
Technische Herausforderungen beim Web Scraping meistern: Expertenlösungen
Veröffentlicht: 2024-03-29Web Scraping ist eine Praxis, die selbst für erfahrene Data Miner zahlreiche technische Herausforderungen mit sich bringt. Es erfordert den Einsatz von Programmiertechniken, um Daten von Websites zu erhalten und abzurufen, was aufgrund der Komplexität und Vielfalt der Webtechnologien nicht immer einfach ist.
Darüber hinaus verfügen viele Websites über Schutzmaßnahmen, um das Sammeln von Daten zu verhindern. Daher ist es für Scraper unerlässlich, Anti-Scraping-Mechanismen, dynamische Inhalte und komplizierte Website-Strukturen auszuhandeln.
Auch wenn das Ziel, sich schnell nützliche Informationen zu beschaffen, einfach erscheint, erfordert der Weg dorthin die Überwindung mehrerer gewaltiger Hürden, die ausgeprägte analytische und technische Fähigkeiten erfordern.
Umgang mit dynamischen Inhalten
Dynamische Inhalte, bei denen es sich um Webseiteninformationen handelt, die basierend auf Benutzeraktionen aktualisiert oder nach dem ersten Seitenaufruf geladen werden, stellen Web-Scraping-Tools häufig vor Herausforderungen.
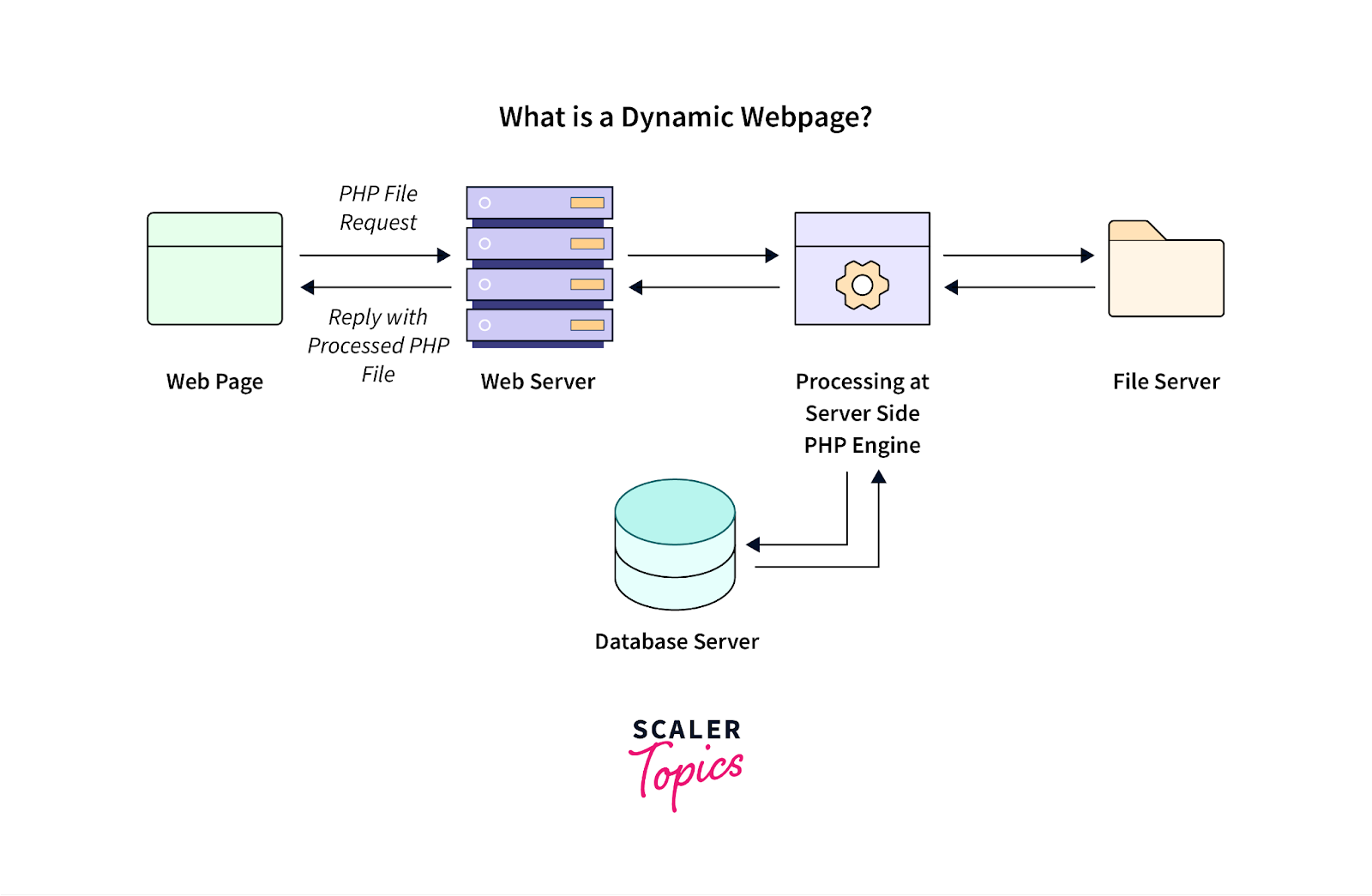
Bildquelle: https://www.scaler.com/topics/php-tutorial/dynamic-website-in-php/
Solche dynamischen Inhalte werden häufig in modernen Webanwendungen verwendet, die mit JavaScript-Frameworks erstellt wurden. Um Daten aus solchen dynamisch generierten Inhalten erfolgreich zu verwalten und zu extrahieren, sollten Sie die folgenden Best Practices berücksichtigen:
- Erwägen Sie die Verwendung von Web-Automatisierungstools wie Selenium, Puppeteer oder Playwright, die es Ihrem Web-Scraper ermöglichen, sich auf der Webseite ähnlich zu verhalten, wie es ein echter Benutzer tun würde.
