
Schritt-für-Schritt-Anleitung zum Erstellen eines Webcrawlers
Veröffentlicht: 2023-12-05Im komplizierten Geflecht des Internets, in dem Informationen über unzählige Websites verstreut sind, erweisen sich Webcrawler als heimliche Helden, die fleißig daran arbeiten, diese Fülle an Daten zu organisieren, zu indizieren und zugänglich zu machen. Dieser Artikel befasst sich zunächst mit Webcrawlern, beleuchtet deren grundlegende Funktionsweise, unterscheidet zwischen Webcrawling und Webscraping und bietet praktische Einblicke, beispielsweise eine Schritt-für-Schritt-Anleitung zum Erstellen eines einfachen Python-basierten Webcrawlers. Wenn wir tiefer eintauchen, entdecken wir die Fähigkeiten fortschrittlicher Tools wie Scrapy und entdecken, wie PromptCloud das Web-Crawling auf einen industriellen Maßstab bringt.
Was ist ein Webcrawler?
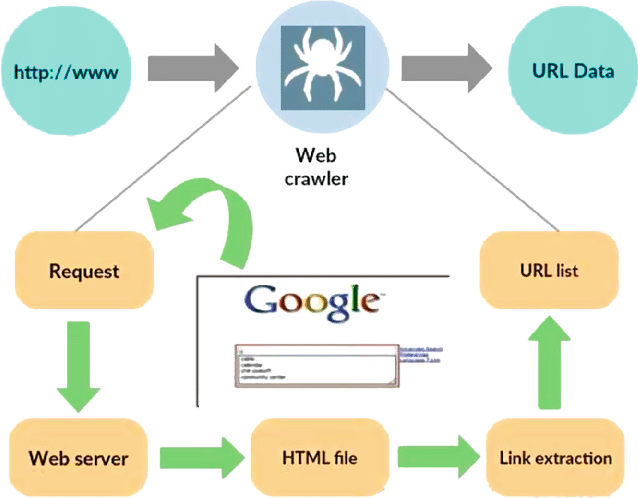
Quelle: https://www.researchgate.net/figure/Working-model-of-web-crawler_fig1_316089973
Ein Webcrawler, auch Spider oder Bot genannt, ist ein spezielles Programm, das darauf ausgelegt ist, systematisch und autonom durch die Weiten des World Wide Web zu navigieren. Seine Hauptfunktion besteht darin, Websites zu durchsuchen, Daten zu sammeln und Informationen für verschiedene Zwecke zu indizieren, beispielsweise zur Suchmaschinenoptimierung, Inhaltsindizierung oder Datenextraktion.
Im Kern ahmt ein Webcrawler die Aktionen eines menschlichen Benutzers nach, allerdings in einem viel schnelleren und effizienteren Tempo. Die Reise beginnt an einem festgelegten Startpunkt, der oft als Seed-URL bezeichnet wird, und folgt dann Hyperlinks von einer Webseite zur anderen. Dieser Prozess des Verfolgens von Links ist rekursiv und ermöglicht es dem Crawler, einen erheblichen Teil des Internets zu erkunden.
Wenn der Crawler Webseiten besucht, extrahiert und speichert er systematisch relevante Daten, darunter Text, Bilder, Metadaten und mehr. Die extrahierten Daten werden dann organisiert und indiziert, sodass Suchmaschinen bei Abfragen relevante Informationen leichter abrufen und den Benutzern präsentieren können.
Webcrawler spielen eine zentrale Rolle für die Funktionalität von Suchmaschinen wie Google, Bing und Yahoo. Durch kontinuierliches und systematisches Crawlen des Webs stellen sie sicher, dass die Suchmaschinenindizes auf dem neuesten Stand sind und den Benutzern genaue und relevante Suchergebnisse liefern. Darüber hinaus werden Webcrawler in verschiedenen anderen Anwendungen eingesetzt, darunter Inhaltsaggregation, Website-Überwachung und Data Mining.
Die Wirksamkeit eines Webcrawlers hängt von seiner Fähigkeit ab, durch verschiedene Website-Strukturen zu navigieren, dynamische Inhalte zu verarbeiten und die von Websites über die robots.txt-Datei festgelegten Regeln zu respektieren, die beschreibt, welche Teile einer Website gecrawlt werden können. Um zu verstehen, wie Webcrawler funktionieren, ist es von grundlegender Bedeutung, ihre Bedeutung für die Zugänglichkeit und Organisation des riesigen Informationsnetzes zu erkennen.
