
Auswählen und Konfigurieren von Inferenz-Engines für LLMs
Veröffentlicht: 2024-04-02Einführung in Inferenz-Engines
Es wurden viele Optimierungstechniken entwickelt, um die Ineffizienzen zu verringern, die in den verschiedenen Phasen des Inferenzprozesses auftreten. Es ist schwierig, die Schlussfolgerung mit Vanilla-Transformator-Techniken maßstabsgetreu zu skalieren. Inferenz-Engines fassen die Optimierungen in einem Paket zusammen und erleichtern uns den Inferenzprozess.
Für eine sehr kleine Reihe von Ad-hoc-Tests oder als Kurzreferenz können wir den Vanilla-Transformer-Code verwenden, um die Schlussfolgerung zu ziehen.
Die Landschaft der Inferenz-Engines entwickelt sich schnell weiter. Da wir mehrere Auswahlmöglichkeiten haben, ist es wichtig, die Besten der Besten für bestimmte Anwendungsfälle zu testen und in die engere Auswahl zu nehmen. Nachfolgend finden Sie einige von uns durchgeführte Inferenz-Engine-Experimente und die Gründe, warum wir herausgefunden haben, warum sie in unserem Fall funktionierten.
Für unser fein abgestimmtes Vicuna-7B-Modell haben wir es versucht
- TGI
- vLLM
- Aphrodite
- Optimum-Nvidia
- PowerInfer
- LLAMACPP
- Ctranslate2
Wir haben die Github-Seite und ihre Kurzanleitung zum Einrichten dieser Engines durchgesehen. PowerInfer, LlaamaCPP und Ctranslate2 sind nicht sehr flexibel und unterstützen viele Optimierungstechniken wie kontinuierliches Batching, Paged Attention nicht und blieben im Vergleich zu anderen genannten Engines unterdurchschnittlich .
Um einen höheren Durchsatz zu erzielen, sollte die Inferenz-Engine/der Inferenz-Server die Speicher- und Rechenkapazitäten maximieren und sowohl Client als auch Server müssen bei der Bearbeitung von Anforderungen parallel/asynchron arbeiten, um den Server immer in Betrieb zu halten. Wie bereits erwähnt, wird es ohne die Hilfe von Optimierungstechniken wie PagedAttention, Flash Attention und Continuous Batching immer zu einer suboptimalen Leistung führen.
TGI, vLLM und Aphrodite sind in dieser Hinsicht geeignetere Kandidaten und durch die Durchführung mehrerer unten aufgeführter Experimente haben wir die optimale Konfiguration gefunden, um die maximale Leistung aus der Inferenz herauszuholen. Techniken wie Continuous Batching und Paged Attention sind standardmäßig aktiviert. Die spekulative Dekodierung muss für die folgenden Tests manuell in der Inferenz-Engine aktiviert werden.
Vergleichende Analyse von Inferenz-Engines
TGI
Um TGI zu verwenden, können wir den Abschnitt „Erste Schritte“ auf der Github-Seite durchgehen. Hier ist Docker die einfachste Möglichkeit, die TGI-Engine zu konfigurieren und zu verwenden.
Text-Generierung-Launcher-Argumente -> Hier werden verschiedene Einstellungen aufgelistet, die wir auf der Serverseite verwenden können. Einige wichtige,
- –max-input-length : Bestimmt die maximale Länge der Eingabe in das Modell. Dies erfordert in den meisten Fällen Änderungen, da der Standardwert 1024 ist.
- –max-total-tokens: max Gesamtzahl der Token, d. h. Eingabe- und Ausgabe-Token-Länge.
- –speculate, –quantiz, –max-concurrent-requests -> Standard ist nur 128, was offensichtlich weniger ist.
Um ein lokal fein abgestimmtes Modell zu starten,
docker run –gpus device=1 –shm-size 1g -p 9091:80 -v /path/to/fine_tuned_v1:/model ghcr.io/huggingface/text-generation-inference:1.4.4 –model-id /model – dtype float16 –num-shard 1 –max-input-length 3600 –max-total-tokens 4000 –specule 2
Um ein Modell vom Hub aus zu starten,
model=“lmsys/vicuna-7b-v1.5“; volume=$PWD/data; token=“<hf_token>“; docker run –gpus all –shm-size 1g -e HUGGING_FACE_HUB_TOKEN=$token -p 9091:80 -v $volume:/data ghcr.io/huggingface/text-generation-inference:1.4.4 –model-id $model – dtype float16 –num-shard 1 –max-input-length 3600 –max-total-tokens 4000 –specule 2
Für ein detaillierteres Verständnis können Sie chatGPT bitten, den obigen Befehl zu erklären. Hier starten wir den Inferenzserver am Port 9091. Und wir können einen Client einer beliebigen Sprache verwenden, um eine Anfrage an den Server zu senden. Text Generation Inference API -> erwähnt alle Endpunkte und Nutzlastparameter für die Anfrage.
