
Das Potenzial der KI beim Website-Scraping erschließen: Ein Überblick
Veröffentlicht: 2024-02-02Web Scraping hat sich heute von einer Nischenprogrammierungsaktivität zu einem unverzichtbaren Geschäftstool entwickelt. Ursprünglich war Scraping ein manueller Prozess, bei dem Einzelpersonen Daten von Webseiten kopierten. Die Weiterentwicklung der Technologie führte zu automatisierten Skripten, die Daten effizienter, wenn auch grober, extrahieren konnten.
Mit der Weiterentwicklung von Websites entwickelten sich auch die Scraping-Techniken weiter, passten sich an komplizierte Strukturen an und widersetzten sich den Anti-Scraping-Maßnahmen. Der Fortschritt bei KI und maschinellem Lernen hat das Web Scraping in unbekannte Gebiete getrieben und ein kontextbezogenes Verständnis und anpassungsfähige Ansätze ermöglicht, die das Surfverhalten von Menschen nachahmen. Dieser kontinuierliche Fortschritt prägt die Art und Weise, wie Unternehmen Webdaten in großem Maßstab und mit beispielloser Komplexität nutzen.
Die Entstehung von KI beim Web Scraping

Bildquelle: https://www.scrapehero.com/
Der Einfluss künstlicher Intelligenz (KI) auf Web Scraping kann nicht genug betont werden; Es hat die Landschaft völlig verändert und den Prozess effizienter gemacht. Vorbei sind die Zeiten mühsamer manueller Konfigurationen und ständiger Wachsamkeit bei der Anpassung an sich ändernde Website-Strukturen.
Dank der KI haben sich Web Scraper nun zu intuitiven Werkzeugen entwickelt, die aus Mustern lernen und sich ohne ständige menschliche Aufsicht autonom an strukturelle Veränderungen anpassen können. Das bedeutet, dass sie den Kontext von Daten erfassen, das Relevante mit bemerkenswerter Genauigkeit erkennen und das Unwesentliche zurücklassen können.
Diese intelligentere und flexiblere Methode hat den Prozess der Datenextraktion verändert und der Industrie die Werkzeuge an die Hand gegeben, mit denen sie fundiertere Entscheidungen auf der Grundlage erstklassiger Datenqualität treffen können. Da die KI-Technologie voranschreitet, wird ihre Integration in Web-Scraping-Tools neue Standards etablieren und den Kern der Art und Weise, wie wir Informationen aus dem Web sammeln, grundlegend verändern.
Ethische und rechtliche Überlegungen beim modernen Web Scraping
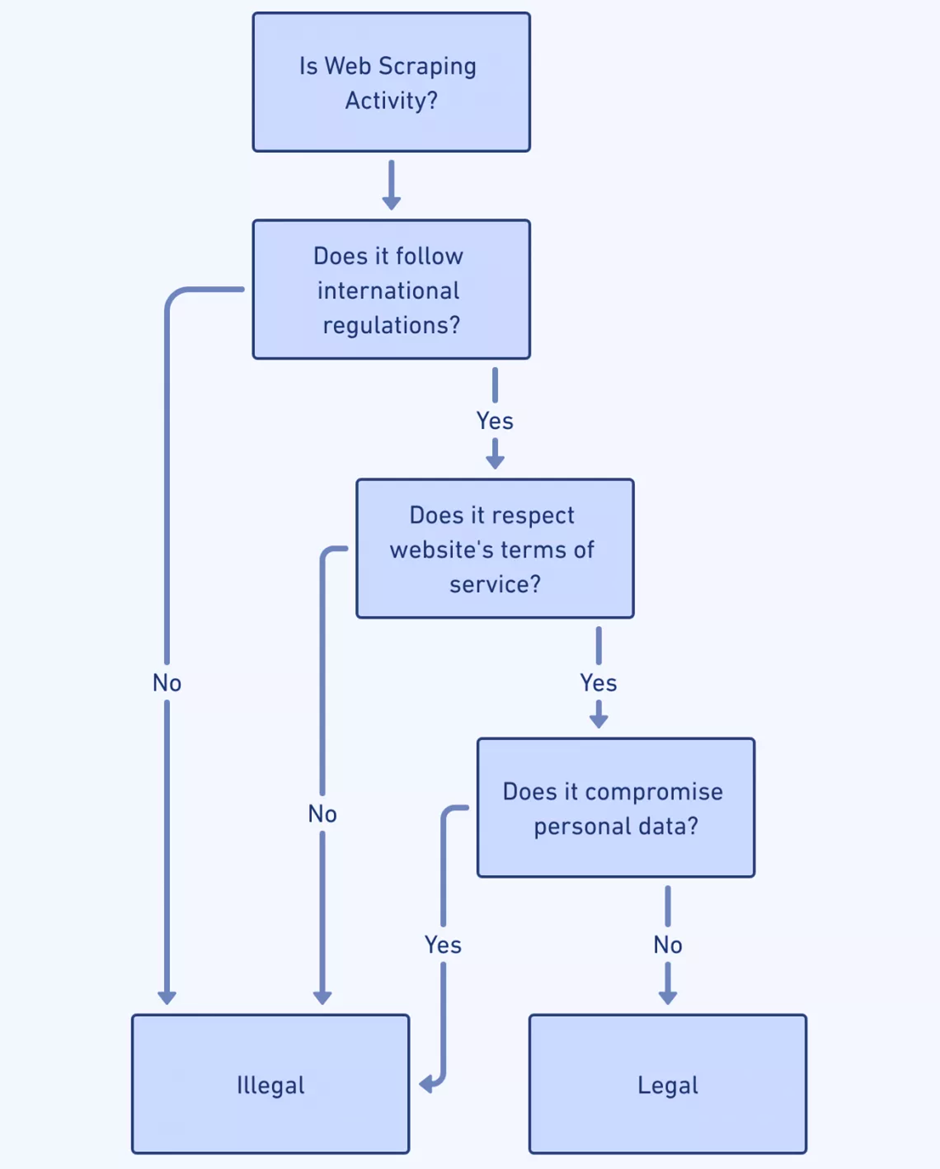
