
Python Web Crawler – Schritt-für-Schritt-Anleitung
Veröffentlicht: 2023-12-07Webcrawler sind faszinierende Werkzeuge in der Welt der Datenerfassung und des Web Scrapings. Sie automatisieren den Prozess der Navigation im Internet, um Daten zu sammeln, die für verschiedene Zwecke verwendet werden können, beispielsweise für die Indexierung durch Suchmaschinen, Data Mining oder Wettbewerbsanalysen. In diesem Tutorial begeben wir uns auf eine informative Reise zum Erstellen eines einfachen Webcrawlers mit Python, einer Sprache, die für ihre Einfachheit und leistungsstarken Funktionen im Umgang mit Webdaten bekannt ist.
Python bietet mit seinem umfangreichen Ökosystem an Bibliotheken eine hervorragende Plattform für die Entwicklung von Webcrawlern. Egal, ob Sie ein angehender Entwickler, ein Datenbegeisterter oder einfach nur neugierig auf die Funktionsweise von Webcrawlern sind, diese Schritt-für-Schritt-Anleitung soll Sie in die Grundlagen des Webcrawlens einführen und Ihnen die Fähigkeiten vermitteln, Ihren eigenen Crawler zu erstellen .
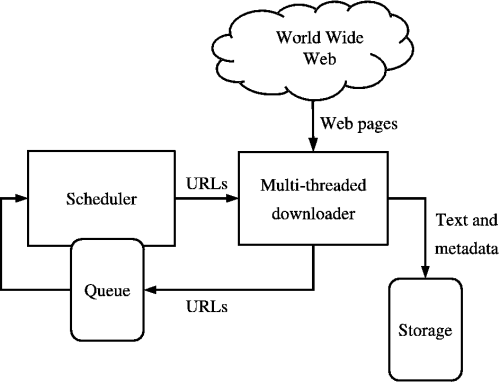
Quelle: https://medium.com/kariyertech/web-crawling-general-perspective-713971e9c659
Python Web Crawler – So erstellen Sie einen Web Crawler
Schritt 1: Die Grundlagen verstehen
Ein Webcrawler, auch Spider genannt, ist ein Programm, das das World Wide Web systematisch und automatisiert durchsucht. Für unseren Crawler verwenden wir Python aufgrund seiner Einfachheit und leistungsstarken Bibliotheken.
Schritt 2: Richten Sie Ihre Umgebung ein
Python installieren : Stellen Sie sicher, dass Python installiert ist. Sie können es von python.org herunterladen.
Bibliotheken installieren : Sie benötigen Anfragen zum Senden von HTTP-Anfragen und BeautifulSoup von bs4 zum Parsen von HTML. Installieren Sie sie mit pip:
Pip-Installationsanfragen pip install beautifulsoup4
Schritt 3: Schreiben Sie einen einfachen Crawler
Bibliotheken importieren :
Importanfragen von bs4 import BeautifulSoup
Rufen Sie eine Webseite ab :
Hier rufen wir den Inhalt einer Webseite ab. Ersetzen Sie „URL“ durch die Webseite, die Sie crawlen möchten.
url = 'URL' Antwort = Anfragen.get(URL) Inhalt = Antwort.Inhalt
Analysieren Sie den HTML-Inhalt :
Suppe = BeautifulSoup(content, 'html.parser')
Informationen extrahieren :
Um beispielsweise alle Hyperlinks zu extrahieren, können Sie Folgendes tun:
für Link in Suppe.find_all('a'): print(link.get('href'))
Schritt 4: Erweitern Sie Ihren Crawler
Umgang mit relativen URLs :
Verwenden Sie urljoin, um relative URLs zu verarbeiten.
aus urllib.parse importieren urljoin
Vermeiden Sie es, dieselbe Seite zweimal zu crawlen :
Behalten Sie eine Reihe besuchter URLs bei, um Redundanz zu vermeiden.
