
Beherrschen von Webseiten-Scrapern: Ein Leitfaden für Anfänger zum Extrahieren von Online-Daten
Veröffentlicht: 2024-04-09Was sind Webseiten-Scraper?
Web Page Scraper ist ein Tool zum Extrahieren von Daten aus Websites. Es simuliert die menschliche Navigation, um bestimmte Inhalte zu sammeln. Anfänger nutzen diese Scraper häufig für verschiedene Aufgaben, darunter Marktforschung, Preisüberwachung und Datenerfassung für maschinelle Lernprojekte.
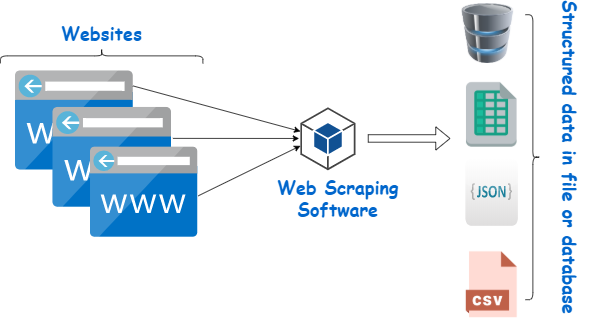
Bildquelle: https://www.webharvy.com/articles/what-is-web-scraping.html
- Benutzerfreundlichkeit: Sie sind benutzerfreundlich und ermöglichen es Personen mit minimalen technischen Kenntnissen, Webdaten effektiv zu erfassen.
- Effizienz: Scraper können große Datenmengen schnell erfassen und übertreffen damit die manuelle Datenerfassung bei weitem.
- Genauigkeit: Automatisiertes Scraping reduziert das Risiko menschlicher Fehler und erhöht die Datengenauigkeit.
- Kostengünstig: Sie machen manuelle Eingaben überflüssig und sparen Arbeitskosten und Zeit.
Das Verständnis der Funktionalität von Webseiten-Scrapern ist für jeden, der die Leistungsfähigkeit von Webdaten nutzen möchte, von entscheidender Bedeutung.
Erstellen eines einfachen Webseiten-Scrapers mit Python
Um mit der Erstellung eines Webseiten-Scrapers in Python zu beginnen, müssen bestimmte Bibliotheken installiert werden, nämlich „Requests“, um HTTP-Anfragen an eine Webseite zu stellen, und „BeautifulSoup“ von bs4 zum Parsen von HTML- und XML-Dokumenten.
- Sammelwerkzeuge:
- Bibliotheken: Verwenden Sie Anfragen zum Abrufen von Webseiten und BeautifulSoup zum Parsen des heruntergeladenen HTML-Inhalts.
- Ausrichtung auf die Webseite:
- Definieren Sie die URL der Webseite, die die Daten enthält, die wir extrahieren möchten.
- Herunterladen des Inhalts:
- Laden Sie mithilfe von Anfragen den HTML-Code der Webseite herunter.
- Parsen des HTML:
- BeautifulSoup wandelt den heruntergeladenen HTML-Code zur einfachen Navigation in ein strukturiertes Format um.
- Extrahieren der Daten:
- Identifizieren Sie die spezifischen HTML-Tags, die unsere gewünschten Informationen enthalten (z. B. Produkttitel innerhalb von <div>-Tags).
- Extrahieren und verarbeiten Sie mithilfe der BeautifulSoup-Methoden die benötigten Daten.
Denken Sie daran, auf bestimmte HTML-Elemente abzuzielen, die für die Informationen, die Sie extrahieren möchten, relevant sind.
