
Warum unsere Kunden uns lieben
Veröffentlicht: 2017-02-07Als DaaS-Anbieter war das Extrahieren hochwertiger Daten aus dem Internet für umfangreiche Geschäftsanforderungen schon immer unser Hauptaugenmerk. Im Laufe der Zeit haben wir uns mit einem hochmodernen Technologiestack und einer leistungsstarken Infrastruktur ausgestattet, die dies mit hoher Effizienz ermöglichen. Die große Reichweite und Vielseitigkeit unseres Crawling-Systems ist etwas, das unsere Kunden glücklich macht. Wir möchten mit Ihnen einige der einzigartigen Leistungsversprechen teilen, die Unternehmen dazu veranlassen, sich für uns zu entscheiden und eine langfristige Partnerschaft mit uns aufzubauen. (Einige sind seit mehr als fünf Jahren bei uns).

Hochgradig skalierbar
Big Data wird mit seiner Größe besser. Je größer Ihre Datensätze sind, desto höher ist Ihr Vorteil. Das Extrahieren solch großer Datenmengen erfordert jedoch ein robustes Setup. Das ist etwas, das uns im Big-Data-Spiel auszeichnet. Unsere Web-Crawling-Infrastruktur zeichnet sich durch eine hohe Skalierbarkeit aus, dank der dynamischen und flexiblen Tools, die wir zusammen mit verteilten Maschinen integriert haben, die komplexe Aufgaben reibungslos ablaufen lassen. Da die Größe für die meisten unserer Unternehmenskunden eines der größten Anliegen ist, verschafft uns die Skalierbarkeit einen fairen Vorteil im Spiel.
Vertikaler Agnostiker
Wie von einem großen DaaS-Anbieter erwartet, ist unsere Lösung vertikal agnostisch. Es spielt keine Rolle, aus welcher Branche oder Domäne Sie Daten benötigen, unsere Lösung kann sie alle bedienen. Es gibt mehrere Crawling-Lösungen, die Systeme entwickelt haben, die nur in einer bestimmten Domäne gut funktionieren. Das Problem bei einem solchen Anbieter ist die Möglichkeit, verzerrte Daten zu erhalten. Schiefe Daten beziehen sich auf den Mangel an umfassenden Informationen, die sich aus der branchenspezifischen Datenextraktion ergeben. Mit unserem vertikalen, agnostischen Ansatz erhalten Sie jedoch Daten aus jeder vertikalen Branche mit genau der Liebe zum Detail, die Sie benötigen.
Vollständig anpassbar
Die Anpassung ist eines der größten Hindernisse, wenn es um die groß angelegte Extraktion von Webdaten geht. Viele Lösungen auf dem Markt sind nicht flexibel genug, um an die sich ständig ändernden Datenanforderungen von Organisationen angepasst zu werden. Wenn Sie beispielsweise eine Datenanforderung haben, bei der sich eine Ihrer Eingaben ständig ändert, können wir ein benutzerdefiniertes System einrichten, um Ihre dynamische Anforderung in Echtzeit abzurufen, um die Crawls zu steuern. Ein Beispiel wäre, wenn Sie Daten für verschiedene Datumsbereiche erhalten möchten. Sie könnten die Datumsbereiche auf Ihrem FTP-Server aktualisieren und wir würden den Crawl durchführen, indem wir sie in Echtzeit abrufen. Einfach ausgedrückt, unser Tech-Stack kann unabhängig von seiner Komplexität an Ihre Anforderungen angepasst werden.
Sofortige Unterstützung
Wir verstehen, dass ein schneller und reaktionsschneller Support unerlässlich ist, wenn es sich um einen technisch so komplexen Dienst wie Web-Crawling handelt. Bei PromptCloud haben wir dedizierte Projektmanager für jedes Kundenprojekt, das wir in Angriff nehmen. Neben einem benutzerfreundlichen Ticketing-System, mit dem Kunden schnelle Support-Tickets erstellen können, können sie auch direkt mit den technischen Teammitgliedern interagieren, die für die ganze schwere Arbeit verantwortlich sind. Dies schließt die Kommunikationslücke weitgehend aus und hilft, Probleme in Rekordzeit zu lösen.

Geringe Wartezeit
Viele Projekte, die wir durchführen, benötigen Daten mit möglichst geringer Latenz. Latenz bezieht sich hier auf die Zeit, die zum Abrufen neuer Daten, die auf der Zielseite aktualisiert wurden, ab dem Zeitpunkt der Aktualisierung erforderlich ist. Dies wird zu einem Deal Breaker, wenn Ihre Datenanforderungen zeitkritisch sind. Ein gutes Beispiel dafür ist Pricing Intelligence. Wenn Sie ein E-Commerce-Portal betreiben und eine Web-Crawling-Lösung verwenden, um die Preisstruktur eines Mitbewerbers zu erhalten, möchten Sie, dass dies mit minimaler Latenz effektiv genug ist. Unsere leistungsstarken Maschinen und die optimalen Crawling-Richtlinien sorgen zusammen dafür, dass die Crawls reibungslos, ohne Engpässe oder Verlangsamungen in der niedrigsten erreichbaren Latenz für einen Crawler ablaufen.