Verzögerungen hinzufügen :
Beim respektvollen Crawlen kommt es zu Verzögerungen zwischen Anfragen. Verwenden Sie time.sleep().
Schritt 5: Respektieren Sie Robots.txt
Stellen Sie sicher, dass Ihr Crawler die robots.txt-Datei von Websites berücksichtigt, die angibt, welche Teile der Website nicht gecrawlt werden sollen.
Schritt 6: Fehlerbehandlung
Implementieren Sie Try-Except-Blöcke, um potenzielle Fehler wie Verbindungszeitüberschreitungen oder verweigerten Zugriff zu behandeln.
Schritt 7: Tiefer gehen
Sie können Ihren Crawler erweitern, um komplexere Aufgaben wie Formularübermittlungen oder JavaScript-Rendering zu bewältigen. Erwägen Sie für JavaScript-lastige Websites die Verwendung von Selenium.
Schritt 8: Speichern Sie die Daten
Entscheiden Sie, wie die von Ihnen gecrawlten Daten gespeichert werden sollen. Zu den Optionen gehören einfache Dateien, Datenbanken oder sogar das direkte Senden von Daten an einen Server.
Schritt 9: Seien Sie ethisch
- Überlasten Sie die Server nicht. Fügen Sie Verzögerungen bei Ihren Anfragen hinzu.
- Befolgen Sie die Nutzungsbedingungen der Website.
- Scrapen oder speichern Sie personenbezogene Daten nicht ohne Erlaubnis.
Beim Web-Crawling stellt die Blockierung eine häufige Herausforderung dar, insbesondere wenn es sich um Websites handelt, die über Maßnahmen zur Erkennung und Blockierung automatisierter Zugriffe verfügen. Hier sind einige Strategien und Überlegungen, die Ihnen bei der Bewältigung dieses Problems in Python helfen sollen:
Verstehen, warum Sie blockiert werden
Häufige Anfragen: Schnelle, wiederholte Anfragen von derselben IP können eine Blockierung auslösen.
Nicht-menschliche Muster: Bots zeigen häufig Verhaltensweisen, die sich von menschlichen Browsing-Mustern unterscheiden, z. B. den Zugriff auf Seiten zu schnell oder in einer vorhersehbaren Reihenfolge.
Missmanagement von Headern: Fehlende oder falsche HTTP-Header können Ihre Anfragen verdächtig erscheinen lassen.
Ignorieren von robots.txt: Die Nichtbeachtung der Anweisungen in der robots.txt-Datei einer Website kann zu Blockaden führen.
Strategien zur Vermeidung von Blockaden
Respektieren Sie robots.txt : Überprüfen Sie immer die robots.txt-Datei der Website und befolgen Sie diese. Dies ist eine ethische Vorgehensweise und kann unnötige Blockierungen verhindern.
Rotierende Benutzeragenten : Websites können Sie über Ihren Benutzeragenten identifizieren. Durch die Rotation verringern Sie das Risiko, als Bot gekennzeichnet zu werden. Verwenden Sie die Bibliothek fake_useragent, um dies zu implementieren.
from fake_useragent import UserAgent ua = UserAgent() headers = {'User-Agent': ua.random}
Verzögerungen hinzufügen : Das Implementieren einer Verzögerung zwischen Anfragen kann menschliches Verhalten nachahmen. Verwenden Sie time.sleep(), um eine zufällige oder feste Verzögerung hinzuzufügen.

Importzeit time.sleep(3) # Wartet 3 Sekunden
IP-Rotation : Verwenden Sie nach Möglichkeit Proxy-Dienste, um Ihre IP-Adresse zu rotieren. Hierfür stehen sowohl kostenlose als auch kostenpflichtige Dienste zur Verfügung.
