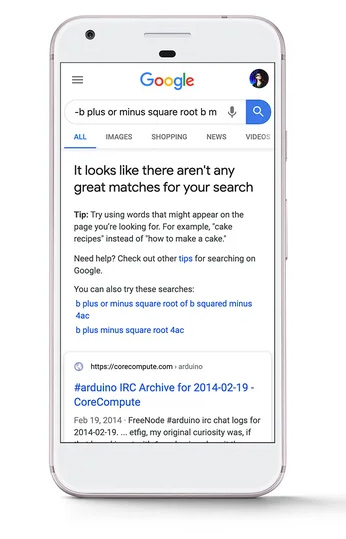
Darüber hinaus erklärt das Patent, dass Google eine interaktive Schnittstelle zum maschinellen Lernmodell in den Suchergebnissen zurückgeben kann, die es Benutzern ermöglicht, Parameter hinzuzufügen, die zur Generierung einer Vorhersage für Suchanfragen verwendet werden können, wenn die Suchergebnisse nicht ausreichen. Dieser Teil des Patents ließ mich an die Meldung denken, die Google im April 2020 in den SERPs verbreitete, wenn für eine Suchanfrage keine qualitativ hochwertigen Suchergebnisse zurückgegeben wurden. Die aktuelle Implementierung stellt kein Formular zur Verfügung, mit dem Benutzer interagieren können, aber das könnte irgendwann sicher der Fall sein. Und vielleicht könnte diese Schnittstelle in Zukunft für mehr Abfragen verwendet werden als nur für die unklareren, die sie derzeit auftauchen lässt. Ich werde in den folgenden Aufzählungspunkten mehr darüber berichten.
Kernpunkte des Patents:
Ähnlich wie in meinem letzten Beitrag über ein aktuelles Google-Patent denke ich, dass der beste Weg, die Details abzudecken, darin besteht, die wichtigsten Punkte in Aufzählungszeichen anzugeben.
Generieren und/oder Nutzen eines maschinellen Lernmodells als Reaktion auf eine Suchanfrage
US 11645277 B2
Datum der Erteilung: 9. Mai 2023
Anmeldedatum: 12. Dezember 2017
Name des Bevollmächtigten: Google LLC
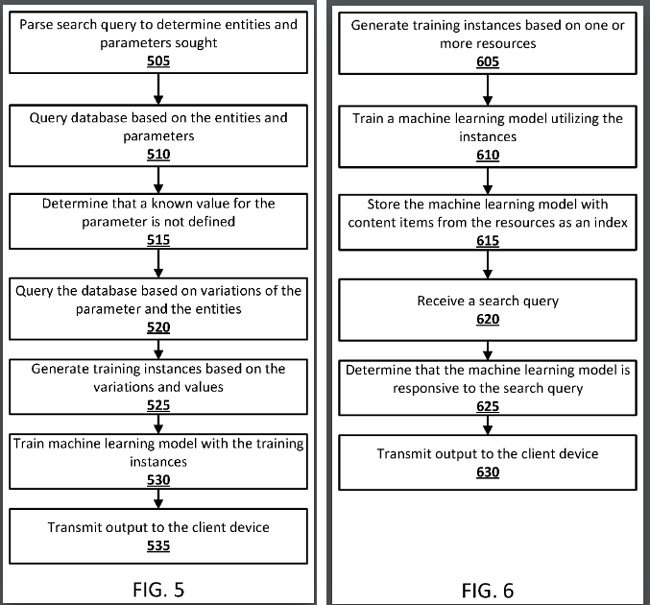
1. Das Patent von Google erklärt, dass ein trainiertes maschinelles Lernmodell zum Generieren einer Vorhersage verwendet werden kann, wenn eine Antwort nicht mit Sicherheit gefunden werden kann und der Benutzer eine Anfrage sendet, die prädiktiver Natur ist.
2. Beispielsweise könnte Google zunächst Suchergebnisse basierend auf einer Suchanfrage generieren. Wenn die Ergebnisse jedoch nicht von ausreichender Qualität sind, kann ein maschinelles Lernmodell verwendet werden, um eine stärker vorhergesagte Antwort zu liefern. So kann das System auf der Grundlage eines maschinellen Lernmodells vorhergesagte Antworten bereitstellen, wenn eine Antwort nicht von Google validiert werden kann.

3. Außerdem kann das Modell für maschinelles Lernen „on the fly“ generiert werden, und Google speichert möglicherweise trainierte Modelle für maschinelles Lernen in einem Suchindex. Ja, Google könnte Modelle für maschinelles Lernen indizieren, die gerade darauf trainiert wurden, Vorhersagen auf der Grundlage bestimmter Abfragetypen zu liefern. Ich werde bald mehr darüber berichten.

4. Das Patent lieferte ein Beispiel basierend auf der Frage „Wie viele Ärzte wird es im Jahr 2050 in China geben?“ Wenn über die Standardsuchergebnisse keine verlässliche Antwort bereitgestellt werden kann, kann die Abfrage an ein trainiertes maschinelles Lernmodell übergeben werden, um eine Vorhersage zu generieren.

5. Das Patent erklärt weiter, dass das System möglicherweise andere Jahre wie 2010, 2015, 2020 usw. benötigt und diese verwendet, um eine Vorhersage zu erstellen (über ein auf diesen Parametern trainiertes Modell für maschinelles Lernen).
6. Das Patent erklärt, dass trainierte Modelle für maschinelles Lernen durch ein oder mehrere Inhaltselemente aus „Ressourcen, die zum Trainieren des Modells verwendet werden“ indiziert werden können. Und für zukünftige Abfragen, wenn das System Parameter identifiziert, die mit einem Modell für maschinelles Lernen in Zusammenhang stehen (z. B. wenn ein nachfolgender Benutzer eine verwandte Frage stellt wie „Wie viele Ärzte gibt es in China im Jahr 2040 ?“), könnte das Modell für maschinelles Lernen dies tun verwendet werden, um eine Vorhersage zu erstellen.


