
Der ultimative Leitfaden zum Erstellen von Web Scrapern zu wettbewerbsfähigen Preisen
Veröffentlicht: 2024-04-05Wettbewerbsfähige Preisgestaltung, die Praxis der Auswahl strategischer Preispunkte, um den Markt eines Produkts oder einer Dienstleistung im Vergleich zur Konkurrenz bestmöglich zu nutzen, ist zu einem unverzichtbaren Instrument für Unternehmen geworden, die Kunden gewinnen und binden möchten. Im digitalen Zeitalter, in dem Preisvergleiche nur einen Klick entfernt sind, hat die Bedeutung einer wettbewerbsfähigen Preisgestaltung zugenommen. Es beeinflusst nicht nur die Kaufentscheidungen der Verbraucher, sondern wirkt sich auch direkt auf den Marktanteil und die Rentabilität eines Unternehmens aus.
Betreten Sie die Welt des Web Scrapers, einem leistungsstarken Tool, das den Prozess der Datenextraktion von Websites automatisiert. Im Zusammenhang mit wettbewerbsorientierten Preisen wird Web Scraping eingesetzt, um Preisinformationen von den Websites der Wettbewerber zu sammeln, sodass Unternehmen ihre Marktposition analysieren und ihre Preisstrategien entsprechend anpassen können. Diese Technik bietet einen umfassenden Echtzeitüberblick über die Wettbewerbslandschaft, der für fundierte Preisentscheidungen von entscheidender Bedeutung ist. Durch den Einsatz von Web Scraper können Unternehmen sicherstellen, dass ihre Preisstrategien datengesteuert, dynamisch und an Markttrends ausgerichtet sind.
Bevor wir uns mit den Feinheiten der Entwicklung von Web Scrapern für wettbewerbsfähige Preisstrategien befassen, ist es wichtig, ein solides Verständnis davon zu entwickeln, was Web Scraping beinhaltet und welche Grundprinzipien dahinter stecken.
Was ist Web Scraping?
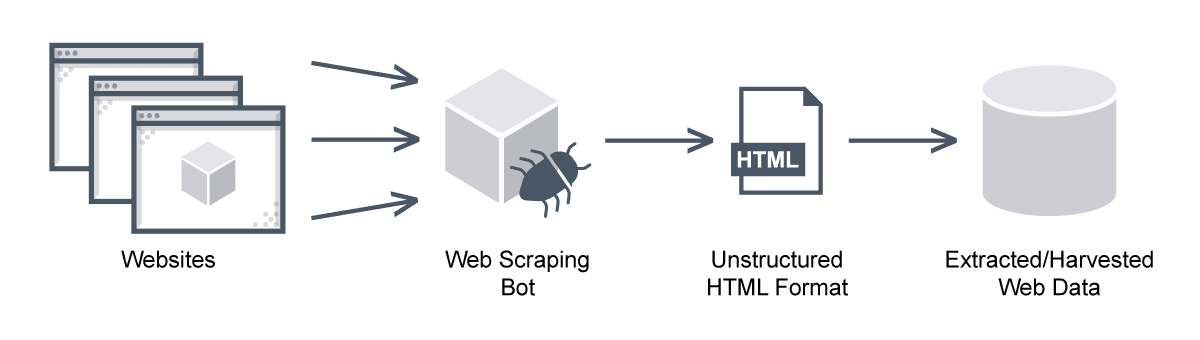
Quelle: https://avinetworks.com/glossary/web-scraping/
Web Scraping ist eine Technik, mit der große Datenmengen automatisch von Websites extrahiert werden. Der Prozess umfasst das Senden von Anfragen an Webseiten, das Herunterladen der Webseiten und das anschließende Parsen des HTML-Codes, um die benötigten Daten zu extrahieren. Diese Technik eignet sich besonders zum Sammeln von Daten von Websites, die keine API oder andere Möglichkeiten für den programmgesteuerten Zugriff auf ihre Daten bieten.