- Implementieren Sie WebSockets- oder AJAX- Verarbeitungstechniken, wenn die Website diese Technologien verwendet, um Inhalte dynamisch zu laden.
- Warten Sie, bis die Elemente geladen sind, indem Sie in Ihrem Scraping-Code explizite Wartezeiten verwenden, um sicherzustellen, dass der Inhalt vollständig geladen ist, bevor Sie versuchen, ihn zu scrapen.
- Entdecken Sie die Verwendung von Headless-Browsern , die JavaScript ausführen und die gesamte Seite einschließlich dynamisch geladener Inhalte rendern können.
Durch die Beherrschung dieser Strategien können Scraper effektiv Daten selbst aus den interaktivsten und sich dynamisch verändernden Websites extrahieren.
Anti-Scraping-Technologien
Es ist üblich, dass Webentwickler Maßnahmen ergreifen, um unbefugtes Daten-Scraping zu verhindern, um ihre Websites zu schützen. Diese Maßnahmen können Web-Scraper vor erhebliche Herausforderungen stellen. Hier sind verschiedene Methoden und Strategien zur Navigation durch Anti-Scraping-Technologien:

Bildquelle: https://kinsta.com/knowledgebase/what-is-web-scraping/
- Dynamisches Factoring : Websites können Inhalte dynamisch generieren, wodurch es schwieriger wird, URLs oder HTML-Strukturen vorherzusagen. Nutzen Sie Tools, die JavaScript ausführen und AJAX-Anfragen verarbeiten können.
- IP-Blockierung : Häufige Anfragen von derselben IP können zu Blockierungen führen. Verwenden Sie einen Pool von Proxyservern, um IPs zu rotieren und menschliche Verkehrsmuster nachzuahmen.
- CAPTCHAs : Diese dienen der Unterscheidung zwischen Menschen und Bots. Nutzen Sie CAPTCHA-Lösungsdienste oder entscheiden Sie sich für die manuelle Eingabe, wenn möglich.
- Ratenbegrenzung : Um Ratenbegrenzungen zu vermeiden, drosseln Sie Ihre Anfrageraten und implementieren Sie zufällige Verzögerungen zwischen Anfragen.
- User-Agent : Websites blockieren möglicherweise bekannte Scraper-User-Agents. Rotieren Sie Benutzeragenten, um verschiedene Browser oder Geräte zu imitieren.
Die Bewältigung dieser Herausforderungen erfordert einen ausgefeilten Ansatz, der die Nutzungsbedingungen der Website respektiert und gleichzeitig effizient auf die benötigten Daten zugreift.
Umgang mit CAPTCHA und Honeypot-Fallen
Web-Scraper stoßen häufig auf CAPTCHA-Herausforderungen, die darauf abzielen, menschliche Benutzer von Bots zu unterscheiden. Um dies zu überwinden, ist Folgendes erforderlich:
- Nutzung von CAPTCHA-Lösungsdiensten, die menschliche oder KI-Fähigkeiten nutzen.
- Implementierung von Verzögerungen und zufällige Anordnung von Anfragen, um menschliches Verhalten nachzuahmen.
Für Honeypot-Traps, die für Benutzer unsichtbar sind, aber automatisierte Skripte abfangen:
- Überprüfen Sie den Code der Website sorgfältig, um Interaktionen mit versteckten Links zu vermeiden.
