
So laden Sie Daten mit R und Python in BigQuery hoch
Veröffentlicht: 2023-06-06Die Welt der Webanalyse rast weiter auf den schicksalhaften 1. Juli zu, an dem Universal Analytics die Datenverarbeitung einstellt und durch Google Analytics 4 (GA4) ersetzt wird. Eine der wichtigsten Änderungen besteht darin, dass Sie in GA4 Daten nur für maximal 14 Monate auf der Plattform aufbewahren können. Dies ist eine große Änderung gegenüber UA, aber im Gegenzug können Sie GA4-Daten bis zu einem gewissen Grad kostenlos in BigQuery übertragen.
BigQuery ist eine äußerst nützliche Ressource für die Datenspeicherung über GA4 hinaus. Da es in wenigen Monaten wichtiger denn je wird, ist jetzt ein guter Zeitpunkt, es für alle Ihre Datenspeicheranforderungen zu nutzen. Oft ist es vorzuziehen, die Daten vor dem Hochladen auf irgendeine Weise zu manipulieren. Hierfür empfehlen wir die Verwendung eines in R oder Python geschriebenen Skripts, insbesondere wenn diese Art der Manipulation wiederholt durchgeführt werden muss. Sie können Daten auch direkt aus diesen Skripten in BigQuery hochladen, und genau das wird Ihnen dieser Blog zeigen.
Hochladen auf BigQuery von R
R ist eine äußerst leistungsfähige Sprache für die Datenwissenschaft und die am einfachsten zu verwendende Sprache zum Hochladen von Daten in BigQuery. Der erste Schritt besteht darin, alle notwendigen Bibliotheken zu importieren. Für dieses Tutorial benötigen wir die folgenden Bibliotheken:
library(googleAuthR)
library(bigQueryR)
Wenn Sie diese Bibliotheken noch nicht verwendet haben, führen Sie install.packages(<PACKAGE NAME>) in der Konsole aus, um sie zu installieren.
Als nächstes müssen wir uns mit dem oft schwierigsten und durchweg frustrierendsten Teil der Arbeit mit APIs befassen – der Autorisierung. Glücklicherweise ist dies mit R relativ einfach. Sie benötigen eine JSON-Datei mit Autorisierungsdaten. Dies finden Sie in der Google Cloud Console, dem gleichen Ort, an dem sich BigQuery befindet. Navigieren Sie zunächst zur Google Cloud Console und klicken Sie auf „APIs und Dienste“.
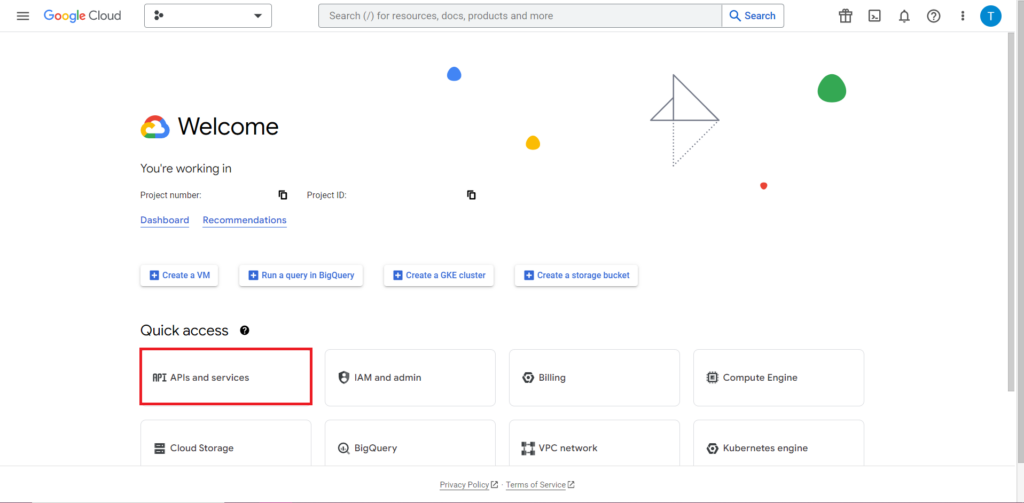
Klicken Sie anschließend in der Seitenleiste auf „Anmeldeinformationen“.