Schritt-für-Schritt-Anleitung zum Scrapen einer Webseite
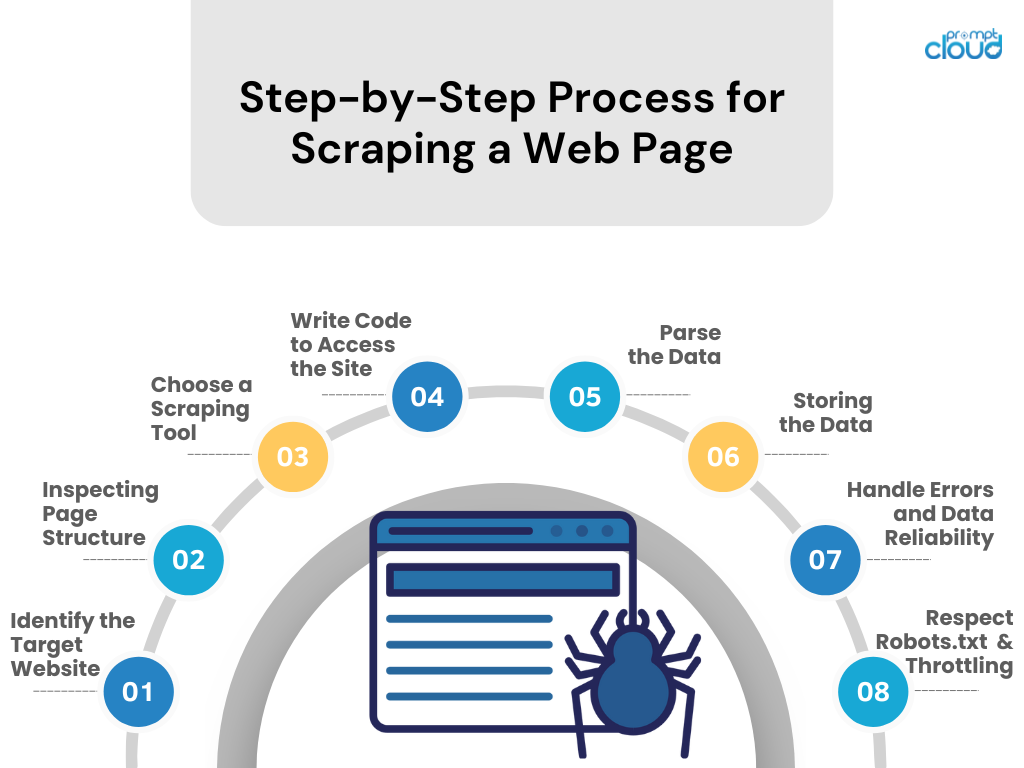
- Identifizieren Sie die Zielwebsite
Recherchieren Sie die Website, die Sie durchsuchen möchten. Stellen Sie sicher, dass dies legal und ethisch vertretbar ist. - Überprüfen der Seitenstruktur
Verwenden Sie die Entwicklertools des Browsers, um die HTML-Struktur, CSS-Selektoren und JavaScript-gesteuerte Inhalte zu untersuchen. - Wählen Sie ein Schabewerkzeug
Wählen Sie ein Tool oder eine Bibliothek in einer Programmiersprache aus, mit der Sie vertraut sind (z. B. BeautifulSoup oder Scrapy von Python). - Schreiben Sie Code, um auf die Site zuzugreifen
Erstellen Sie ein Skript, das Daten von der Website anfordert, indem Sie API-Aufrufe (sofern verfügbar) oder HTTP-Anfragen verwenden. - Analysieren Sie die Daten
Extrahieren Sie die relevanten Daten aus der Webseite, indem Sie HTML/CSS/JavaScript analysieren. - Speicherung der Daten
Speichern Sie die gescrapten Daten in einem strukturierten Format wie CSV, JSON oder direkt in einer Datenbank. - Umgang mit Fehlern und Datenzuverlässigkeit
Implementieren Sie eine Fehlerbehandlung, um Anforderungsfehler zu verwalten und die Datenintegrität aufrechtzuerhalten. - Respektieren Sie Robots.txt und Drosselung
Halten Sie sich an die robots.txt-Dateiregeln der Website und vermeiden Sie eine Überlastung des Servers, indem Sie die Anforderungsrate steuern.
Auswahl der idealen Web-Scraping-Tools für Ihre Anforderungen
Beim Durchsuchen des Internets ist die Auswahl von Tools, die Ihren Kenntnissen und Zielen entsprechen, von entscheidender Bedeutung. Anfänger sollten Folgendes berücksichtigen:
- Benutzerfreundlichkeit: Entscheiden Sie sich für intuitive Tools mit visueller Unterstützung und klarer Dokumentation.
- Datenanforderungen: Bewerten Sie die Struktur und Komplexität der Zieldaten, um festzustellen, ob eine einfache Erweiterung oder robuste Software erforderlich ist.
- Budget: Wägen Sie die Kosten gegen die Funktionen ab. Viele effektive Schaber bieten kostenlose Stufen an.
- Anpassung: Stellen Sie sicher, dass das Werkzeug an spezifische Schabeanforderungen angepasst werden kann.
- Support: Der Zugriff auf eine hilfreiche Benutzer-Community hilft bei der Fehlerbehebung und Verbesserung.
Wählen Sie mit Bedacht aus, um eine reibungslose Schabfahrt zu gewährleisten.
