
Die Rolle von Web Scraping bei der Verbesserung der Genauigkeit von KI-Modellen
Veröffentlicht: 2023-12-27Die KI entwickelt sich ständig weiter, angetrieben durch die immensen Datenmengen, die zur Verfeinerung des maschinellen Lernens erforderlich sind. Dieser Lernprozess beinhaltet das Erkennen von Mustern und das Treffen fundierter Entscheidungen.
Dann kommt Web Scraping ins Spiel – ein wichtiger Akteur bei der Suche nach Daten. Dabei geht es darum, umfangreiche Informationen aus Websites zu extrahieren, eine Fundgrube für das Training von KI-Modellen. Die Harmonie zwischen KI und Web Scraping unterstreicht die datengesteuerte Essenz des modernen maschinellen Lernens. Mit fortschreitender KI steigt der Bedarf an vielfältigen Datensätzen, sodass Web Scraping zu einem unverzichtbaren Vorteil für Entwickler wird, die schärfere und effizientere KI-Systeme entwickeln.
Die Entwicklung des Web Scraping: Vom manuellen zum KI-gestützten
Die Entwicklung des Web Scraping spiegelt den technologischen Fortschritt wider. Frühe Methoden waren einfach und erforderten eine manuelle Datenextraktion – eine oft zeitaufwändige und fehleranfällige Aufgabe. Da das Internet rasant expandierte, konnten diese Techniken mit der steigenden Datenmenge nicht mehr Schritt halten. Skripte und Bots wurden eingeführt, um das Scraping zu automatisieren, es mangelte ihnen jedoch an Raffinesse.
Betreten Sie die Web-Scraping-KI und revolutionieren Sie die Datenerfassung. Maschinelles Lernen ermöglicht nun das Parsen komplexer, unstrukturierter Daten und deren effiziente Sinngewinnung. Dieser Wandel beschleunigt nicht nur die Datenerfassung, sondern verbessert auch die Qualität der extrahierten Daten, was anspruchsvollere Anwendungen ermöglicht und eine reichhaltigere Grundlage für KI-Modelle bietet, die kontinuierlich aus riesigen, differenzierten Datensätzen lernen.
Bildquelle: https://www.scrapingdog.com/
KI-Technologien beim Web Scraping verstehen
Dank künstlicher Intelligenz sind Web-Scraping-Tools leistungsfähiger geworden. KI automatisiert die Mustererkennung bei der Datenextraktion und ermöglicht so eine schnellere und genauere Identifizierung relevanter Informationen. KI-gesteuerte Web-Scraper können:
- Passen Sie sich mithilfe von maschinellem Lernen an unterschiedliche Website-Layouts an und reduzieren Sie so den Bedarf an manueller Vorlagengestaltung.
- Nutzen Sie die Verarbeitung natürlicher Sprache (NLP), um textbasierte Daten zu verstehen und zu kategorisieren und so die Qualität der erfassten Daten zu verbessern.
- Nutzen Sie Bilderkennungsfunktionen, um visuelle Inhalte zu extrahieren, die in bestimmten Datenanalysekontexten von entscheidender Bedeutung sein können.
- Implementieren Sie Algorithmen zur Anomalieerkennung, um Ausreißer oder Datenextraktionsfehler zu identifizieren und zu verwalten und so die Datenintegrität sicherzustellen.
Mit der Leistungsfähigkeit der KI wird Web Scraping stärker und anpassungsfähiger und erfüllt die umfangreichen Datenanforderungen der heutigen fortschrittlichen KI-Modelle.
Die Rolle des maschinellen Lernens bei der intelligenten Datenextraktion
Maschinelles Lernen revolutioniert die Datenextraktion, indem es Systemen ermöglicht, relevante Informationen selbstständig zu erkennen, zu verstehen und zu extrahieren. Zu den wichtigsten Beiträgen gehören:
- Mustererkennung : Algorithmen für maschinelles Lernen zeichnen sich durch die Erkennung von Mustern und Anomalien in großen Datensätzen aus und eignen sich daher ideal für die Identifizierung relevanter Datenpunkte beim Web-Scraping.
- Verarbeitung natürlicher Sprache (NLP) : Mithilfe von NLP kann maschinelles Lernen menschliche Sprache verstehen und interpretieren und so die Extraktion von Informationen aus unstrukturierten Datenquellen wie sozialen Medien erleichtern.