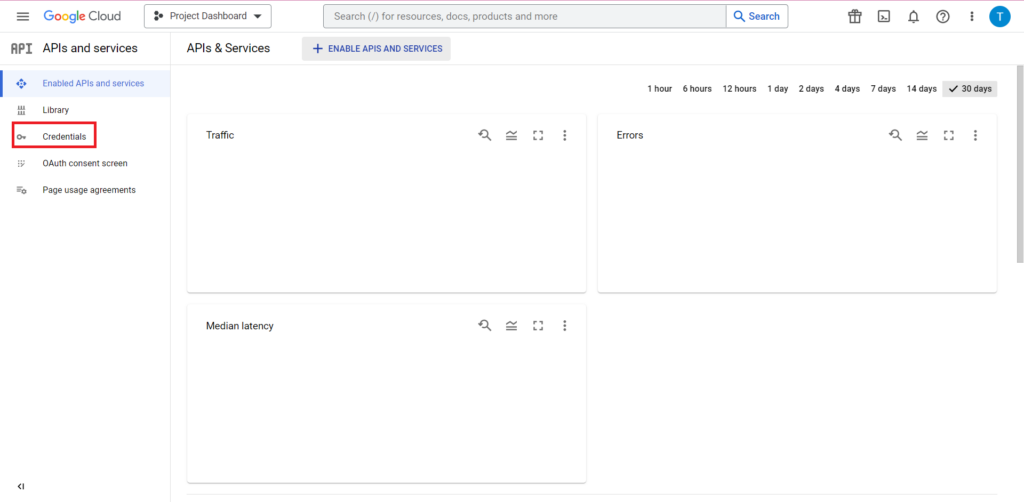
Auf der Seite „Anmeldeinformationen“ können Sie Ihre vorhandenen API-Schlüssel, OAuth 2.0-Client-IDs und Dienstkonten anzeigen. Dafür benötigen Sie eine OAuth 2.0-Client-ID. Klicken Sie also entweder ganz am Ende der entsprechenden Zeile für Ihre ID auf die Download-Schaltfläche oder erstellen Sie eine neue ID, indem Sie oben auf der Seite auf „Anmeldeinformationen erstellen“ klicken. Stellen Sie sicher, dass Ihre ID berechtigt ist, das entsprechende BigQuery-Projekt anzuzeigen und zu bearbeiten. Öffnen Sie dazu die Seitenleiste, bewegen Sie den Mauszeiger über „IAM und Admin“ und klicken Sie auf „IAM“. Auf dieser Seite können Sie Ihrem Dienstkonto Zugriff auf das entsprechende Projekt gewähren, indem Sie oben auf der Seite auf die Schaltfläche „Zugriff gewähren“ klicken.
Nachdem Sie die JSON-Datei erhalten und gespeichert haben, können Sie den Pfad dazu mit der Funktion gar_set_client() übergeben, um Ihre Anmeldeinformationen festzulegen. Der vollständige Code für die Autorisierung ist unten:
googleAuthR::gar_cache_empty()
googleAuthR::gar_set_client("C:\\Users\\Tom Brown\\Documents\\R\\APIs\\credentials.json")
bqr_auth(email = "<your email here>")
Natürlich möchten Sie den Pfad in der Funktion gar_set_client() durch den Pfad zu Ihrer eigenen JSON-Datei ersetzen und die E-Mail-Adresse, die Sie für den Zugriff auf BigQuery verwenden, in die Funktion bqr_auth() einfügen.
Sobald die Autorisierung vollständig eingerichtet ist, müssen wir einige Daten in BigQuery hochladen. Wir müssen diese Daten in einen Datenrahmen einfügen. Für die Zwecke dieses Artikels werde ich einige fiktive Daten mit einer Reihe von Standorten und Verkaufszahlen erstellen, aber höchstwahrscheinlich werden Sie echte Daten aus einer CSV-Datei oder einer Tabelle lesen. Um Daten aus einer CSV-Datei zu lesen, können Sie einfach die Funktion read.csv() verwenden und als Argument den Pfad zur Datei übergeben:
data <- read.csv("C:\\Users\\Tom Brown\\Documents\\Semetrical\\Blogs\\mycsv.csv")
Wenn Sie Ihre Daten alternativ in einer Tabellenkalkulation gespeichert haben, variiert Ihre Methode je nachdem, wo sich diese Tabellenkalkulation befindet. Wenn Ihre Tabelle in Google Sheets gespeichert ist, können Sie ihre Daten mithilfe der Googlesheets4-Bibliothek in R einlesen:
library(googlesheets4)
data <- read_sheet(ss=”<spreadsheet URL>”, sheet=”<name of tab>”)
Wenn Sie dieses Paket noch nicht verwendet haben, müssen Sie wie zuvor install.packages(„googlesheets4“) in der Konsole ausführen, bevor Sie Ihren Code ausführen.