Tipps und Tricks zur Optimierung Ihres Webseiten-Scrapers
- Verwenden Sie effiziente Parsing-Bibliotheken wie BeautifulSoup oder Lxml in Python für eine schnellere HTML-Verarbeitung.
- Implementieren Sie Caching, um das erneute Herunterladen von Seiten zu vermeiden und die Belastung des Servers zu verringern.
- Respektieren Sie robots.txt-Dateien und verwenden Sie eine Ratenbegrenzung, um zu verhindern, dass sie von der Zielwebsite gesperrt werden.
- Rotieren Sie Benutzeragenten und Proxyserver, um menschliches Verhalten nachzuahmen und eine Erkennung zu vermeiden.
- Planen Sie Scraper außerhalb der Hauptverkehrszeiten ein, um die Auswirkungen auf die Website-Leistung zu minimieren.
- Entscheiden Sie sich für API-Endpunkte, sofern verfügbar, da diese strukturierte Daten bereitstellen und im Allgemeinen effizienter sind.
- Vermeiden Sie das Scrapen unnötiger Daten, indem Sie bei Ihren Abfragen selektiv vorgehen und so die erforderliche Bandbreite und den erforderlichen Speicher reduzieren.
- Aktualisieren Sie Ihre Scraper regelmäßig, um sie an Änderungen in der Website-Struktur anzupassen und die Datenintegrität zu wahren.
Umgang mit häufigen Problemen und Fehlerbehebung beim Webseiten-Scraping
Bei der Arbeit mit Webseiten-Scrapern können Anfänger mit mehreren häufigen Problemen konfrontiert sein:

- Selektorprobleme : Stellen Sie sicher, dass die Selektoren mit der aktuellen Struktur der Webseite übereinstimmen. Tools wie Browser-Entwicklertools können dabei helfen, die richtigen Selektoren zu identifizieren.
- Dynamischer Inhalt : Einige Webseiten laden Inhalte dynamisch mit JavaScript. Erwägen Sie in solchen Fällen die Verwendung von Headless-Browsern oder Tools, die JavaScript rendern.
- Blockierte Anfragen : Websites können Scraper blockieren. Setzen Sie Strategien wie rotierende Benutzeragenten, die Verwendung von Proxys und die Berücksichtigung von robots.txt ein, um Blockaden zu verringern.
- Probleme mit dem Datenformat : Extrahierte Daten müssen möglicherweise bereinigt oder formatiert werden. Verwenden Sie reguläre Ausdrücke und String-Manipulation, um die Daten zu standardisieren.
Denken Sie daran, die Dokumentation und Community-Foren zu konsultieren, um spezifische Anleitungen zur Fehlerbehebung zu erhalten.
Abschluss
Anfänger können jetzt bequem über den Webseiten-Scraper Daten aus dem Internet sammeln und so die Recherche und Analyse effizienter gestalten. Das Verständnis der richtigen Methoden unter Berücksichtigung rechtlicher und ethischer Aspekte ermöglicht es Benutzern, das volle Potenzial von Web Scraping auszuschöpfen. Befolgen Sie diese Richtlinien für einen reibungslosen Einstieg in das Webseiten-Scraping, gefüllt mit wertvollen Erkenntnissen und fundierter Entscheidungsfindung.
FAQs:
Was ist Scraping einer Seite?
Web Scraping, auch Data Scraping oder Web Harvesting genannt, besteht darin, mithilfe von Computerprogrammen, die menschliches Navigationsverhalten nachahmen, automatisch Daten von Websites zu extrahieren. Mit einem Webseiten-Scraper lassen sich große Mengen an Informationen schnell durchsuchen und sich dabei ausschließlich auf wichtige Abschnitte konzentrieren, anstatt sie manuell zusammenzustellen.
Unternehmen nutzen Web Scraping für Funktionen wie die Untersuchung von Kosten, die Verwaltung der Reputation, die Analyse von Trends und die Durchführung von Wettbewerbsanalysen. Bei der Implementierung von Web-Scraping-Projekten muss überprüft werden, ob die besuchten Websites mit der Aktion und Einhaltung aller relevanten robots.txt- und No-Follow-Protokolle einverstanden sind.
Wie scrape ich eine ganze Seite?
Um eine gesamte Webseite zu scannen, benötigen Sie im Allgemeinen zwei Komponenten: eine Möglichkeit, die erforderlichen Daten innerhalb der Webseite zu finden, und einen Mechanismus, um diese Daten an anderer Stelle zu speichern. Viele Programmiersprachen unterstützen Web Scraping, insbesondere Python und JavaScript.