7. Das Patent erklärt weiter, dass die Modelle des maschinellen Lernens mit einem oder mehreren Inhaltselementen gespeichert werden könnten, wie z. B. Entitäten in einem Wissensgraphen, Tabellennamen, Spaltennamen, Webseitennamen und mehr. Darüber hinaus könnten mit der Abfrage verbundene Wörter wie „China“ und „Ärzte“ vom maschinellen Lernmodell verwendet werden, um eine Vorhersage zu generieren.
8. Das Patent erklärt weiter, dass das System möglicherweise eine interaktive Schnittstelle für Benutzer bereitstellt, über die sie Parameter auswählen können, die an das Modell für maschinelles Lernen übergeben werden können. Dabei kann es sich um ein Textfeld, ein Dropdown-Menü usw. handeln. Außerdem könnte die Antwort eine dem Benutzer angezeigte Nachricht enthalten, dass es sich bei der Antwort um eine Vorhersage handelt, die auf einem trainierten Modell für maschinelles Lernen basiert. Daher möchte Google sicherstellen, dass Nutzer verstehen, dass es sich um eine Vorhersage handelt, die auf einem maschinellen Lernmodell basiert, und nicht um Antworten, die auf indizierten Daten basieren.

9. Das trainierte Modell kann dann validiert werden, um sicherzustellen, dass die Vorhersagen mindestens eine „Schwellenqualität“ haben. Alles, was unter einem bestimmten Schwellenwert liegt, kann unterdrückt und dem Benutzer nicht zur Verfügung gestellt werden. In diesem Fall können stattdessen die Standard-Suchergebnisse angezeigt werden.

10. Über öffentliche Suchergebnisse hinaus erklärt das Patent, dass das System in einer privaten Datenbank verwendet werden könnte, um Unternehmen dabei zu helfen, bestimmte Ergebnisse vorherzusagen. Das Patent erklärt: „privat für eine Gruppe von Benutzern, ein Unternehmen und/oder andere eingeschränkte Gruppen.“ Ein Mitarbeiter eines Vergnügungsparks könnte beispielsweise fragen: „Wie viele Schneekegel werden wir morgen verkaufen?“ Das System könnte dann eine private Datenbank abfragen, um Verkäufe früherer Tage, Wetterinformationen, Anwesenheitsdaten usw. zu verstehen und eine Antwort für den Mitarbeiter vorherzusagen.
11. Das Patent erklärt, dass das System irgendwann Push-Benachrichtigungen von einem „automatisierten Assistenten“ bereitstellen könnte. Und wenn ich nur laut darüber nachdenke, frage ich mich, ob das von einem Jarvis-ähnlichen Assistenten stammen könnte, wie ich es in meinem Beitrag über Googles Code Red erklärt habe, der Tausende von Code Reds bei Verlagen ausgelöst hat.

12. Unter dem Gesichtspunkt der Latenz erklärt das Patent, dass es zu einer Verzögerung kommen könnte, nachdem ein Benutzer eine Anfrage übermittelt hat. In diesem Fall werden möglicherweise zunächst die Standardsuchergebnisse zusammen mit der Meldung angezeigt, dass für die Abfrage keine „guten“ Ergebnisse verfügbar sind und dass ein maschinelles Lernmodell zur Generierung einer Vorhersage verwendet wird. In solchen Situationen könnte das System diese Vorhersage zu einem späteren Zeitpunkt an den Benutzer weiterleiten oder einen Hyperlink bereitstellen, auf den Benutzer klicken können, um die Ausgabe des maschinellen Lernens anzuzeigen.
13. Das Patent besagt außerdem, dass der Benutzer in einigen Situationen die Aufforderung bestätigen müsste, damit der Prozess fortgesetzt werden könne. Beispielsweise könnte das System eine Meldung ausgeben, die besagt: „Eine gute Antwort ist nicht verfügbar.“ Soll ich eine Antwort für Sie vorhersagen?“ Dann würde das maschinelle Lernmodell nur dann trainiert, wenn als Reaktion auf die Aufforderung eine positive Benutzereingabe eingeht. Wie ich bereits erklärt habe, sehe ich einen Zusammenhang mit der Meldung „Es gibt keine tollen Treffer für Ihre Suche“, die im April 2020 eingeführt wurde. Ich frage mich, ob dies in Zukunft ausgeweitet werden könnte, um dieses Modell zu nutzen …

Zusammenfassung: Google könnte mithilfe von (indizierten) maschinellen Lernmodellen qualitativ hochwertige Antworten auf leistungsstarke und äußerst effiziente Weise vorhersagen.
Obwohl wir nicht wissen, ob ein bestimmtes Patent verwendet wird, ist die Leistungsfähigkeit und Effizienz dieses Prozesses für Google sehr sinnvoll. Von der „on-the-fly“-Erstellung von Modellen für maschinelles Lernen über die Indizierung dieser Modelle für die zukünftige Verwendung bis hin zur Nutzung einer interaktiven Schnittstelle mit Push-Benachrichtigungen scheint Google die Voraussetzungen für einen Assistenten wie Jarvis zu bereiten. Wenn Sie also Google das nächste Mal bitten, eine Antwort vorherzusagen, denken Sie an dieses Patent. Und vielleicht werden Sie irgendwann nach weiteren Informationen gefragt (bis Jarvis das alles in einer Nanosekunde erledigen kann). :) :)
GG