
Grundlegendes zur GPU-Architektur für die LLM-Inferenzoptimierung
Veröffentlicht: 2024-04-02Einführung in LLMs und die Bedeutung der GPU-Optimierung
Im heutigen Zeitalter der Fortschritte bei der Verarbeitung natürlicher Sprache (NLP) haben sich Large Language Models (LLMs) als leistungsstarke Werkzeuge für eine Vielzahl von Aufgaben herausgestellt, von der Textgenerierung bis hin zur Beantwortung von Fragen und Zusammenfassungen. Dabei handelt es sich um mehr als einen Next-Probable-Token-Generator. Allerdings stellen die wachsende Komplexität und Größe dieser Modelle erhebliche Herausforderungen hinsichtlich der Recheneffizienz und Leistung dar.
In diesem Blog befassen wir uns mit den Feinheiten der GPU-Architektur und untersuchen, wie verschiedene Komponenten zur LLM-Inferenz beitragen. Wir besprechen wichtige Leistungsmetriken wie Speicherbandbreite und Tensorkernauslastung und erläutern die Unterschiede zwischen verschiedenen GPU-Karten, damit Sie fundierte Entscheidungen bei der Auswahl der Hardware für Ihre großen Sprachmodellaufgaben treffen können.
In einer sich schnell entwickelnden Landschaft, in der NLP-Aufgaben immer mehr Rechenressourcen erfordern, ist die Optimierung des LLM-Inferenzdurchsatzes von größter Bedeutung. Begleiten Sie uns auf dieser Reise, um das volle Potenzial von LLMs durch GPU-Optimierungstechniken auszuschöpfen, und tauchen Sie ein in verschiedene Tools, die es uns ermöglichen, die Leistung effektiv zu verbessern.
GPU-Architektur-Grundlagen für LLMs – Kennen Sie Ihre GPU-Interna
Aufgrund der Natur der hocheffizienten parallelen Berechnung werden GPUs zum Gerät der Wahl für die Ausführung aller Deep-Learning-Aufgaben. Daher ist es wichtig, den allgemeinen Überblick über die GPU-Architektur zu verstehen, um die zugrunde liegenden Engpässe zu verstehen, die während der Inferenzphase auftreten. Nvidia-Karten werden aufgrund von CUDA (Compute Unified Device Architecture) bevorzugt, einer von NVIDIA entwickelten proprietären Parallel-Computing-Plattform und API, die es Entwicklern ermöglicht, Parallelität auf Thread-Ebene in der Programmiersprache C zu spezifizieren und so direkten Zugriff auf den virtuellen Befehlssatz und die Parallelität der GPU zu ermöglichen Rechenelemente.
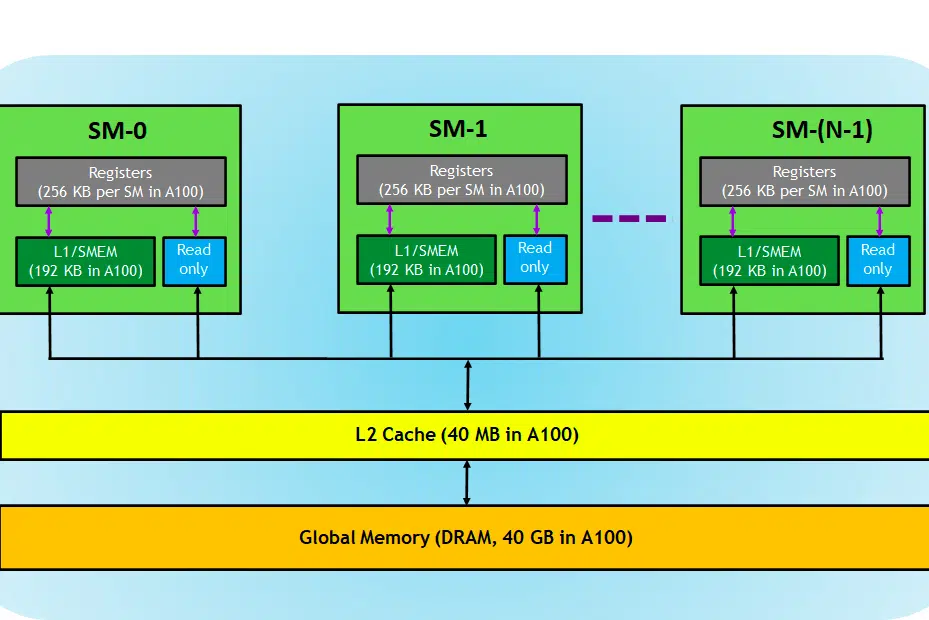
Für den Kontext haben wir zur Erklärung eine NVIDIA-Karte verwendet, da diese, wie bereits erwähnt, weithin für Deep-Learning-Aufgaben bevorzugt wird und nur wenige andere Begriffe wie Tensorkerne darauf anwendbar sind.