Z.B
payload="<prompt hier>"
curl -XPOST „0.0.0.0:9091/generate“ -H „Content-Type: application/json“ -d „{“inputs“: $payload, „parameters“: {“max_new_tokens“: 400“,do_sample“:false „best_of“: null, „repetition_penalty“: 1, „return_full_text“: false, „seed“: null, „stop_sequences“: null, „temperature“: 0,1, „top_k“: 100, „top_p“: 0,3“, truncate“: null, „typical_p“: null, „watermark“: false, „decoder_input_details“: false}}“
Wenige Beobachtungen,
- Die Latenz steigt mit max-token-tokens, was offensichtlich ist, dass sich die Gesamtzeit erhöht, wenn wir langen Text verarbeiten.
- Spekulieren hilft, hängt aber vom Anwendungsfall und der Input-Output-Verteilung ab.
- Die Eetq-Quantisierung trägt am meisten zur Steigerung des Durchsatzes bei.
- Wenn Sie über eine Multi-GPU verfügen, führt die Ausführung einer API auf jeder GPU und die Verwendung dieser Multi-GPU-APIs hinter einem Load-Balancer zu einem höheren Durchsatz als das Sharding durch TGI selbst.
vLLM
Um einen vLLM-Server zu starten, können wir einen OpenAI-kompatiblen REST-API-Server/Docker verwenden. Der Einstieg ist ganz einfach: Folgen Sie „Bereitstellen mit Docker – vLLM“. Wenn Sie ein lokales Modell verwenden möchten, hängen Sie das Volume an und verwenden Sie den Pfad als Modellnamen.
docker run –runtime nvidia –gpus device=1 –shm-size 1g -v /path/to/fine_tuned_v1:/model -v ~/.cache/ -p 8000:8000 –ipc=host vllm/vllm-openai:latest – Modell /Modell
Oben wird ein vLLM-Server auf dem genannten 8000-Port gestartet, Sie können wie immer mit Argumenten spielen.
Stellen Sie eine Postanfrage mit:
„`Muschel
payload="<prompt hier>"
curl -XPOST -m 1200 „0.0.0.0:8000/v1/completions“ -H „Content-Type: application/json“ -d „{“prompt“: $payload“,model“:“/model“ „max_tokens „: 400“, „top_p“: 0,3, „top_k“: 100, „temperature“: 0,1}“
„`
Aphrodite
„`Muschel
Pip installiert die Aphrodite-Engine
python -m aphrodite.endpoints.openai.api_server –model PygmalionAI/pygmalion-2-7b
„`
Oder
„`
docker run -v /path/to/fine_tuned_v1:/model -d -e MODEL_NAME=“/model“ -p 2242:7860 –gpus device=1 –ipc host alpindale/aphrodite-engine
„`
Aphrodite bietet sowohl die Pip- als auch die Docker-Installation, wie im Abschnitt „Erste Schritte“ erwähnt. Docker lässt sich im Allgemeinen relativ einfacher starten und testen. Nutzungsoptionen, Serveroptionen helfen uns bei der Durchführung von Anfragen.

- Aphrodite und vLLM verwenden beide serverbasierte OpenAI-Nutzlasten, sodass Sie die Dokumentation überprüfen können.
- Wir haben Deepspeed-Mii ausprobiert, da es sich (als wir es versuchten) im Übergangszustand von der alten zur neuen Codebasis befand, sieht es nicht zuverlässig und einfach zu verwenden aus.
- Optimum-NVIDIA unterstützt keine größeren anderen Optimierungen und führt zu einer suboptimalen Leistung, siehe Link.
- Es wurde ein Kerninhalt hinzugefügt, der Code, den wir für die parallelen Ad-hoc-Anfragen verwendet haben.
Metriken und Messungen
Wir wollen ausprobieren und finden:
- Optimal Nr. von Threads für den Client/Inferenz-Engine-Server.