Wenn Ihre Tabelle in Excel vorliegt, müssen Sie die readxl-Bibliothek verwenden, die Teil der Tidyverse-Bibliothek ist – etwas, das ich empfehle. Es enthält eine Vielzahl von Funktionen, die die Datenmanipulation in R erheblich vereinfachen:
library(tidyverse)
data <- read_excel(“C:\\Users\\Tom Brown\\Documents\\Semetrical\\Blogs\\myxl.xlsx”)
Und stellen Sie noch einmal sicher, dass Sie install.package(„tidyverse“) ausführen, falls Sie dies noch nicht getan haben!
Der letzte Schritt besteht darin, die Daten in BigQuery hochzuladen. Dazu benötigen Sie einen Ort in BigQuery, an dem Sie es hochladen können. Ihre Tabelle befindet sich in einem Datensatz, der sich in einem Projekt befindet, und Sie benötigen die Namen aller drei im folgenden Format:
bqr_upload_data(“<your project>”, “<your dataset>”, “<your table>”, <your dataframe>)
In meinem Fall bedeutet das, dass mein Code lautet:
bqr_upload_data(“my-project”, “test2”, “blogtestR”, data)
Wenn Ihre Tabelle noch nicht existiert, machen Sie sich keine Sorgen, der Code erstellt sie für Sie. Vergessen Sie nicht, die Namen Ihres Projekts, Datensatzes und Ihrer Tabelle in den obigen Code einzufügen (innerhalb der Anführungszeichen) und stellen Sie sicher, dass Sie den richtigen Datenrahmen hochladen! Sobald dies erledigt ist, sollten Ihre Daten wie folgt in BigQuery angezeigt werden:

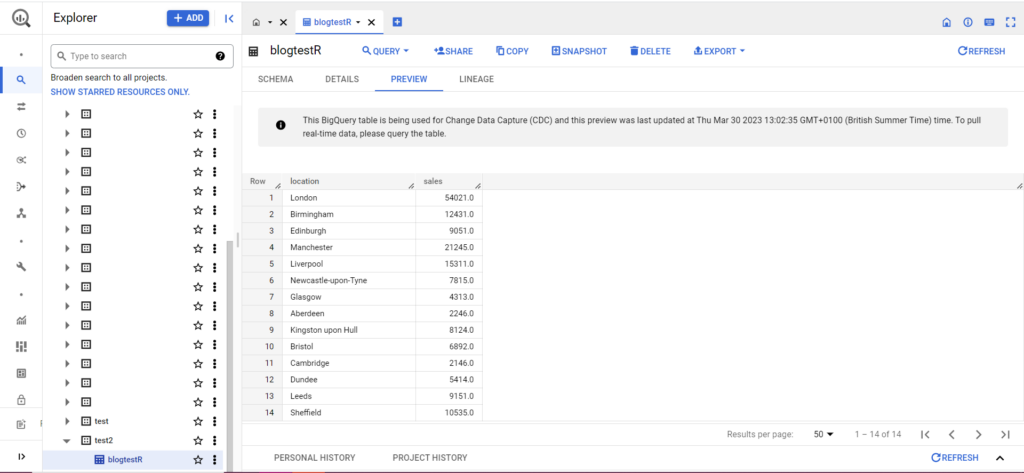