Einrichten Ihrer Web Scraping-Umgebung
Um das volle Potenzial von Web Scraper zu wettbewerbsfähigen Preisen auszuschöpfen, ist es entscheidend, eine robuste und flexible Entwicklungsumgebung einzurichten. Dazu gehört die Auswahl geeigneter Tools und Programmiersprachen.
Auswahl der richtigen Tools und Programmiersprachen

Quelle: https://fastercapital.com/startup-topic/web-scraping.html
- Python : Bekannt für seine Einfachheit und Lesbarkeit, ist Python aufgrund seines umfangreichen Ökosystems an Bibliotheken, die für die Datenextraktion und -bearbeitung konzipiert sind, ein Favorit unter Web-Scrapern. Seine Vielseitigkeit und Benutzerfreundlichkeit machen es ideal für Anfänger und Experten gleichermaßen.
- JavaScript : Für Websites, die zum dynamischen Laden von Inhalten stark auf JavaScript angewiesen sind, kann die Verwendung von JavaScript (insbesondere Node.js) zum Scraping von Vorteil sein. Bibliotheken wie Puppeteer oder Cheerio sind beliebte Optionen zum Scrapen solcher dynamischen Inhalte.
- Andere Tools : Während Python und JavaScript die am häufigsten verwendeten Sprachen für Web Scraping sind, können je nach Ihren spezifischen Anforderungen auch Tools wie R (für statistische Analysen) und Software wie Octoparse (ein Web-Scraping-Tool ohne Code) nützlich sein.
Web Scraping für Preisdaten
Web Scraper für Preisdaten ist eine entscheidende Aufgabe für Unternehmen, die auf ihrem Markt wettbewerbsfähig bleiben wollen. Dabei geht es darum, relevante Preisinformationen von Wettbewerber-Websites zu identifizieren und zu extrahieren, die für Wettbewerbsanalysen, Preisstrategien und Marktforschung verwendet werden können. Angesichts der Vielfalt der heute verwendeten Webtechnologien stellt die effiziente Extraktion dieser Daten, insbesondere von dynamischen Websites, die Inhalte über JavaScript laden, besondere Herausforderungen dar. Im Folgenden finden Sie Techniken und Strategien zum effektiven Scrapen von Preisdaten.

Techniken zum Identifizieren und Extrahieren von Preisdaten aus Webseiten
Untersuchen der Webseitenstruktur
- Verwenden Sie Browser-Entwicklertools (Inspect Element in Chrome oder Firefox), um zu untersuchen, wie Preisinformationen strukturiert und im HTML der Seite enthalten sind.
- Suchen Sie nach Mustern in der HTML- oder URL-Struktur, die Ihnen dabei helfen können, programmgesteuert durch Produktlisten oder Kategorien zu navigieren.
XPath- und CSS-Selektoren
- Nutzen Sie XPath- oder CSS-Selektoren, um auf bestimmte Elemente mit Preisdaten abzuzielen. Diese Selektoren helfen dabei, die genaue Position der Preisinformationen innerhalb der DOM-Struktur der Webseite zu bestimmen.
- Tools wie XPath Helper (Chrome) oder Try XPath (Firefox) können beim Erstellen und Testen dieser Ausdrücke hilfreich sein.
Reguläre Ausdrücke
- In einigen Fällen, insbesondere bei schlecht strukturiertem HTML, können reguläre Ausdrücke (Regex) verwendet werden, um Preisinformationen aus dem Textinhalt der Webseite zu extrahieren.
- Seien Sie bei Regex vorsichtig, da übermäßig komplexe Muster schwer zu pflegen sein können und zu ungenauem Scraping führen können, wenn sich die Struktur der Webseite ändert.
Umgang mit dynamischen Websites und über JavaScript geladenen Daten
Dynamische Websites, die Inhalte, einschließlich Preisinformationen, über JavaScript laden, stellen eine erhebliche Herausforderung für herkömmliche Web-Scraping-Techniken dar, die nur statische HTML-Inhalte analysieren.