- Wie der Durchsatz mit zunehmender Speicherkapazität wächst
- Wie der Durchsatz in Bezug auf Tensorkerne wächst.
- Auswirkung von Threads im Vergleich zur parallelen Anforderung durch den Client.
Eine sehr einfache Möglichkeit, die Auslastung zu beobachten, besteht darin, sie über die Linux-Dienstprogramme nvidia-smi, nvtop zu beobachten. Dadurch erfahren wir den belegten Speicher, die Rechenauslastung, die Datenübertragungsrate usw.
Eine andere Möglichkeit besteht darin, den Prozess mithilfe der GPU mit nsys zu profilieren.
| S.Nr | GPU | vRAM-Speicher | Inferenz-Engine | Themen | Zeit(en) | Spekulieren |
| 1 | A6000 | 48/48 GB | TGI | 24 | 664 | – |
| 2 | A6000 | 48/48 GB | TGI | 64 | 561 | – |
| 3 | A6000 | 48/48 GB | TGI | 128 | 554 | – |
| 4 | A6000 | 48/48 GB | TGI | 256 | 568 | – |
Basierend auf den obigen Experimenten sind 128/256 Threads besser als eine niedrigere Thread-Anzahl und mehr als 256 Overhead-Starts tragen zu einem geringeren Durchsatz bei. Es wurde festgestellt, dass dies abhängig von CPU und GPU ist und ein eigenes Experiment erfordert. | ||||||
| 5 | A6000 | 48/48 GB | TGI | 128 | 596 | 2 |
| 6 | A6000 | 48/48 GB | TGI | 128 | 945 | 8 |
Ein höherer Spekulationswert führt zu mehr Ablehnungen für unser fein abgestimmtes Modell und verringert somit den Durchsatz. 1/2, da spekulierender Wert in Ordnung ist, dies unterliegt dem Modell und es kann nicht garantiert werden, dass es in allen Anwendungsfällen gleich funktioniert. Die Schlussfolgerung ist jedoch, dass die spekulative Dekodierung den Durchsatz verbessert. | ||||||
| 7 | 3090 | 24/24 GB | TGI | 128 | 741 | 2 |
| 7 | 4090 | 24/24 GB | TGI | 128 | 481 | 2 |
Obwohl der 4090 im Vergleich zum A6000 über weniger vRAM verfügt, übertrifft er ihn aufgrund der höheren Anzahl von Tensorkernen und der Geschwindigkeit der Speicherbandbreite. | ||||||
| 8 | A6000 | 24/48 GB | TGI | 128 | 707 | 2 |
| 9 | A6000 | 2 x 24/48 GB | TGI | 128 | 1205 | 2 |
Einrichten und Konfigurieren von TGI für hohen Durchsatz
Richten Sie asynchrone Anfragen in einer Skriptsprache Ihrer Wahl wie Python/Ruby ein und verwenden Sie dieselbe Datei für die Konfiguration, die wir gefunden haben:
- Die benötigte Zeit erhöht sich im Verhältnis zur maximalen Ausgabelänge der Sequenzgenerierung.
- 128/256 Threads auf Client und Server sind besser als 24, 64, 512. Bei der Verwendung niedrigerer Threads wird die Rechenleistung nicht ausreichend ausgelastet und jenseits eines Schwellenwerts wie 128 wird der Overhead höher und somit hat sich der Durchsatz verringert.
- Beim Übergang von asynchronen zu parallelen Anforderungen mit „GNU Parallel“ anstelle von Threading in Sprachen wie Go, Python/Ruby gibt es eine Verbesserung von 6 %.
- 4090 hat einen um 12 % höheren Durchsatz als A6000. Obwohl der 4090 im Vergleich zum A6000 über weniger vRAM verfügt, übertrifft er ihn aufgrund der höheren Anzahl von Tensorkernen und der Geschwindigkeit der Speicherbandbreite.
- Da der A6000 über 48 GB vRAM verfügt, haben wir in Experiment 8 der Tabelle versucht, Bruchteile des GPU-Speichers zu verwenden, um festzustellen, ob der zusätzliche RAM zur Verbesserung des Durchsatzes beiträgt oder nicht. Wir sehen, dass der zusätzliche RAM zur Verbesserung beiträgt, jedoch nicht linear. Auch wenn versucht wird, zwei APIs aufzuteilen, also zwei APIs auf derselben GPU zu hosten und für jede API den halben Speicher zu verwenden, verhält es sich wie zwei sequenzielle APIs, die ausgeführt werden, anstatt Anfragen parallel zu akzeptieren.