- Adaptives Lernen : Wenn Modelle für maschinelles Lernen mit mehr Daten konfrontiert werden, lernen sie und verbessern ihre Genauigkeit, wodurch sichergestellt wird, dass der Datenextraktionsprozess mit der Zeit effizienter wird.
- Reduzierung menschlicher Fehler : Durch maschinelles Lernen wird die Wahrscheinlichkeit von Fehlern im Zusammenhang mit der manuellen Datenextraktion erheblich reduziert, wodurch die Qualität des Datensatzes für KI-Modelle verbessert wird.
Bildquelle: https://research.aimultiple.com/
KI-gesteuerte Mustererkennung für effizientes Scraping
Web Scraping spielt eine entscheidende Rolle bei der Deckung des steigenden Datenbedarfs in Modellen des maschinellen Lernens. Im Vordergrund steht dabei die KI-gesteuerte Mustererkennung, die die Datenextraktion mit bemerkenswerter Effizienz rationalisiert. Diese fortschrittliche Technik identifiziert und kategorisiert große Datenmengen mit minimalem menschlichen Eingriff.
Mithilfe komplexer Algorithmen navigiert die Web-Scraping-KI schnell durch Webseiten, erkennt Muster und extrahiert strukturierte Datensätze. Diese automatisierten Systeme arbeiten nicht nur schneller, sondern erhöhen auch die Genauigkeit erheblich und minimieren Fehler im Vergleich zu manuellen Schabemethoden. Während sich die KI weiterentwickelt, wird ihre Fähigkeit, komplizierte Muster zu erkennen, die Landschaft des Web Scraping und der Datenerfassung weiterhin neu gestalten.
Verarbeitung natürlicher Sprache zur Inhaltsaggregation
Die entscheidende Funktion der Verarbeitung natürlicher Sprache (NLP) rückt bei der Inhaltsaggregation in den Vordergrund und ermöglicht es KI-Systemen, Daten effizient zu verstehen, zu interpretieren und zu organisieren. Es stattet Scraper mit der Fähigkeit aus, relevante Informationen aus irrelevantem Geschwätz zu unterscheiden. Durch die Analyse der Textsemantik und -syntaktik klassifiziert NLP Inhalte, extrahiert Schlüsselentitäten und fasst Informationen zusammen.

Diese destillierten Daten werden zum grundlegenden Schulungsmaterial für Modelle, die lernen, Muster zu erkennen, Benutzeranfragen zu antizipieren und aufschlussreiche Antworten zu geben. Daher ist die NLP-gestützte Inhaltsaggregation von entscheidender Bedeutung für die Entwicklung intelligenterer, kontextbewusster KI-Modelle. Es erleichtert einen zielgerichteten Ansatz bei der Datenerfassung und verfeinert die Rohdaten, die den unstillbaren Datenhunger der modernen KI stillen.
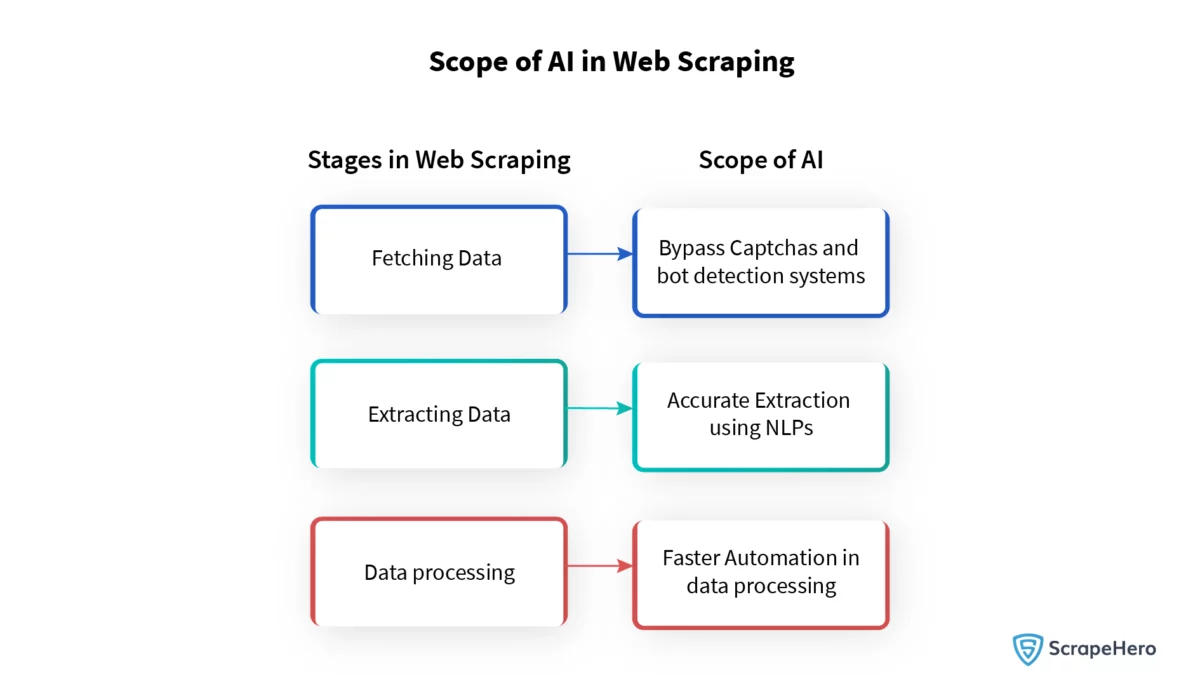
Bewältigung von Captchas und Herausforderungen bei dynamischen Inhalten mit KI