Instandhaltung
Wartung oder Instandhaltung ist ein wesentlicher Bestandteil jedes Web-Crawling-Projekts. Dies ist äußerst wichtig, da das Web von Natur aus sehr dynamisch ist. Ein Crawling-Setup, das heute noch funktioniert, könnte morgen fehlschlagen, selbst wenn die Zielwebsite eine scheinbar kleine Änderung vornimmt. Aus diesem Grund sind wir stolz auf die Wartung als einen unserer bemerkenswerten Vorteile. Wir verwenden dedizierte Überwachungssysteme, die Änderungen an den Zielseiten verfolgen und Warnungen versenden können, um unser Technikteam zu benachrichtigen, um umgehend Maßnahmen zu ergreifen. Dadurch wird die Möglichkeit eines Datenverlusts im Falle eines Fehlers bei den Crawls erheblich eliminiert.
Planen Sie ein internes Crawling?
Wir haben in letzter Zeit in einigen Organisationen einen wachsenden Wunsch festgestellt, den schwierigen Weg des internen Crawlings einzuschlagen. Es gibt mehrere Gründe, warum dies eine schlechte Idee ist. Zum einen würde Sie das interne Crawling in Form von Einstellungskosten, Infrastruktur, Wartung und Zeit mehr kosten. Der eigentliche Deal-Breaker ist jedoch der Fokusverlust, der Ihre Kerngeschäftsaktivitäten beeinträchtigen würde. Dies liegt daran, dass Web-Crawling ein Nischenprozess ist, der viel Aufmerksamkeit, Zeit und viel Mühe erfordert. Um Ihnen einen besseren Überblick zu geben, sind hier die Kostenpunkte aufgeführt, die mit einer internen Crawling-Einrichtung verbunden sind.
- Gehalt von Ingenieuren
- Kosten für Hardwareressourcen
- Wartungskosten
- Zeit
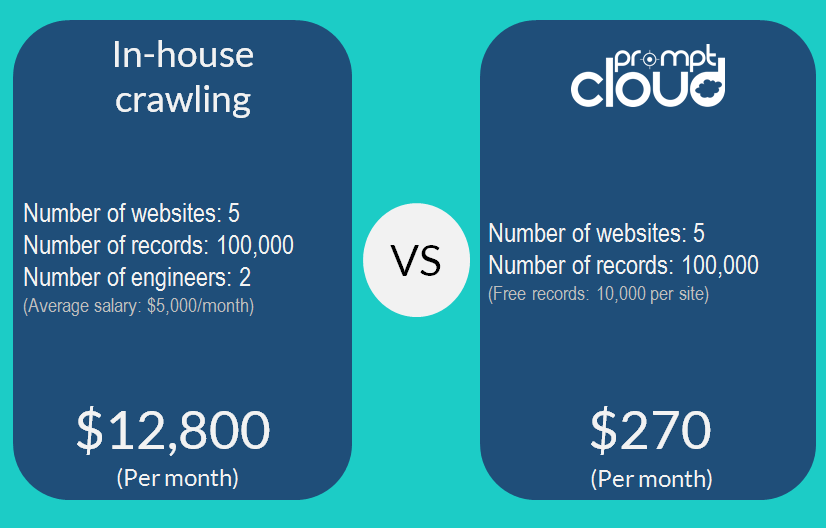
Mit unserem ROI-Rechner können Sie Inhouse-Crawling und unsere Lösung vergleichen.
Warum PromptCloud wählen?
Sie müssen uns nicht beim Wort glauben, warum Sie sich für unsere DaaS-Lösung für Ihre Anforderungen an die Extraktion von Webdaten entscheiden sollten. Wir hatten mehrere Kunden, die es mit internem Crawling versucht haben, um die Kosten zu senken, oder die Dienste anderer Anbieter in Anspruch genommen haben, bevor sie sich an uns gewandt haben. Die von ihnen geteilten Erfahrungen bestärken unser Vertrauen in unsere eigene Lösung als eine der besten Möglichkeiten, Daten aus dem Internet zu gewinnen. Hier sind einige Ausschnitte aus den Gesprächen, die wir mit unseren Kunden geführt haben.
„Andere Anbieter, die wir ausprobiert haben, konnten die Komplexität der Zielwebsite nicht bewältigen, und einige wichtige Felder fehlten.“ – Hichem Fadal.
„Ich habe von vielen Ihrer Konkurrenten Beispiel-CSVs erhalten, und sie waren extrem schlecht.“ – Daniel Sides.
„Wir haben selbst versucht, dieses Material selbst zu crawlen. Aber wir finden, dass unsere Bemühungen angesichts einer großen Anzahl von Lebensläufen zu zeitaufwändig sind und die Rechenanforderungen zur Beschleunigung des Prozesses ziemlich herausfordernd sind. –Robin Quek
Endeffekt
Wir bei PromptCloud glauben an die Kraft von Big Data als Geschäftsbeschleuniger und verstehen, warum unsere Kunden uns kontaktieren. Aus diesem Grund haben wir ein System entwickelt, das großen Anforderungen gerecht wird, die sehr unterschiedlich sein können und ein hohes Maß an Anpassung erfordern. Wenn Sie nach einer Lösung zur Extraktion von Webdaten suchen, die Sie nicht enttäuscht, ist es an der Zeit, sich an uns zu wenden.