Wie Webcrawler funktionieren
Webcrawler, auch Spider oder Bots genannt, navigieren systematisch durch das World Wide Web, um Informationen von Websites zu sammeln. Hier finden Sie einen Überblick über die Funktionsweise von Webcrawlern:
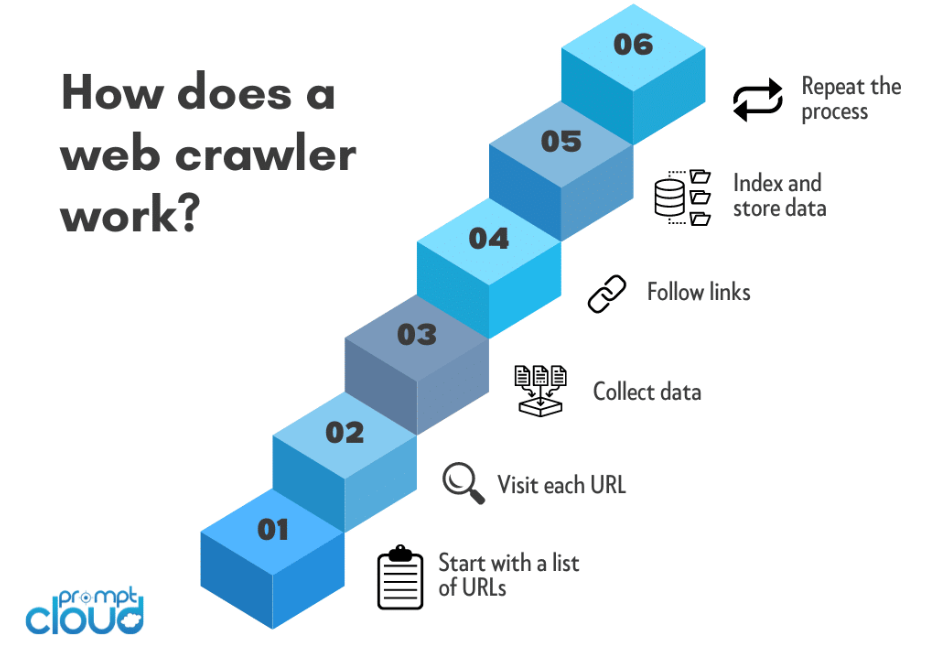
Auswahl der Seed-URL:
Der Web-Crawling-Prozess beginnt normalerweise mit einer Seed-URL. Dies ist die erste Webseite oder Website, von der aus der Crawler seine Reise beginnt.
HTTP-Anfrage:
Der Crawler sendet eine HTTP-Anfrage an die Seed-URL, um den HTML-Inhalt der Webseite abzurufen. Diese Anfrage ähnelt den Anfragen, die Webbrowser beim Zugriff auf eine Website stellen.
HTML-Analyse:
Sobald der HTML-Inhalt abgerufen wurde, analysiert der Crawler ihn, um relevante Informationen zu extrahieren. Dabei wird der HTML-Code in ein strukturiertes Format zerlegt, in dem der Crawler navigieren und analysieren kann.
URL-Extraktion:
Der Crawler identifiziert und extrahiert Hyperlinks (URLs), die im HTML-Inhalt vorhanden sind. Diese URLs stellen Links zu anderen Seiten dar, die der Crawler anschließend besucht.
Warteschlange und Planer:
Die extrahierten URLs werden einer Warteschlange oder einem Planer hinzugefügt. Die Warteschlange stellt sicher, dass der Crawler URLs in einer bestimmten Reihenfolge besucht, wobei neue oder nicht besuchte URLs häufig zuerst priorisiert werden.
Rekursion:
Der Crawler folgt den Links in der Warteschlange und wiederholt den Vorgang des Sendens von HTTP-Anfragen, des Parsens von HTML-Inhalten und des Extrahierens neuer URLs. Dieser rekursive Prozess ermöglicht es dem Crawler, durch mehrere Ebenen von Webseiten zu navigieren.
Datenextraktion:
Während der Crawler das Web durchquert, extrahiert er relevante Daten von jeder besuchten Seite. Die Art der extrahierten Daten hängt vom Zweck des Crawlers ab und kann Text, Bilder, Metadaten oder andere spezifische Inhalte umfassen.
Inhaltsindizierung:
Die gesammelten Daten werden organisiert und indiziert. Bei der Indizierung wird eine strukturierte Datenbank erstellt, die das Suchen, Abrufen und Präsentieren von Informationen erleichtert, wenn Benutzer Abfragen stellen.