Werfen wir einen Blick auf die GPU-Karte. Hier im Bild können wir drei Hauptteile und (einen weiteren großen versteckten Teil) eines GPU-Geräts sehen
- SM (Streaming-Multiprozessoren)
- L2-Cache
- Speicherbandbreite
- Globaler Speicher (DRAM)
So wie Ihr CPU-RAM zusammenspielt, ist RAM der Ort für die Datenspeicherung (d. h. Speicher) und die CPU für Verarbeitungsaufgaben (d. h. Prozesse). In einer GPU speichert der globale Speicher mit hoher Bandbreite (DRAM) die Modellgewichte (z. B. LLAMA 7B), die in den Speicher geladen werden, und bei Bedarf werden diese Gewichte zur Berechnung an die Verarbeitungseinheit (z. B. den SM-Prozessor) übertragen.
Streaming-Multiprozessoren
Ein Streaming-Multiprozessor oder SM ist eine Sammlung kleinerer Ausführungseinheiten, die als CUDA-Kerne (proprietäre Parallel-Computing-Plattform von NVIDIA) bezeichnet werden, zusammen mit zusätzlichen Funktionseinheiten, die für das Abrufen, Dekodieren, Planen und Versenden von Anweisungen verantwortlich sind. Jeder SM arbeitet unabhängig und enthält eine eigene Registerdatei, einen gemeinsamen Speicher, einen L1-Cache und eine eigene Textureinheit. SMs sind hochgradig parallelisiert, sodass sie Tausende von Threads gleichzeitig verarbeiten können, was für die Erzielung eines hohen Durchsatzes bei GPU-Rechenaufgaben unerlässlich ist. Die Leistung des Prozessors wird im Allgemeinen in FLOPS gemessen, der Zahl. Anzahl schwebender Operationen kann jede Sekunde ausgeführt werden.
Deep-Learning-Aufgaben bestehen hauptsächlich aus Tensoroperationen, z. B. Matrix-Matrix-Multiplikation. NVIDIA hat Tensorkerne in GPUs der neueren Generation eingeführt, die speziell dafür entwickelt wurden, diese Tensoroperationen auf hocheffiziente Weise auszuführen. Wie bereits erwähnt, sind Tensorkerne nützlich, wenn es um Deep-Learning-Aufgaben geht. Anstelle von CUDA-Kernen müssen wir die Tensorkerne überprüfen, um festzustellen, wie effizient eine GPU das Training/die Inferenz von LLM durchführen kann.
L2-Cache
L2-Cache ist ein Speicher mit hoher Bandbreite, der von SMs gemeinsam genutzt wird, um den Speicherzugriff und die Datenübertragungseffizienz innerhalb des Systems zu optimieren. Im Vergleich zu DRAM handelt es sich um einen kleineren, schnelleren Speichertyp, der näher an den Verarbeitungseinheiten (z. B. Streaming-Multiprozessoren) liegt. Es trägt dazu bei, die Gesamteffizienz des Speicherzugriffs zu verbessern, indem es die Notwendigkeit verringert, bei jeder Speicheranforderung auf den langsameren DRAM zuzugreifen.
Speicherbandbreite
Die Leistung hängt also davon ab, wie schnell wir die Gewichte vom Speicher zum Prozessor übertragen können und wie effizient und schnell der Prozessor die gegebenen Berechnungen verarbeiten kann.
Wenn die Rechenkapazität höher/schneller als die Datenübertragungsrate zwischen Speicher und SM ist, mangelt es dem SM an Daten, die verarbeitet werden müssen, und somit wird die Rechenleistung nicht ausgelastet. Diese Situation, in der die Speicherbandbreite niedriger als die Verbrauchsrate ist, wird als speichergebundene Phase bezeichnet . Dies ist sehr wichtig zu beachten, da dies der vorherrschende Engpass im Inferenzprozess ist.
Wenn die Berechnung hingegen mehr Zeit für die Verarbeitung benötigt und mehr Daten für die Berechnung in die Warteschlange gestellt werden, handelt es sich bei diesem Zustand um eine rechengebundene Phase.