Captchas und dynamische Inhalte stellen erhebliche Hindernisse für effektives Web Scraping dar. Diese Mechanismen dienen dazu, zwischen menschlichen Benutzern und automatisierten Diensten zu unterscheiden, was häufig die Datenerfassungsbemühungen stört. Fortschritte in der künstlichen Intelligenz haben jedoch ausgefeilte Lösungen hervorgebracht:
- Algorithmen für maschinelles Lernen haben sich bei der Interpretation visueller Captchas erheblich verbessert und ahmen die Fähigkeiten des Menschen zur Mustererkennung nach.
- KI-gesteuerte Tools können sich jetzt an dynamische Inhalte anpassen, indem sie Seitenstrukturen lernen und Änderungen an der Datenposition vorhersagen.
- Einige Systeme nutzen Generative Adversarial Networks (GANs), um Modelle zu trainieren, die komplexe Captchas lösen können.
- Techniken der Verarbeitung natürlicher Sprache (Natural Language Processing, NLP) helfen beim Verständnis der Semantik hinter dynamisch generierten Texten und ermöglichen eine genaue Datenextraktion.
Während sich der anhaltende Kampf zwischen Captcha-Erstellern und KI-Entwicklern entfaltet, wird jeder Fortschritt in der Captcha-Technologie durch eine klügere und geschicktere KI-gesteuerte Gegenmaßnahme konterkariert. Dieses dynamische Zusammenspiel sorgt für einen nahtlosen Datenfluss und treibt die unaufhaltsame Expansion der KI-Branche voran.
Verbesserung der Datenqualität und -genauigkeit durch die Leistungsfähigkeit von KI-Anwendungen
Anwendungen der künstlichen Intelligenz (KI) verbessern die Datenqualität und -genauigkeit erheblich, was für das Training effektiver Modelle von entscheidender Bedeutung ist. Durch den Einsatz ausgefeilter Algorithmen kann KI:
- Erkennen und beheben Sie Inkonsistenzen in großen Datensätzen.
- Filtern Sie irrelevante Informationen heraus und konzentrieren Sie sich auf Datenteilmengen, die für das Modellverständnis wichtig sind.
- Validieren Sie Daten anhand vorab festgelegter Qualitätsmaßstäbe.
- Führen Sie eine Datenbereinigung in Echtzeit durch, um sicherzustellen, dass die Trainingsdatensätze aktuell und korrekt bleiben.
- Nutzen Sie unüberwachtes Lernen, um Muster oder Anomalien zu identifizieren, die der menschlichen Kontrolle entgehen könnten.
Der Einsatz von KI bei der Datenaufbereitung macht den Prozess nicht nur reibungsloser; Es erhöht die Qualität der aus den Daten gewonnenen Erkenntnisse und führt zu intelligenteren und zuverlässigeren KI-Modellen.
Skalierung von Web-Scraping-Vorgängen mit KI-Integration
Die Integration von KI in Web-Scraping-Praktiken verbessert die Effizienz und Skalierbarkeit von Datenerfassungsprozessen erheblich. KI-gestützte Systeme können sich an unterschiedliche Website-Layouts anpassen und Daten genau extrahieren, selbst wenn die Website Änderungen erfährt. Diese Anpassungsfähigkeit beruht auf maschinellen Lernalgorithmen, die während des Scraping-Prozesses aus Mustern und Anomalien lernen.