- Weniger aggressive Kratzpraktiken anwenden, um unter dem Radar zu bleiben.
Entwickler müssen die Wirksamkeit ethisch mit der Einhaltung der Website-Bedingungen und der Benutzererfahrung in Einklang bringen.
Scraping-Effizienz und Geschwindigkeitsoptimierung
Web-Scraping-Prozesse können durch die Optimierung von Effizienz und Geschwindigkeit verbessert werden. Um Herausforderungen in diesem Bereich zu meistern:
- Nutzen Sie Multithreading, um eine gleichzeitige Datenextraktion zu ermöglichen und so den Durchsatz zu erhöhen.
- Nutzen Sie Headless-Browser für eine schnellere Ausführung, indem Sie unnötiges Laden grafischer Inhalte vermeiden.
- Optimieren Sie den Scraping-Code für die Ausführung mit minimaler Latenz.
- Implementieren Sie eine geeignete Anforderungsdrosselung, um IP-Verbote zu verhindern und gleichzeitig ein stabiles Tempo aufrechtzuerhalten.
- Statische Inhalte zwischenspeichern, um wiederholte Downloads zu vermeiden und so Bandbreite und Zeit zu sparen.
- Nutzen Sie asynchrone Programmiertechniken, um Netzwerk-E/A-Vorgänge zu optimieren.
- Wählen Sie effiziente Selektoren und Parsing-Bibliotheken, um den Aufwand der DOM-Manipulation zu reduzieren.
Durch die Integration dieser Strategien können Web-Scraper eine robuste Leistung bei minimierten Betriebsstörungen erzielen.

Datenextraktion und -analyse
Web Scraping erfordert eine präzise Datenextraktion und -analyse, was besondere Herausforderungen mit sich bringt. Hier sind Möglichkeiten, sie anzugehen:
- Verwenden Sie robuste Bibliotheken wie BeautifulSoup oder Scrapy, die mit verschiedenen HTML-Strukturen umgehen können.
- Implementieren Sie reguläre Ausdrücke vorsichtig, um gezielt auf bestimmte Muster abzuzielen.
- Nutzen Sie Browser-Automatisierungstools wie Selenium, um mit JavaScript-lastigen Websites zu interagieren und sicherzustellen, dass die Daten vor der Extraktion gerendert werden.
- Nutzen Sie XPath- oder CSS-Selektoren für die genaue Lokalisierung von Datenelementen im DOM.
- Behandeln Sie Paginierung und unendliches Scrollen, indem Sie den Mechanismus identifizieren und manipulieren, der neue Inhalte lädt (z. B. Aktualisieren von URL-Parametern oder Behandeln von AJAX-Aufrufen).
Die Kunst des Web Scraping beherrschen
Web Scraping ist eine unschätzbare Fähigkeit in der datengesteuerten Welt. Die Bewältigung technischer Herausforderungen – von dynamischen Inhalten bis hin zur Bot-Erkennung – erfordert Ausdauer und Anpassungsfähigkeit. Erfolgreiches Web Scraping erfordert eine Mischung dieser Ansätze:
- Implementieren Sie intelligentes Crawling, um Website-Ressourcen zu schonen und unbemerkt zu navigieren.
- Nutzen Sie erweitertes Parsing zur Verarbeitung dynamischer Inhalte und stellen Sie sicher, dass die Datenextraktion robust gegenüber Änderungen ist.
- Setzen Sie CAPTCHA-Lösungsdienste strategisch ein, um den Zugriff aufrechtzuerhalten, ohne den Datenfluss zu unterbrechen.
- Verwalten Sie IP-Adressen und Anforderungsheader sorgfältig, um Scraping-Aktivitäten zu verschleiern.
- Behandeln Sie Änderungen an der Website-Struktur, indem Sie Parser-Skripte regelmäßig aktualisieren.
Durch die Beherrschung dieser Techniken kann man die Feinheiten des Web-Crawlings geschickt bewältigen und riesige Mengen wertvoller Daten erschließen.
Verwaltung großer Scraping-Projekte
Große Web-Scraping-Projekte erfordern ein robustes Management, um Effizienz und Compliance sicherzustellen. Die Partnerschaft mit Web-Scraping-Dienstleistern bietet mehrere Vorteile:

Wenn Sie Scraping-Projekte Profis anvertrauen, können Sie die Ergebnisse optimieren und die technische Belastung Ihres internen Teams minimieren.
FAQs
Welche Einschränkungen gibt es beim Web Scraping?
Web Scraping unterliegt bestimmten Einschränkungen, die man berücksichtigen muss, bevor man es in seine Abläufe integriert. Einige Websites verbieten das Scraping über Geschäftsbedingungen oder robot.txt-Dateien; Das Ignorieren dieser Einschränkungen könnte schwerwiegende Folgen haben.