Um die Vorteile der GPU voll ausnutzen zu können, müssen wir uns in einem rechengebundenen Zustand befinden und gleichzeitig die anfallenden Berechnungen so effizient wie möglich durchführen.
DRAM-Speicher
DRAM dient als primärer Speicher in einer GPU und stellt einen großen Speicherpool zum Speichern von Daten und Anweisungen bereit, die für die Berechnung benötigt werden. Es ist normalerweise hierarchisch organisiert und verfügt über mehrere Speicherbänke und Kanäle, um einen Hochgeschwindigkeitszugriff zu ermöglichen.

Für die Inferenzaufgabe bestimmt der DRAM der GPU, wie groß ein Modell ist, das wir laden können, und die Rechen-FLOPS und die Bandbreite bestimmen den Durchsatz, den wir erzielen können.
Vergleich von GPU-Karten für LLM-Aufgaben
Informationen über die Anzahl der Tensorkerne und die Bandbreitengeschwindigkeit finden Sie im Whitepaper des GPU-Herstellers. Hier ist ein Beispiel,
| RTX A6000 | RTX 4090 | RTX 3090 | |
| Speichergröße | 48 GB | 24 GB | 24 GB |
| Speichertyp | GDDR6 | GDDR6X | |
| Bandbreite | 768,0 GB/s | 1008 GB/Sek | 936,2 GB/s |
| CUDA-Kerne / GPU | 10752 | 16384 | 10496 |
| Tensorkerne | 336 | 512 | 328 |
| L1-Cache | 128 KB (pro SM) | 128 KB (pro SM) | 128 KB (pro SM) |
| FP16 Nicht-Tensor | 38,71 TFLOPS (1:1) | 82,6 | 35,58 TFLOPS (1:1) |
| FP32 Nicht-Tensor | 38,71 TFLOPS | 82,6 | 35,58 TFLOPS |
| FP64 Nicht-Tensor | 1.210 GFLOPS (1:32) | 556,0 GFLOPS (1:64) | |
| Spitzen-FP16-Tensor-TFLOPS mit FP16-Akkumulation | 154,8/309,6 | 330,3/660,6 | 142/284 |
| Spitzen-FP16-Tensor-TFLOPS mit FP32-Akkumulation | 154,8/309,6 | 165,2/330,4 | 71/142 |
| Spitzen-BF16-Tensor-TFLOPS mit FP32 | 154,8/309,6 | 165,2/330,4 | 71/142 |
| Spitzen-TFLOPS des TF32-Tensors | 77,4/154,8 | 82,6/165,2 | 35,6/71 |
| Peak INT8 Tensor TOPS | 309,7/619,4 | 660,6/1321,2 | 284/568 |
| Peak INT4 Tensor TOPS | 619,3/1238,6 | 1321,2/2642,4 | 568/1136 |
| L2-Cache | 6 MB | 72 MB | 6 MB |
| Speicherbus | 384 Bit | 384 Bit | 384 Bit |
| TMUs | 336 | 512 | 328 |
| ROPs | 112 | 176 | 112 |
| SM-Anzahl | 84 | 128 | 82 |
| RT-Kerne | 84 | 128 | 82 |
Hier können wir sehen, dass FLOPS speziell für Tensor-Operationen erwähnt wird. Diese Daten helfen uns, die verschiedenen GPU-Karten zu vergleichen und die geeignete für unseren Anwendungsfall auszuwählen. Aus der Tabelle geht hervor, dass der A6000 zwar über den doppelten Speicher von 4090 verfügt, die Tensor-Flops und die Speicherbandbreite von 4090 jedoch zahlenmäßig besser sind und daher für die Schlussfolgerung großer Sprachmodelle leistungsfähiger sind.
Lesen Sie weiter: Nvidia CUDA in 100 Sekunden
Abschluss
Im schnell voranschreitenden NLP-Bereich ist die Optimierung großer Sprachmodelle (LLMs) für Inferenzaufgaben zu einem wichtigen Schwerpunkt geworden. Wie wir untersucht haben, spielt die Architektur von GPUs eine entscheidende Rolle bei der Erzielung hoher Leistung und Effizienz bei diesen Aufgaben. Das Verständnis der internen Komponenten von GPUs, wie Streaming-Multiprozessoren (SMs), L2-Cache, Speicherbandbreite und DRAM, ist für die Identifizierung potenzieller Engpässe in LLM-Inferenzprozessen von entscheidender Bedeutung.