Für beide existieren verschiedene Open-Source-Bibliotheken, die den Prozess noch weiter vereinfachen. Zu den beliebten Optionen unter Python-Entwicklern gehören BeautifulSoup, Requests, LXML und Scrapy. Alternativ ermöglichen kommerzielle Plattformen wie ParseHub und Octoparse weniger versierten Personen die visuelle Erstellung komplexer Web-Scraping-Workflows. Nachdem Sie die erforderlichen Bibliotheken installiert und die Grundkonzepte hinter der Auswahl von DOM-Elementen verstanden haben, beginnen Sie mit der Identifizierung der interessierenden Datenpunkte auf der Zielwebseite.
Nutzen Sie Browser-Entwicklertools, um HTML-Tags und -Attribute zu überprüfen und diese Ergebnisse dann in die entsprechende Syntax zu übersetzen, die von der ausgewählten Bibliothek oder Plattform unterstützt wird. Geben Sie abschließend die Einstellungen für das Ausgabeformat an, ob CSV, Excel, JSON, SQL oder eine andere Option, sowie die Ziele, an denen sich die gespeicherten Daten befinden.
Wie verwende ich den Google Scraper?
Entgegen der landläufigen Meinung bietet Google nicht direkt ein öffentliches Web-Scraping-Tool per se an, obwohl es APIs und SDKs bereitstellt, um eine nahtlose Integration mit mehreren Produkten zu ermöglichen. Dennoch haben erfahrene Entwickler Drittanbieterlösungen entwickelt, die auf den Kerntechnologien von Google basieren und so die Möglichkeiten effektiv über die native Funktionalität hinaus erweitern. Beispiele hierfür sind SerpApi, das komplizierte Aspekte der Google Search Console abstrahiert und eine benutzerfreundliche Oberfläche für die Verfolgung des Keyword-Rankings, die Schätzung des organischen Traffics und die Erkundung von Backlinks bietet.
Obwohl sie sich technisch vom herkömmlichen Web Scraping unterscheiden, verwischen diese Hybridmodelle die Grenzen zwischen herkömmlichen Definitionen. Andere Beispiele zeigen Reverse-Engineering-Bemühungen, die zur Rekonstruktion der internen Logik der Google Maps Platform, der YouTube Data API v3 oder der Google Shopping Services eingesetzt werden und zu Funktionen führen, die den ursprünglichen Gegenstücken bemerkenswert nahe kommen, wenn auch mit unterschiedlichem Grad an Legalitäts- und Nachhaltigkeitsrisiken. Letztendlich sollten angehende Webseiten-Scraper verschiedene Optionen erkunden und deren Vorteile im Hinblick auf bestimmte Anforderungen bewerten, bevor sie sich für einen bestimmten Weg entscheiden.
Ist Facebook Scraper legal?
Wie in den Facebook-Entwicklerrichtlinien angegeben, stellt unbefugtes Web-Scraping einen klaren Verstoß gegen die Community-Standards dar. Benutzer erklären sich damit einverstanden, keine Anwendungen, Skripte oder andere Mechanismen zu entwickeln oder zu betreiben, die darauf abzielen, festgelegte API-Ratengrenzen zu umgehen oder zu überschreiten, und auch nicht zu versuchen, irgendeinen Aspekt der Website oder des Dienstes zu entschlüsseln, zu dekompilieren oder zurückzuentwickeln. Darüber hinaus werden Erwartungen in Bezug auf Datenschutz und Privatsphäre hervorgehoben, da eine ausdrückliche Zustimmung des Benutzers erforderlich ist, bevor personenbezogene Daten außerhalb zulässiger Kontexte weitergegeben werden.
Jede Nichtbeachtung der dargelegten Grundsätze löst eskalierende Disziplinarmaßnahmen aus, die mit Verwarnungen beginnen und je nach Schweregrad schrittweise zu eingeschränktem Zugriff oder vollständigem Entzug von Berechtigungen führen. Ungeachtet der Ausnahmeregelungen für Sicherheitsforscher, die im Rahmen genehmigter Bug-Bounty-Programme arbeiten, plädiert der allgemeine Konsens dafür, nicht genehmigte Facebook-Scraping-Initiativen zu vermeiden, um unnötige Komplikationen zu vermeiden. Erwägen Sie stattdessen die Suche nach Alternativen, die mit den vorherrschenden Normen und Konventionen der Plattform kompatibel sind.