Respekt vor Robots.txt:
Webcrawler halten sich in der Regel an die in der robots.txt-Datei einer Website festgelegten Regeln. Diese Datei enthält Richtlinien dazu, welche Bereiche der Website gecrawlt werden können und welche ausgeschlossen werden sollten.
Verzögerungen und Höflichkeit beim Crawlen:
Um eine Überlastung der Server und Störungen zu vermeiden, integrieren Crawler häufig Mechanismen für Crawling-Verzögerungen und Höflichkeit. Diese Maßnahmen stellen sicher, dass der Crawler respektvoll und unterbrechungsfrei mit Websites interagiert.
Webcrawler navigieren systematisch durch das Web, folgen Links, extrahieren Daten und erstellen einen organisierten Index. Dieser Prozess ermöglicht es Suchmaschinen, den Benutzern auf der Grundlage ihrer Suchanfragen genaue und relevante Ergebnisse zu liefern, was Webcrawler zu einem grundlegenden Bestandteil des modernen Internet-Ökosystems macht.

Web-Crawling vs. Web-Scraping

Quelle: https://research.aimultiple.com/web-crawling-vs-web-scraping/
Obwohl Web-Crawling und Web-Scraping oft synonym verwendet werden, dienen sie unterschiedlichen Zwecken. Beim Web-Crawling geht es darum, systematisch im Web zu navigieren, um Informationen zu indizieren und zu sammeln, während sich beim Web-Scraping das Extrahieren spezifischer Daten von Webseiten konzentriert. Im Wesentlichen geht es beim Web-Crawling um die Erkundung und Kartierung des Webs, während es beim Web-Scraping um das Sammeln gezielter Informationen geht.
Erstellen eines Webcrawlers
Das Erstellen eines einfachen Webcrawlers in Python umfasst mehrere Schritte, vom Einrichten der Entwicklungsumgebung bis zum Codieren der Crawler-Logik. Nachfolgend finden Sie eine detaillierte Anleitung, die Ihnen beim Erstellen eines einfachen Webcrawlers mit Python hilft und dabei die Requests-Bibliothek für HTTP-Anfragen und BeautifulSoup für die HTML-Analyse nutzt.
Schritt 1: Umgebung einrichten
Stellen Sie sicher, dass Python auf Ihrem System installiert ist. Sie können es von python.org herunterladen. Darüber hinaus müssen Sie die erforderlichen Bibliotheken installieren:
pip install requests beautifulsoup4
Schritt 2: Bibliotheken importieren
Erstellen Sie eine neue Python-Datei (z. B. simple_crawler.py) und importieren Sie die erforderlichen Bibliotheken:
import requests from bs4 import BeautifulSoup
Schritt 3: Definieren Sie die Crawler-Funktion
Erstellen Sie eine Funktion, die eine URL als Eingabe verwendet, eine HTTP-Anfrage sendet und relevante Informationen aus dem HTML-Inhalt extrahiert:
def simple_crawler(url):
# Send HTTP request to the URL
response = requests.get(url)
# Check if the request was successful (status code 200)
if response.status_code == 200:
# Parse HTML content with BeautifulSoup
soup = BeautifulSoup(response.text, 'html.parser')
# Extract and print relevant information (modify as needed)
title = soup.title.text
print(f'Title: {title}')
# Additional data extraction and processing can be added here
else:
print(f'Error: Failed to fetch {url}')
Schritt 4: Testen Sie den Crawler
Geben Sie eine Beispiel-URL an und rufen Sie die Funktion simple_crawler auf, um den Crawler zu testen:
if __name__ == "__main__": sample_url = 'https://example.com' simple_crawler(sample_url)
Schritt 5: Führen Sie den Crawler aus
Führen Sie das Python-Skript in Ihrem Terminal oder Ihrer Eingabeaufforderung aus:
python simple_crawler.py
Der Crawler ruft den HTML-Inhalt der bereitgestellten URL ab, analysiert ihn und gibt den Titel aus. Sie können den Crawler erweitern, indem Sie weitere Funktionen zum Extrahieren verschiedener Datentypen hinzufügen.