Verwenden von Sitzungen : Ein „requests.Session“-Objekt in Python kann dabei helfen, eine konsistente Verbindung aufrechtzuerhalten und Header, Cookies usw. über mehrere Anfragen hinweg zu teilen, sodass Ihr Crawler eher wie eine normale Browsersitzung aussieht.
mit request.Session() als Sitzung: session.headers = {'User-Agent': ua.random} Response = session.get(url)
Umgang mit JavaScript : Einige Websites verlassen sich zum Laden von Inhalten stark auf JavaScript. Tools wie Selenium oder Puppeteer können einen echten Browser nachahmen, einschließlich JavaScript-Rendering.
Fehlerbehandlung : Implementieren Sie eine robuste Fehlerbehandlung, um Blockierungen oder andere Probleme elegant zu verwalten und darauf zu reagieren.
Ethische Überlegungen
- Respektieren Sie immer die Nutzungsbedingungen einer Website. Wenn eine Website Web Scraping ausdrücklich verbietet, ist es am besten, sich daran zu halten.
- Bedenken Sie die Auswirkungen Ihres Crawlers auf die Ressourcen der Website. Die Überlastung eines Servers kann für den Websitebesitzer zu Problemen führen.
Fortgeschrittene Techniken
- Web-Scraping-Frameworks : Erwägen Sie die Verwendung von Frameworks wie Scrapy, die über integrierte Funktionen zur Bewältigung verschiedener Crawling-Probleme verfügen.
- CAPTCHA-Lösungsdienste : Für Websites mit CAPTCHA-Herausforderungen gibt es Dienste, die CAPTCHAs lösen können, obwohl ihre Verwendung ethische Bedenken aufwirft.
Beste Web-Crawling-Praktiken in Python
Die Teilnahme an Web-Crawling-Aktivitäten erfordert ein Gleichgewicht zwischen technischer Effizienz und ethischer Verantwortung. Wenn Sie Python zum Webcrawlen verwenden, ist es wichtig, sich an Best Practices zu halten, die die Daten und die Websites, von denen sie stammen, respektieren. Hier sind einige wichtige Überlegungen und Best Practices für das Webcrawlen in Python:
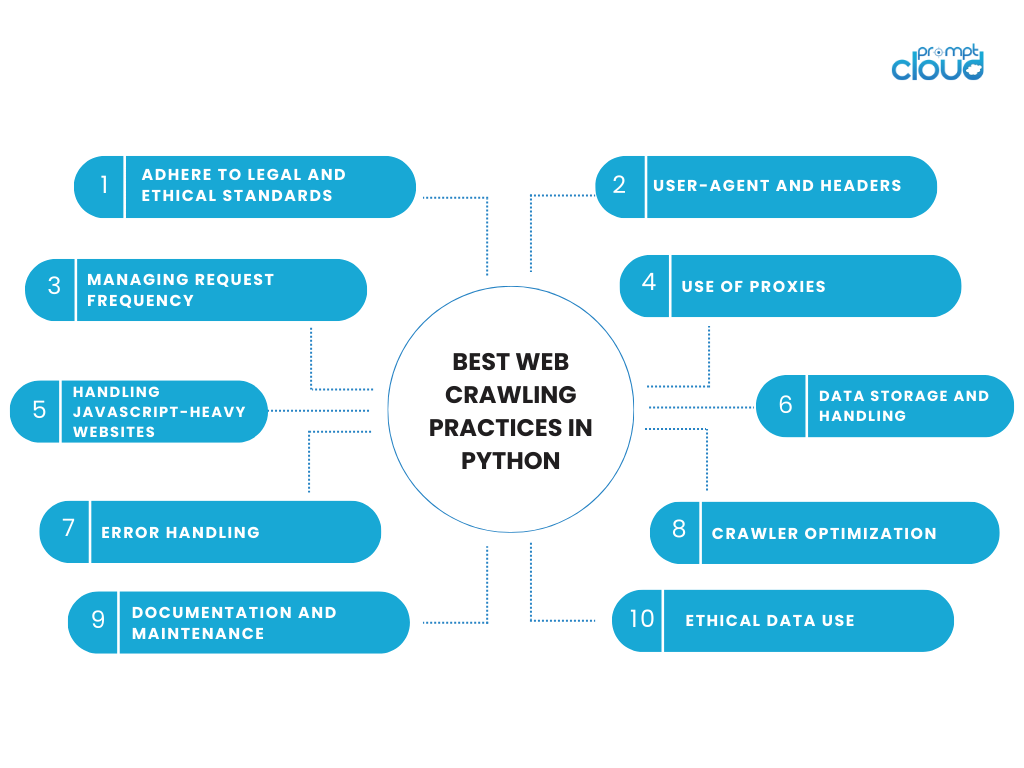
Halten Sie sich an rechtliche und ethische Standards
- Respektieren Sie robots.txt: Überprüfen Sie immer die robots.txt-Datei der Website. In dieser Datei werden die Bereiche der Website beschrieben, die der Websitebesitzer nicht crawlen möchte.
