
Skalierung von Data-Scraping-Vorgängen: Expertentipps für den Umgang mit großen Datenmengen
Veröffentlicht: 2024-05-25Mit der wachsenden Nachfrage nach Daten steigen auch die Herausforderungen, die mit der Skalierung von Data-Scraping-Vorgängen verbunden sind. Beim groß angelegten Web Scraping geht es nicht nur darum, die Menge der gesammelten Daten zu erhöhen; Es geht darum, die Qualität aufrechtzuerhalten, die Effizienz sicherzustellen und technische und rechtliche Hürden zu überwinden.
Stellen Sie sich ein Einzelhandelsunternehmen vor, das mit einem bescheidenen Data-Scraping-Vorgang beginnt und Preis- und Produktinformationen von einigen Konkurrenz-Websites sammelt. Dieses Setup funktioniert zunächst reibungslos und liefert wertvolle Erkenntnisse für die strategische Entscheidungsfindung. Da das Unternehmen jedoch expandiert und beginnt, einen breiteren Markt anzusprechen, wird der Bedarf an groß angelegtem Web-Scraping von Hunderten oder sogar Tausenden von Websites deutlich. Die ursprüngliche Infrastruktur, die für kleine Vorgänge ausreichend war, leidet nun unter der erhöhten Belastung, was zu einer langsameren Leistung und potenziellen Datenungenauigkeiten führt.
Darüber hinaus erhöht der Umgang mit vielfältigen und dynamischen Webquellen die Komplexität zusätzlich. Websites aktualisieren häufig ihre Strukturen, implementieren Anti-Scraping-Maßnahmen oder erfordern eine Datenextraktion aus komplexen, mit JavaScript gerenderten Inhalten. Diese Herausforderungen erfordern robuste, anpassungsfähige Lösungen, die nahtlos skaliert werden können, ohne Kompromisse bei der Datenqualität oder Rechtmäßigkeit einzugehen.
Beim groß angelegten Web Scraping geht es nicht nur darum, mehr Daten zu verarbeiten, sondern dies auf effiziente, zuverlässige und den gesetzlichen Standards entsprechende Weise zu tun. Dazu gehört die Auswahl der richtigen Tools und Technologien, der Aufbau einer robusten Infrastruktur und die Implementierung effizienter Datenverarbeitungspipelines. Für Unternehmen, die das volle Potenzial des Data Scraping ausschöpfen möchten, ist es wichtig, die großen Herausforderungen beim Web Scraping zu verstehen und Strategien zu ihrer Bewältigung zu entwickeln.
#1: Auswahl der richtigen Tools und Technologien
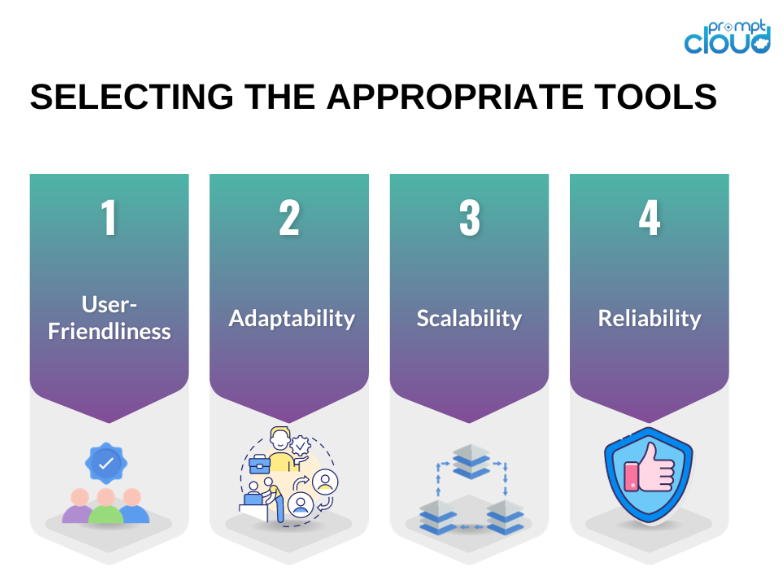
Die Auswahl der geeigneten Tools und Technologien ist die Grundlage groß angelegter Web-Scraping-Operationen. Fortschrittliche Scraping-Frameworks wie Scrapy, Beautiful Soup und Selenium bieten robuste Funktionalitäten, die komplexe Scraping-Aufgaben bewältigen können. Diese Tools eignen sich hervorragend für kleinere, besser verwaltbare Projekte. Da jedoch der Umfang und die Komplexität von Data-Scraping-Vorgängen zunehmen, sind leistungsfähigere und flexiblere Lösungen erforderlich.