Da sich Web Scraping mit Fortschritten in der KI weiterentwickelt, werden ethische und rechtliche Auswirkungen immer komplexer. Web-Scraper müssen navigieren:
- Datenschutzgesetze : Scraper-Entwickler sollten Gesetze wie DSGVO und CCPA verstehen, um Rechtsverstöße im Zusammenhang mit personenbezogenen Daten zu vermeiden.
- Einhaltung der Nutzungsbedingungen : Die Einhaltung der Nutzungsbedingungen einer Website ist von entscheidender Bedeutung. Ein Verstoß dagegen kann zu Rechtsstreitigkeiten oder einer Zugangsverweigerung führen.
- Urheberrechtlich geschütztes Material : Der erhaltene Inhalt darf keine Urheberrechte verletzen, was Bedenken hinsichtlich der Verbreitung und Verwendung der gecrackten Daten aufwirft.
- Robots-Ausschlussstandard : Die Einhaltung der robots.txt-Datei von Websites zeigt ethisches Verhalten an, indem die Scraping-Präferenzen des Websitebesitzers berücksichtigt werden.
- Einwilligung des Nutzers : Wenn es um personenbezogene Daten geht, gewährleistet die Sicherstellung, dass die Einwilligung des Nutzers eingeholt wurde, die ethische Integrität.
- Transparenz : Eine klare Kommunikation über die Absicht und den Umfang von Scraping-Vorgängen fördert ein Umfeld des Vertrauens und der Verantwortlichkeit.
Bildquelle: https://scrape-it.cloud/
Die Bewältigung dieser Überlegungen erfordert Wachsamkeit und die Verpflichtung zu ethischen Praktiken.

Fortschritte bei KI-Algorithmen für eine verbesserte Datenextraktion
In letzter Zeit haben wir eine bemerkenswerte Entwicklung bei KI-Algorithmen beobachtet, die die Landschaft der Datenextraktionsfunktionen erheblich verändert hat. Fortschrittliche Modelle des maschinellen Lernens, die eine verbesserte Fähigkeit zur Entschlüsselung komplizierter Muster demonstrieren, haben die Präzision der Datenextraktion auf ein beispielloses Niveau gehoben.
Die Fortschritte in der Verarbeitung natürlicher Sprache (NLP) haben das Kontextverständnis vertieft und erleichtern nicht nur die Extraktion relevanter Informationen, sondern ermöglichen auch die Interpretation subtiler semantischer Nuancen und Gefühle.
Das Aufkommen neuronaler Netze, insbesondere Convolutional Neural Networks (CNNs), hat eine Revolution bei der Extraktion von Bilddaten ausgelöst. Dieser Durchbruch ermöglicht es künstlicher Intelligenz, visuelle Inhalte aus den riesigen Weiten des Internets nicht nur zu erkennen, sondern auch zu klassifizieren.