Der Vergleich zwischen verschiedenen NVIDIA-GPU-Karten – RTX A6000, RTX 4090 und RTX 3090 – zeigt erhebliche Unterschiede unter anderem in Bezug auf Speichergröße, Bandbreite und Anzahl der CUDA- und Tensor-Kerne. Diese Unterscheidungen sind entscheidend für fundierte Entscheidungen darüber, welche GPU für bestimmte LLM-Aufgaben am besten geeignet ist. Während beispielsweise die RTX A6000 eine größere Speichergröße bietet, zeichnet sich die RTX 4090 in Bezug auf Tensor-FLOPS und Speicherbandbreite aus, was sie zu einer leistungsfähigeren Wahl für anspruchsvolle LLM-Inferenzaufgaben macht.
Die Optimierung der LLM-Inferenz erfordert einen ausgewogenen Ansatz, der sowohl die Rechenkapazität der GPU als auch die spezifischen Anforderungen der jeweiligen LLM-Aufgabe berücksichtigt. Bei der Auswahl der richtigen GPU müssen die Kompromisse zwischen Speicherkapazität, Verarbeitungsleistung und Bandbreite verstanden werden, um sicherzustellen, dass die GPU die Gewichtungen des Modells effizient verarbeiten und Berechnungen durchführen kann, ohne zu einem Engpass zu werden. Da sich der NLP-Bereich ständig weiterentwickelt, wird es für diejenigen, die die Grenzen dessen erweitern möchten, was mit großen Sprachmodellen möglich ist, von größter Bedeutung sein, sich über die neuesten GPU-Technologien und ihre Fähigkeiten auf dem Laufenden zu halten.
Verwendete Terminologie
- Durchsatz:
Im Falle einer Schlussfolgerung ist der Durchsatz das Maß dafür, wie viele Anfragen/Eingabeaufforderungen in einem bestimmten Zeitraum verarbeitet werden. Der Durchsatz wird normalerweise auf zwei Arten gemessen:
- Anfragen pro Sekunde (RPS) :
- RPS misst die Anzahl der Inferenzanfragen, die ein Modell innerhalb einer Sekunde verarbeiten kann. Bei einer Inferenzanfrage wird typischerweise eine Antwort oder Vorhersage basierend auf Eingabedaten generiert.
- Für die LLM-Generierung gibt RPS an, wie schnell das Modell auf eingehende Eingabeaufforderungen oder Abfragen reagieren kann. Höhere RPS-Werte deuten auf eine bessere Reaktionsfähigkeit und Skalierbarkeit für Echtzeit- oder nahezu Echtzeitanwendungen hin.
- Um hohe RPS-Werte zu erreichen, sind häufig effiziente Bereitstellungsstrategien erforderlich, z. B. das Zusammenfassen mehrerer Anforderungen, um den Overhead zu amortisieren und die Nutzung der Rechenressourcen zu maximieren.
- Tokens pro Sekunde (TPS) :
- TPS misst die Geschwindigkeit, mit der ein Modell während der Textgenerierung Token (Wörter oder Unterwörter) verarbeiten und generieren kann.
- Im Kontext der LLM-Generierung spiegelt TPS den Durchsatz des Modells in Bezug auf die Textgenerierung wider. Es gibt an, wie schnell das Modell kohärente und aussagekräftige Antworten liefern kann.
- Höhere TPS-Werte bedeuten eine schnellere Textgenerierung, wodurch das Modell mehr Eingabedaten verarbeiten und in einer bestimmten Zeitspanne längere Antworten generieren kann.
- Um hohe TPS-Werte zu erreichen, müssen häufig die Modellarchitektur optimiert, Berechnungen parallelisiert und Hardwarebeschleuniger wie GPUs genutzt werden, um die Token-Generierung zu beschleunigen.
- Latenz:
Latenz bezieht sich in LLMs auf die Zeitverzögerung zwischen Eingabe und Ausgabe während der Inferenz. Die Minimierung der Latenz ist für die Verbesserung des Benutzererlebnisses und die Ermöglichung von Echtzeitinteraktionen in Anwendungen, die LLMs nutzen, von entscheidender Bedeutung. Es ist wichtig, ein Gleichgewicht zwischen Durchsatz und Latenz zu finden, basierend auf dem Dienst, den wir bereitstellen müssen. Eine geringe Latenz ist für Fälle wie Echtzeit-Interaktion mit Chatbots/Copiloten wünschenswert, für Fälle der Massendatenverarbeitung wie die interne Datenwiederverarbeitung jedoch nicht erforderlich.
Lesen Sie hier mehr über fortgeschrittene Techniken zur Verbesserung des LLM-Durchsatzes.