Hier kommen Web-Scraping-Dienstleister wie PromptCloud ins Spiel. PromptCloud bietet eine umfassende End-to-End-Datenextraktionslösung, die sich nahtlos an die Geschäftsanforderungen anpassen lässt. Im Gegensatz zu herkömmlichen Tools bietet PromptCloud einen vollständig verwalteten Service, der sich um alles kümmert, von der Einrichtung der Scraping-Infrastruktur bis zur Datenbereitstellung.
#2: Aufbau einer robusten Infrastruktur
Eine robuste Infrastruktur ist für die Unterstützung groß angelegter Web-Scraping-Vorgänge von entscheidender Bedeutung. Dazu gehören leistungsstarke Server, großzügige Speicherlösungen und Hochgeschwindigkeits-Internetverbindungen. Die Nutzung von Cloud-Infrastrukturdiensten wie Amazon Web Services (AWS), Google Cloud Platform (GCP) oder Microsoft Azure gewährleistet Skalierbarkeit und Zuverlässigkeit und ermöglicht es Unternehmen, ihre Abläufe nach Bedarf zu skalieren.

Das Einrichten und Verwalten einer eigenen Infrastruktur kann ressourcenintensiv und komplex sein. PromptCloud bietet eine optimierte Lösung, die diese Herausforderungen beseitigt. Durch die Bereitstellung eines vollständig verwalteten Daten-Scraping-Dienstes kümmert sich PromptCloud um die Infrastrukturanforderungen und stellt sicher, dass Ihre Abläufe reibungslos und effizient laufen.
#3: Sicherstellung der Datenqualität und -genauigkeit im großen Maßstab
Die Aufrechterhaltung der Datenqualität und -genauigkeit ist beim Umgang mit großen Datensätzen eine große Herausforderung. Da das Datenvolumen zunimmt, steigt das Potenzial für Fehler und Inkonsistenzen. Daher ist die Implementierung robuster Verfahren zur Datenvalidierung und -bereinigung von entscheidender Bedeutung. Um fundierte Geschäftsentscheidungen zu treffen und die Integrität Ihrer Analysen aufrechtzuerhalten, ist es wichtig sicherzustellen, dass die gesammelten Daten zuverlässig und nutzbar sind.
Websites ändern häufig ihre Strukturen, was den Daten-Scraping-Vorgang stören und zu Ungenauigkeiten führen kann. Die regelmäßige Überwachung und Aktualisierung Ihrer Scraping-Skripte ist unerlässlich, um sich an diese Änderungen anzupassen und die fortlaufende Genauigkeit der gesammelten Daten sicherzustellen.
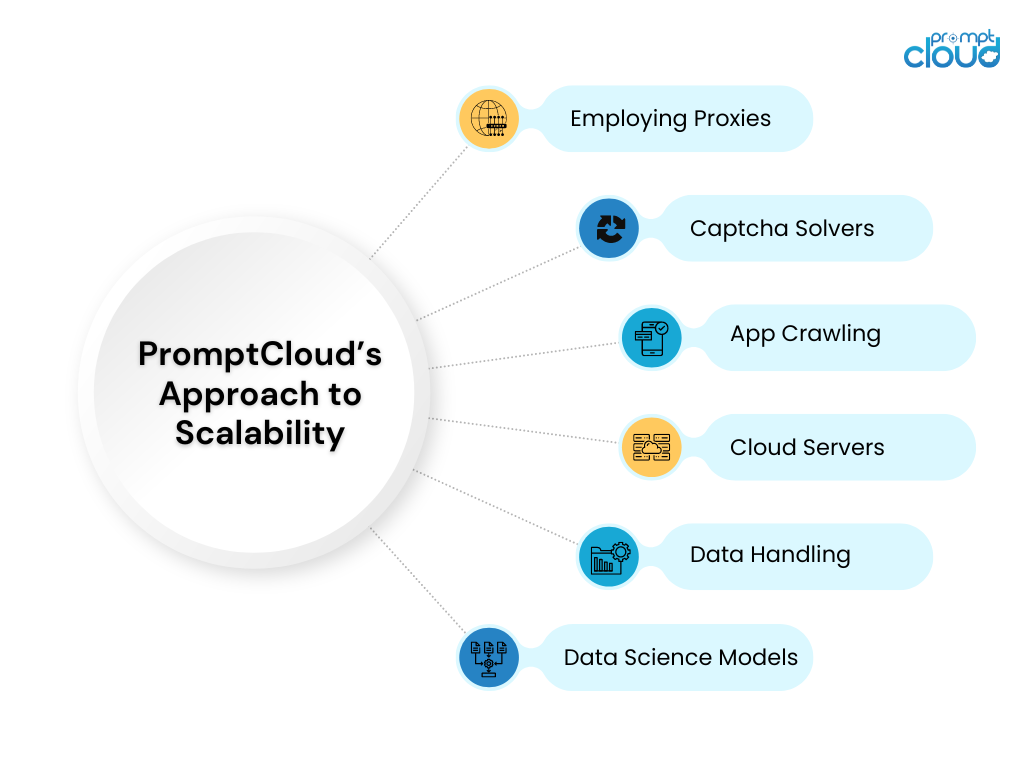
PromptCloud bietet eine umfassende Lösung zur Aufrechterhaltung der Datenqualität und -genauigkeit im großen Maßstab. Durch die Nutzung der umfangreichen Web-Scraping- und Managed-Data-Scraping-Dienste können Sie sicherstellen, dass Ihre Datenerfassungsprozesse robust und zuverlässig bleiben.