Headless-Browser
- Tools wie Puppeteer (für Node.js) und Selenium (für mehrere Programmiersprachen, einschließlich Python) können Browser automatisieren, um mit Webseiten so zu interagieren, wie es ein Benutzer tun würde. Dazu gehört das Warten darauf, dass JavaScript die Preisdaten dynamisch lädt.
- Headless-Browser können navigieren, scrollen und sogar mit Webelementen interagieren, um sicherzustellen, dass alle relevanten Daten, einschließlich dynamisch geladener Inhalte, vor dem Scraping gerendert werden.
API-Aufrufe
- Viele dynamische Websites führen separate API-Aufrufe durch, um Preise und andere Daten abzurufen. Untersuchen Sie den Netzwerkverkehr mithilfe von Browser-Entwicklertools, um diese API-Aufrufe zu identifizieren.
- Das direkte Scraping von diesen API-Endpunkten kann effizienter und zuverlässiger sein als das Parsen von HTML-Inhalten, da APIs Daten normalerweise in einem strukturierten Format wie JSON zurückgeben.
AJAX-Anfragebearbeitung
- Für Inhalte, die über AJAX geladen werden, sind Tools erforderlich, die das Warten auf das Erscheinen von Elementen oder das Überprüfen auf Änderungen in der Struktur der Webseite unterstützen. Selenium bietet beispielsweise explizite und implizite Wartezeiten für die Verarbeitung von AJAX.
- Durch die Überwachung von AJAX-Anfragen können auch API-Endpunkte oder direkte URLs zu den Preisdaten angezeigt werden, sodass keine HTML-Analyse erforderlich ist.
Beispiele aus der Praxis für erfolgreiches Web Scraping für Preisdaten
E-Commerce-Riese Amazon:
- Strategie : Amazon nutzt Web Scraping, um die Preise der Wettbewerber in Echtzeit zu überwachen und ihnen so die Möglichkeit zu geben, ihre Preise anzupassen, um wettbewerbsfähig zu bleiben.
- Ergebnis : Diese dynamische Preisstrategie hat erheblich zur Position von Amazon als Marktführer beigetragen und die Kundenbindung durch wettbewerbsfähige Preise sichergestellt.
- Lektion : Die Bedeutung von Echtzeitdaten bei der Umsetzung dynamischer Preisstrategien.
Reiseplattform Booking.com :
- Strategie : Booking.com sammelt Preisdaten von Hotel- und Fluglinien-Websites weltweit, um seinen Nutzern die besten Angebote anzubieten.
- Ergebnis : Erhöhte Benutzerzufriedenheit und mehr Buchungen durch wettbewerbsfähige Preise.
- Lektion : Die Nutzung gesammelter Daten zur Steigerung des Benutzerwerts kann zu einem höheren Marktanteil und einer höheren Kundenbindung führen.
Einzelhandelskette Walmart :
- Strategie : Walmart nutzt Web Scraping, um nicht nur die Preise, sondern auch die Lagerverfügbarkeit von Produkten auf den Websites der Wettbewerber zu überwachen.
- Ergebnis : Verbesserte Bestandsverwaltung und Preisstrategien, die den Erwartungen ihrer Kunden entsprechen.
- Lektion : Integration von Bestandsdaten in Preisstrategien für umfassende Wettbewerbsfähigkeit auf dem Markt.
Für diejenigen, die tiefer in Web Scraping und Datenanalyse eintauchen möchten, bietet PromptCloud eine Reihe von Lösungen, die auf Ihre Geschäftsanforderungen zugeschnitten sind. Unser Fachwissen und unsere Tools können Ihnen dabei helfen, die Komplexität des Web Scraping zu bewältigen und sicherzustellen, dass Sie den größtmöglichen Nutzen aus Ihren Bemühungen ziehen.
Entdecken Sie die Lösungen von PromptCloud für Web Scraping und Datenanalyse, um Ihre wettbewerbsfähigen Preisstrategien zu transformieren und Ihr Unternehmen voranzutreiben. Lassen Sie uns gemeinsam die Macht der Daten nutzen.