Darüber hinaus hat Reinforcement Learning (RL) ein neues Paradigma eingeführt, bei dem KI-Tools im Laufe der Zeit optimale Scraping-Strategien verfeinern und so ihre betriebliche Effizienz steigern. Die Integration dieser Algorithmen in Web-Scraping-Tools hat zu Folgendem geführt:
- Anspruchsvolle Dateninterpretation und -analyse
- Verbesserte Anpassungsfähigkeit an verschiedene Webstrukturen
- Reduzierter Bedarf an menschlichem Eingreifen bei komplexen Aufgaben
- Verbesserte Effizienz bei der Handhabung umfangreicher Datenextraktionen
Hindernisse überwinden: CAPTCHAs, dynamische Inhalte und Datenqualität
Die Web-Scraping-Technologie muss mehrere Hürden überwinden:
- CAPTCHAs : KI-Website-Scraper nutzen jetzt fortschrittliche Bilderkennungs- und maschinelle Lernalgorithmen, um CAPTCHAs mit höherer Genauigkeit zu lösen und den Zugriff ohne menschliches Eingreifen zu ermöglichen.
- Dynamischer Inhalt : KI-Website-Scraper sind darauf ausgelegt, JavaScript und AJAX zu interpretieren, die dynamische Inhalte generieren, und stellen so sicher, dass Daten von Webanwendungen genauso effektiv erfasst werden wie von statischen Seiten.

Bildquelle: PromptCloud
- Datenqualität : Die Einführung von KI hat zu Verbesserungen bei der Identifizierung und Klassifizierung von Daten geführt. Dadurch soll sichergestellt werden, dass die gesammelten Informationen relevant und von hoher Qualität sind, wodurch die Notwendigkeit einer manuellen Bereinigung und Überprüfung verringert wird. KI-Website-Scraper lernen kontinuierlich, zwischen Rauschen und wertvollen Daten zu unterscheiden und verfeinern ihren Datenextraktionsprozess.
Fusion von KI mit Big Data Analytics im Web Scraping
Die Integration von künstlicher Intelligenz (KI) mit Big-Data-Analysen stellt einen transformativen Fortschritt im Web Scraping dar. In dieser Integration:
- KI-Algorithmen werden eingesetzt, um riesige Datensätze, die durch Scraping genutzt werden, zu interpretieren und zu analysieren und so Erkenntnisse in beispielloser Geschwindigkeit zu gewinnen.
- Elemente des maschinellen Lernens innerhalb der KI können die Datenextraktion weiter verbessern und lernen, Muster und Informationen effizient zu erkennen und zu extrapolieren.
- Big-Data-Analysen können diese Informationen dann verarbeiten und Unternehmen verwertbare Informationen liefern.
- Darüber hinaus hilft KI bei der Bereinigung und Strukturierung von Daten, einem entscheidenden Schritt für die effektive Nutzung von Big-Data-Analysen.
- Diese Synergie zwischen KI und Big Data Analytics beim Web Scraping ist entscheidend für zeitkritische Entscheidungen und den Erhalt von Wettbewerbsvorteilen.
Die zukünftige Landschaft: Vorhersagen und Potenzial für KI-Website-Scraper
Der Bereich des KI-Website-Scraping steht an einer bedeutenden Transformationsschwelle. Vorhersagen deuten auf Folgendes hin:
- Verbesserte kognitive Fähigkeiten, die es Scrapern ermöglichen, komplexe Daten mit menschenähnlichem Verständnis zu interpretieren.
- Integration mit anderen KI-Technologien wie der Verarbeitung natürlicher Sprache für eine differenziertere Datenextraktion.
- Selbstlernende Scraper, die ihre Methoden basierend auf Erfolgsraten verfeinern und so effizientere Datenerfassungsprotokolle erstellen.
- Bessere Einhaltung ethischer und rechtlicher Standards durch fortschrittliche Compliance-Algorithmen.
- Zusammenarbeit zwischen KI-Scrapern und Blockchain-Technologien für sichere und transparente Datentransaktionen.
Kontaktieren Sie uns noch heute unter sales@promptcloud.com und erfahren Sie, wie unsere hochmoderne KI-Website-Scraper-Technologie Ihre Datenextraktionsprozesse revolutionieren und Ihr Unternehmen zu neuen Höhen führen kann!