Technisch gesehen können Websites Gegenmaßnahmen gegen Scraping wie CAPTCHAs, IP-Blockierungen und Honey Pots einsetzen und so unbefugten Zugriff verhindern. Auch die Genauigkeit der extrahierten Daten kann aufgrund der dynamischen Darstellung und häufig aktualisierter Quellen zu einem Problem werden. Schließlich erfordert Web Scraping technisches Know-how, Investitionen in Ressourcen und kontinuierliche Anstrengungen – was insbesondere für technisch nicht versierte Personen eine Herausforderung darstellt.
Warum ist Data Scraping ein Problem?
Probleme treten vor allem dann auf, wenn Daten-Scraping ohne erforderliche Genehmigungen oder ethisches Verhalten erfolgt. Das Extrahieren vertraulicher Informationen verstößt gegen Datenschutznormen und verstößt gegen Gesetze zum Schutz individueller Interessen.
Übermäßiger Einsatz von Scraping belastet die Zielserver und wirkt sich negativ auf Leistung und Verfügbarkeit aus. Der Diebstahl von geistigem Eigentum stellt ein weiteres Problem dar, das sich aus illegalem Scraping ergibt, da die geschädigten Parteien möglicherweise Klagen wegen Urheberrechtsverletzung einreichen.
Daher ist es bei der Durchführung von Data-Scraping-Aufgaben nach wie vor von entscheidender Bedeutung, sich an politische Vorgaben zu halten, ethische Standards einzuhalten und bei Bedarf die Zustimmung einzuholen.
Warum ist Web Scraping möglicherweise ungenau?
Beim Web Scraping, bei dem mithilfe spezieller Software automatisch Daten von Websites extrahiert werden, kann aufgrund verschiedener Faktoren keine vollständige Genauigkeit gewährleistet werden. Beispielsweise könnten Änderungen in der Website-Struktur dazu führen, dass das Scraper-Tool nicht richtig funktioniert oder fehlerhafte Informationen erfasst.
Darüber hinaus implementieren bestimmte Websites Anti-Scraping-Maßnahmen wie CAPTCHA-Tests, IP-Blockierungen oder JavaScript-Rendering, was zu fehlenden oder verzerrten Daten führt. Gelegentlich tragen auch Versäumnisse der Entwickler während der Erstellung zu suboptimalen Ergebnissen bei.
Die Zusammenarbeit mit kompetenten Web-Scraping-Dienstleistern kann jedoch die Präzision steigern, da diese über das erforderliche Know-how und die Ressourcen verfügen, um belastbare und flinke Scraper zu entwickeln, die trotz wechselnder Website-Layouts ein hohes Genauigkeitsniveau aufrechterhalten können. Erfahrene Experten testen und validieren diese Schaber vor der Implementierung sorgfältig und stellen so die Korrektheit während des gesamten Extraktionsprozesses sicher.
Ist Web Scraping mühsam?
Tatsächlich kann sich die Teilnahme an Web-Scraping-Aktivitäten als mühsam und anspruchsvoll erweisen, insbesondere für diejenigen, denen es an Programmierkenntnissen oder Verständnis für digitale Plattformen mangelt. Für solche Aufgaben ist es erforderlich, maßgeschneiderte Codes zu erstellen, fehlerhafte Scraper zu beheben, Serverarchitekturen zu verwalten und über Änderungen auf den Zielwebsites auf dem Laufenden zu bleiben – alles erfordert erhebliche technische Fähigkeiten und erhebliche Zeitinvestitionen.
Die Erweiterung über grundlegende Web-Scraping-Unternehmungen hinaus wird angesichts von Überlegungen zur Einhaltung gesetzlicher Vorschriften, zur Bandbreitenverwaltung und zur Implementierung verteilter Computersysteme immer komplexer.
Im Gegensatz dazu verringert die Entscheidung für professionelle Web-Scraping-Dienste die damit verbundenen Belastungen durch vorgefertigte Angebote, die auf benutzerspezifische Anforderungen zugeschnitten sind, erheblich. Folglich konzentrieren sich die Kunden in erster Linie auf die Nutzung der gesammelten Daten, während die Erfassungslogistik dedizierten Teams aus erfahrenen Entwicklern und IT-Spezialisten überlassen wird, die für die Systemoptimierung, Ressourcenzuweisung und die Beantwortung rechtlicher Fragen verantwortlich sind, wodurch die allgemeine Langeweile im Zusammenhang mit Web-Scraping-Initiativen deutlich reduziert wird.