Web-Crawling mit Scrapy
Web-Crawling mit Scrapy öffnet die Tür zu einem leistungsstarken und flexiblen Framework, das speziell für effizientes und skalierbares Web-Scraping entwickelt wurde. Scrapy vereinfacht die Komplexität der Erstellung von Webcrawlern und bietet eine strukturierte Umgebung zum Erstellen von Spidern, die auf Websites navigieren, Daten extrahieren und systematisch speichern können. Hier ist ein genauerer Blick auf das Webcrawlen mit Scrapy:
Installation:
Bevor Sie beginnen, stellen Sie sicher, dass Scrapy installiert ist. Sie können es installieren mit:
pip install scrapy
Erstellen eines Scrapy-Projekts:
Starten Sie ein Scrapy-Projekt:
Öffnen Sie ein Terminal und navigieren Sie zu dem Verzeichnis, in dem Sie Ihr Scrapy-Projekt erstellen möchten. Führen Sie den folgenden Befehl aus:
scrapy startproject your_project_name
Dadurch entsteht eine grundlegende Projektstruktur mit den notwendigen Dateien.
Definieren Sie die Spinne:
Navigieren Sie im Projektverzeichnis zum Spiders-Ordner und erstellen Sie eine Python-Datei für Ihren Spider. Definieren Sie eine Spider-Klasse, indem Sie scrapy.Spider in eine Unterklasse umwandeln und wichtige Details wie Name, zulässige Domänen und Start-URLs bereitstellen.
import scrapy
class YourSpider(scrapy.Spider):
name = 'your_spider'
allowed_domains = ['example.com']
start_urls = ['http://example.com']
def parse(self, response):
# Define parsing logic here
pass
Daten extrahieren:
Verwenden von Selektoren:
Scrapy nutzt leistungsstarke Selektoren zum Extrahieren von Daten aus HTML. Sie können Selektoren in der Parse-Methode des Spiders definieren, um bestimmte Elemente zu erfassen.
def parse(self, response):
title = response.css('title::text').get()
yield {'title': title}
In diesem Beispiel wird der Textinhalt des <title>-Tags extrahiert.
Folgende Links:
Scrapy vereinfacht das Verfolgen von Links. Verwenden Sie die folgende Methode, um zu anderen Seiten zu navigieren.
def parse(self, response):
for next_page in response.css('a::attr(href)').getall():
yield response.follow(next_page, self.parse)
Die Spinne laufen lassen:
Führen Sie Ihren Spider mit dem folgenden Befehl aus dem Projektverzeichnis aus:
scrapy crawl your_spider
Scrapy initiiert den Spider, folgt Links und führt die in der Parse-Methode definierte Parsing-Logik aus.
Web-Crawling mit Scrapy bietet ein robustes und erweiterbares Framework für die Bewältigung komplexer Scraping-Aufgaben. Seine modulare Architektur und die integrierten Funktionen machen es zur bevorzugten Wahl für Entwickler, die anspruchsvolle Web-Datenextraktionsprojekte durchführen.
Web-Crawling im großen Maßstab
Web-Crawling in großem Maßstab stellt einzigartige Herausforderungen dar, insbesondere wenn es um die Verarbeitung großer Datenmengen geht, die über zahlreiche Websites verteilt sind. PromptCloud ist eine spezialisierte Plattform, die den Web-Crawling-Prozess in großem Maßstab rationalisieren und optimieren soll. So kann PromptCloud Sie bei der Bewältigung groß angelegter Web-Crawling-Initiativen unterstützen:
- Skalierbarkeit
- Datenextraktion und -anreicherung
- Datenqualität und Genauigkeit
- Infrastrukturmanagement
- Benutzerfreundlichkeit
- Compliance und Ethik
- Überwachung und Berichterstattung in Echtzeit
- Support und Wartung
PromptCloud ist eine robuste Lösung für Organisationen und Einzelpersonen, die Web-Crawling in großem Maßstab durchführen möchten. Durch die Bewältigung der wichtigsten Herausforderungen im Zusammenhang mit der Datenextraktion in großem Maßstab verbessert die Plattform die Effizienz, Zuverlässigkeit und Verwaltbarkeit von Web-Crawling-Initiativen.
In Summe
Webcrawler gelten als unbesungene Helden in der riesigen digitalen Landschaft und navigieren fleißig durch das Web, um Informationen zu indizieren, zu sammeln und zu organisieren. Da der Umfang von Webcrawling-Projekten zunimmt, kommt PromptCloud als Lösung ins Spiel und bietet Skalierbarkeit, Datenanreicherung und ethische Compliance, um groß angelegte Initiativen zu rationalisieren. Kontaktieren Sie uns unter sales@promptcloud.com