Darüber hinaus kann KI Datenpunkte priorisieren und kategorisieren und so wertvolle Informationen schnell erkennen. Mithilfe von NLP-Fähigkeiten (Natural Language Processing) können Scraping-Tools menschliche Sprache verstehen und verarbeiten und so Stimmungen oder Absichten aus Textdaten extrahieren. Da Scraping-Aufträge immer komplexer und umfangreicher werden, stellt die KI-Integration sicher, dass diese Aufgaben mit weniger manueller Aufsicht ausgeführt werden, was zu einem effizienteren und kostengünstigeren Betrieb führt. Die Implementierung solcher intelligenten Systeme erleichtert:
- Automatisierung der Identifizierung und Extraktion relevanter Daten
- Kontinuierliches Lernen und Anpassen an neue Webstrukturen
- Parsen und Interpretieren unstrukturierter Daten mit NLP-Techniken
- Verbesserung der Genauigkeit und Reduzierung der Notwendigkeit menschlicher Eingriffe
Kommende Trends: Die zukünftige Landschaft der Web-Scraping-KI
Während wir uns im sich ständig weiterentwickelnden Bereich der künstlichen Intelligenz bewegen, rücken die bemerkenswerten Fortschritte in der Web-Scraping-KI in den Mittelpunkt. Entdecken Sie diese entscheidenden Trends, die die Zukunft prägen:
- Umfassendes Verständnis: KI erweitert sich, um Videos, Bilder und Audio kontextbezogen zu verstehen.
- Adaptives Lernen: KI passt Scraping-Strategien basierend auf Website-Strukturen an und reduziert so menschliche Eingriffe.
- Präzise Datenextraktion: Algorithmen sind für eine genaue und relevante Datenextraktion fein abgestimmt.
- Nahtlose Integration: KI-gestützte Scraping-Tools lassen sich nahtlos in Datenanalyseplattformen integrieren.
- Ethische Datenerfassung: KI beinhaltet ethische Richtlinien für Benutzereinwilligung und Datenschutz.
Bildquelle: https://www.scrapehero.com/
Erleben Sie die Synergie von Web Scraping und KI für Ihre Datenanforderungen. Kontaktieren Sie PromptCloud unter sales@promptcloud.com für hochmoderne Web-Scraping-Dienste, die die Genauigkeit Ihrer KI-Modelle erhöhen.
FAQs:
Kann KI Web Scraping durchführen?
Sicherlich ist KI geschickt darin, Web-Scraping-Aufgaben zu bewältigen. Ausgestattet mit fortschrittlichen Algorithmen können KI-Systeme unabhängig voneinander Websites durchsuchen, Muster erkennen und relevante Daten mit bemerkenswerter Effizienz extrahieren. Diese Fähigkeit stellt einen bedeutenden Fortschritt dar und erhöht die Schnelligkeit, Präzision und Flexibilität von Datenextraktionsverfahren.
Ist Web Scraping illegal?
Wenn es um die Legalität von Web Scraping geht, ist die Situation differenziert. Web Scraping an sich ist nicht grundsätzlich illegal, aber die Rechtmäßigkeit hängt davon ab, wie es durchgeführt wird. Verantwortungsvolles und ethisches Scraping im Einklang mit den Nutzungsbedingungen der Zielwebsites ist von entscheidender Bedeutung, um rechtliche Komplikationen zu vermeiden. Es ist wichtig, das Web Scraping mit einer achtsamen und konformen Denkweise anzugehen.
Kann ChatGPT Web Scraping durchführen?
ChatGPT beteiligt sich nicht an Web-Scraping-Aktivitäten. Seine Stärke liegt im Verständnis und der Generierung natürlicher Sprache und der Bereitstellung von Antworten auf der Grundlage der empfangenen Eingaben. Für eigentliche Web-Scraping-Aufgaben sind spezielle Tools und Programmierungen erforderlich.
Wie viel kostet Scraper AI?
Bei der Betrachtung der Kosten für Scraper-KI-Dienste ist es wichtig, Variablen wie die Komplexität der Scraping-Aufgabe, das zu extrahierende Datenvolumen und spezifische Anpassungsanforderungen zu berücksichtigen. Preismodelle können einmalige Gebühren, Abonnements oder nutzungsabhängige Gebühren umfassen. Für ein individuelles, auf Ihre Anforderungen zugeschnittenes Angebot ist es ratsam, sich an einen Web-Scraping-Dienstleister wie PromptCloud zu wenden.