- Befolgen Sie die Nutzungsbedingungen: Viele Websites enthalten Klauseln zum Web Scraping in ihren Nutzungsbedingungen. Die Einhaltung dieser Bedingungen ist sowohl ethisch als auch rechtlich sinnvoll.
- Vermeiden Sie eine Überlastung der Server: Stellen Sie Anfragen in einem angemessenen Tempo, um eine übermäßige Belastung des Servers der Website zu vermeiden.
User-Agent und Header
- Identifizieren Sie sich: Verwenden Sie eine User-Agent-Zeichenfolge, die Ihre Kontaktinformationen oder den Zweck Ihres Crawls enthält. Diese Transparenz kann Vertrauen schaffen.
- Verwenden Sie Header angemessen: Gut konfigurierte HTTP-Header können die Wahrscheinlichkeit einer Blockierung verringern. Sie können Informationen wie User-Agent, Accept-Language usw. enthalten.
Verwalten der Anforderungshäufigkeit
- Verzögerungen hinzufügen: Implementieren Sie eine Verzögerung zwischen Anfragen, um menschliche Browsing-Muster nachzuahmen. Verwenden Sie die Funktion time.sleep() von Python.
- Ratenbegrenzung: Achten Sie darauf, wie viele Anfragen Sie innerhalb eines bestimmten Zeitraums an eine Website senden.
Verwendung von Proxys
- IP-Rotation: Die Verwendung von Proxys zur Rotation Ihrer IP-Adresse kann dazu beitragen, IP-basierte Blockierungen zu vermeiden, sollte jedoch verantwortungsbewusst und ethisch erfolgen.
Umgang mit JavaScript-lastigen Websites
- Dynamischer Inhalt: Bei Websites, die Inhalte dynamisch mit JavaScript laden, können Tools wie Selenium oder Puppeteer (in Kombination mit Pyppeteer für Python) die Seiten wie ein Browser rendern.
Datenspeicherung und -verarbeitung
- Datenspeicherung: Bewahren Sie die gecrawlten Daten verantwortungsvoll und unter Berücksichtigung der Datenschutzgesetze und -vorschriften auf.
- Minimieren Sie die Datenextraktion: Extrahieren Sie nur die Daten, die Sie benötigen. Vermeiden Sie es, persönliche oder sensible Daten zu sammeln, es sei denn, dies ist unbedingt notwendig und legal.
Fehlerbehandlung
- Robuste Fehlerbehandlung: Implementieren Sie eine umfassende Fehlerbehandlung, um Probleme wie Zeitüberschreitungen, Serverfehler oder Inhalte, die nicht geladen werden können, zu verwalten.
Crawler-Optimierung
- Skalierbarkeit: Gestalten Sie Ihren Crawler so, dass er mit zunehmender Skalierung zurechtkommt, sowohl im Hinblick auf die Anzahl der gecrawlten Seiten als auch auf die Menge der verarbeiteten Daten.
- Effizienz: Optimieren Sie Ihren Code für mehr Effizienz. Effizienter Code reduziert die Belastung sowohl Ihres Systems als auch des Zielservers.