#4: Nutzung von Cloud-Lösungen für Skalierbarkeit
Cloud-Lösungen bieten eine beispiellose Skalierbarkeit für Daten-Scraping-Vorgänge. Dienste wie AWS EC2 und Google Cloud Compute Engine ermöglichen es Unternehmen, ihre Rechenressourcen je nach Bedarf zu vergrößern oder zu verkleinern. Diese Flexibilität stellt sicher, dass Daten-Scraping-Vorgänge unterschiedliche Arbeitslasten bewältigen können, ohne die Leistung zu beeinträchtigen.
PromptCloud nutzt die Vorteile von Cloud-Lösungen voll aus, um einen skalierbaren und effizienten Web-Scraping-Service im großen Maßstab anzubieten. Durch die Integration mit führenden Cloud-Plattformen stellt PromptCloud sicher, dass Ihre Data-Scraping-Vorgänge jedes Datenvolumen problemlos bewältigen können.
#5: Umgang mit Datenspeicherung und -verwaltung
Effektive Lösungen zur Datenspeicherung und -verwaltung sind für den Umgang mit großen Mengen an Scraped-Daten von entscheidender Bedeutung. Da die Menge an Daten wächst, wird es immer wichtiger, sicherzustellen, dass diese sicher gespeichert werden und schnell darauf zugegriffen werden kann.
PromptCloud bietet im Rahmen seiner Managed Data Scraping-Dienste umfassende Lösungen zur Datenspeicherung und -verwaltung. Durch den Einsatz skalierbarer Speicherlösungen und die Implementierung von Best Practices im Datenmanagement stellt PromptCloud sicher, dass Ihre Daten sicher gespeichert werden und effizient darauf zugegriffen werden kann.
Skalieren Sie Web Scraping-Vorgänge mit PromptCloud
Die Skalierung von Web-Scraping-Vorgängen zur Verarbeitung großer Datenmengen stellt zahlreiche Herausforderungen dar, von der Aufrechterhaltung der Datenqualität über die Speicherverwaltung bis hin zur Gewährleistung eines effizienten Abrufs und der Verarbeitung. Mit den richtigen Strategien und Tools können diese Herausforderungen jedoch effektiv angegangen werden, sodass Unternehmen das volle Potenzial von Web Scraping für Wettbewerbsvorteile und fundierte Entscheidungen nutzen können.
PromptCloud bietet eine umfassende Suite von Lösungen, die darauf ausgelegt sind, die Komplexität groß angelegten Web Scrapings zu bewältigen. Durch den Einsatz fortschrittlicher Technologien und einer robusten Infrastruktur stellen wir sicher, dass Ihre Daten-Scraping-Vorgänge skalierbar, effizient und zuverlässig sind. Sind Sie bereit, Ihre Web-Scraping-Vorgänge zu skalieren und das volle Potenzial Ihrer Daten auszuschöpfen? Arbeiten Sie mit PromptCloud zusammen, um unsere hochmodernen Lösungen und Expertendienste zu nutzen. Kontaktieren Sie uns noch heute, um eine Demo zu vereinbaren und unsere Lösungen in Aktion zu sehen.