Beobachtungen und Metriken
Nachfolgend finden Sie Diagramme für einige Experimente und die Zeit, die zum Vervollständigen eines festen Eingabesatzes benötigt wird. Je kürzer die benötigte Zeit, desto besser.
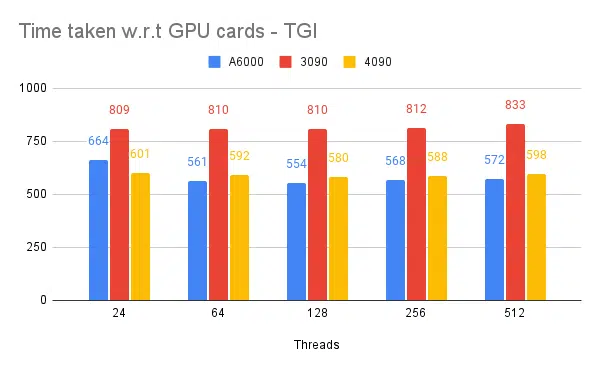
- Erwähnt werden clientseitige Threads. Die Serverseite müssen wir beim Starten der Inferenz-Engine erwähnen.
Spekulieren Sie mit Tests:

Testen mehrerer Inferenz-Engines:
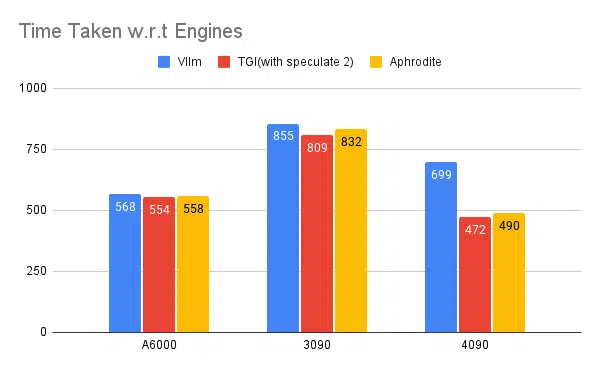
Bei ähnlichen Experimenten mit anderen Engines wie vLLM und Aphrodite beobachten wir ähnliche Ergebnisse. Zum Zeitpunkt des Schreibens dieses Artikels unterstützen vLLM und Aphrodite die spekulative Dekodierung noch nicht, sodass wir uns für TGI entscheiden müssen, da es einen höheren Durchsatz bietet als der Rest zur spekulativen Dekodierung.
Darüber hinaus können Sie GPU-Profiler konfigurieren, um die Beobachtbarkeit zu verbessern und so Bereiche mit übermäßiger Ressourcennutzung zu identifizieren und die Leistung zu optimieren. Lesen Sie weiter: Nvidia Nsight Developer Tools – Max Katz
Abschluss
Wir sehen, dass sich die Landschaft der Inferenzgenerierung ständig weiterentwickelt und die Verbesserung des Durchsatzes in LLM ein gutes Verständnis der GPU, Leistungsmetriken, Optimierungstechniken und Herausforderungen im Zusammenhang mit Textgenerierungsaufgaben erfordert. Dies hilft bei der Auswahl der richtigen Werkzeuge für den Job. Durch das Verständnis der GPU-Interna und ihrer Entsprechung zur LLM-Inferenz, wie z. B. der Nutzung von Tensorkernen und der Maximierung der Speicherbandbreite, können Entwickler die kosteneffiziente GPU auswählen und die Leistung effektiv optimieren.
Verschiedene GPU-Karten bieten unterschiedliche Fähigkeiten, und das Verständnis der Unterschiede ist entscheidend für die Auswahl der am besten geeigneten Hardware für bestimmte Aufgaben. Techniken wie Continuous Batching, Paged Attention, Kernel Fusion und Flash Attention bieten vielversprechende Lösungen zur Bewältigung auftretender Herausforderungen und zur Verbesserung der Effizienz. Basierend auf den Experimenten und Ergebnissen, die wir erhalten, scheint TGI die beste Wahl für unseren Anwendungsfall zu sein.
Lesen Sie weitere Artikel zum Thema großes Sprachmodell:
Grundlegendes zur GPU-Architektur für die LLM-Inferenzoptimierung
Fortgeschrittene Techniken zur Verbesserung des LLM-Durchsatzes