Dokumentation und Wartung
- Dokumentation aufbewahren: Dokumentieren Sie Ihren Code und Ihre Crawling-Logik für zukünftige Referenz- und Wartungszwecke.
- Regelmäßige Updates: Halten Sie Ihren Crawling-Code auf dem neuesten Stand, insbesondere wenn sich die Struktur der Zielwebsite ändert.
Ethische Datennutzung
- Ethische Nutzung: Verwenden Sie die von Ihnen gesammelten Daten auf ethische Weise und respektieren Sie dabei die Privatsphäre der Benutzer und die Datennutzungsnormen.
Abschließend
Zum Abschluss unserer Erkundung der Erstellung eines Webcrawlers in Python haben wir uns mit den Feinheiten der automatisierten Datenerfassung und den damit verbundenen ethischen Überlegungen befasst. Dieses Unterfangen erweitert nicht nur unsere technischen Fähigkeiten, sondern vertieft auch unser Verständnis für den verantwortungsvollen Umgang mit Daten in der riesigen digitalen Landschaft.
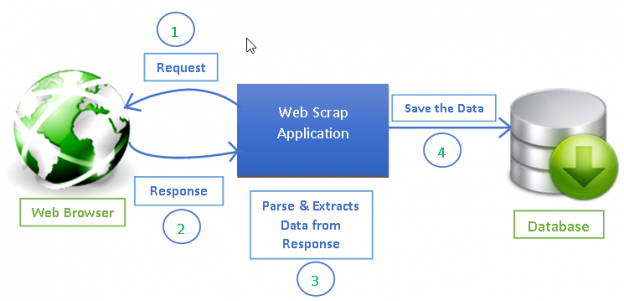
Quelle: https://www.datacamp.com/tutorial/making-web-crawlers-scrapy-python
Allerdings kann die Erstellung und Pflege eines Webcrawlers eine komplexe und zeitaufwändige Aufgabe sein, insbesondere für Unternehmen mit spezifischen, umfangreichen Datenanforderungen. Hier kommen die benutzerdefinierten Web-Scraping-Dienste von PromptCloud ins Spiel. Wenn Sie nach einer maßgeschneiderten, effizienten und ethischen Lösung für Ihre Webdatenanforderungen suchen, bietet PromptCloud eine Reihe von Diensten an, die Ihren individuellen Anforderungen gerecht werden. Von der Bearbeitung komplexer Websites bis hin zur Bereitstellung sauberer, strukturierter Daten stellen sie sicher, dass Ihre Web-Scraping-Projekte problemlos ablaufen und auf Ihre Geschäftsziele abgestimmt sind.
Für Unternehmen und Einzelpersonen, die möglicherweise nicht über die Zeit oder das technische Fachwissen verfügen, um ihre eigenen Webcrawler zu entwickeln und zu verwalten, kann die Auslagerung dieser Aufgabe an Experten wie PromptCloud eine entscheidende Wende sein. Ihre Dienste sparen nicht nur Zeit und Ressourcen, sondern stellen auch sicher, dass Sie die genauesten und relevantesten Daten erhalten und dabei rechtliche und ethische Standards einhalten.
Möchten Sie mehr darüber erfahren, wie PromptCloud auf Ihre spezifischen Datenanforderungen eingehen kann? Kontaktieren Sie sie unter sales@promptcloud.com für weitere Informationen und um zu besprechen, wie ihre maßgeschneiderten Web-Scraping-Lösungen Ihr Unternehmen voranbringen können.
In der dynamischen Welt der Webdaten kann ein zuverlässiger Partner wie PromptCloud Ihr Unternehmen stärken und Ihnen einen Vorsprung bei der datengesteuerten Entscheidungsfindung verschaffen. Denken Sie daran, dass im Bereich der Datenerfassung und -analyse der richtige Partner den entscheidenden Unterschied macht.
Viel Spaß beim Datensuchen!