Nehmen wir als letzten Schritt an, Sie verfügen über zusätzliche Daten, die Sie zu BigQuery hinzufügen möchten. Angenommen, ich habe in meinen obigen Daten vergessen, einige Standorte auf dem Kontinent anzugeben, und ich möchte sie in BigQuery hochladen, aber die vorhandenen Daten nicht überschreiben. Hierzu verfügt bqr_upload_data über einen Parameter namens writeDisposition. writeDisposition hat zwei Einstellungen: „WRITE_TRUNCATE“ und „WRITE_APPEND“. Ersteres weist bqr_upload_data() an, die vorhandenen Daten in der Tabelle zu überschreiben, während letzteres es anweist, die neuen Daten anzuhängen. Um diese neuen Daten hochzuladen, schreibe ich:
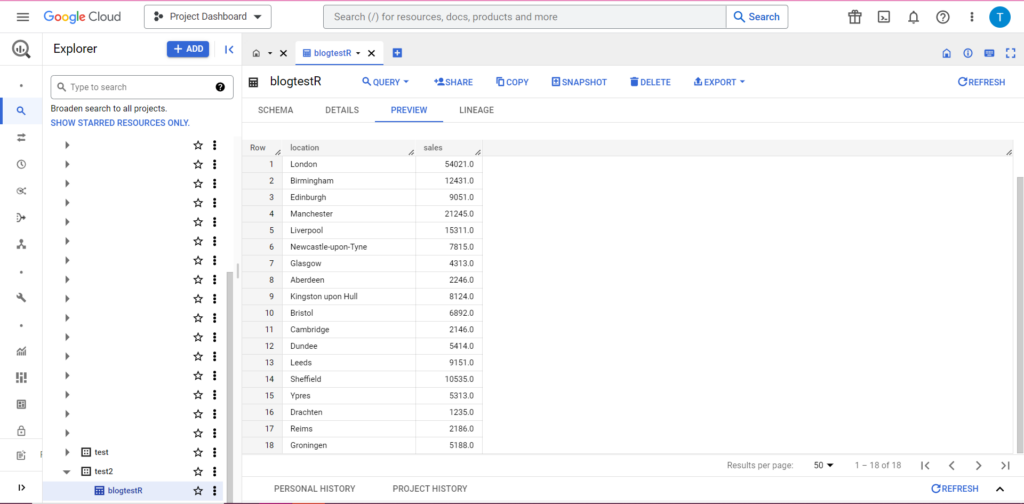
bqr_upload_data(“my-project”, “test2”, “blogtestR”, data2, writeDisposition = “WRITE_APPEND”))
Und tatsächlich können wir in BigQuery sehen, dass unsere Daten einige neue Mitbewohner haben:
Von Python auf BigQuery hochladen
In Python sind die Dinge etwas anders. Auch hier müssen wir einige Pakete importieren, also beginnen wir mit diesen:
import pandas as pd
from google.cloud import bigquery
from google.oauth2 import service_account
Die Autorisierung ist kompliziert. Auch hier benötigen wir eine JSON-Datei mit Anmeldeinformationen. Wie oben navigieren wir zur Google Cloud Console und klicken auf „APIs und Dienste“ und dann in der Seitenleiste auf „Anmeldeinformationen“. Dieses Mal gibt es unten auf der Seite einen Abschnitt namens „Dienstkonten“.
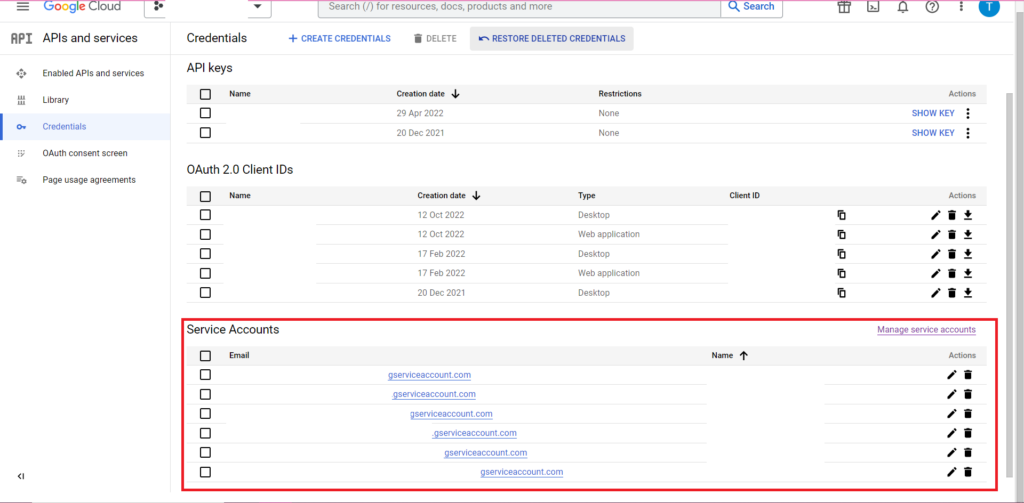
Dort können Sie entweder den Schlüssel zu Ihrem Dienstkonto herunterladen oder durch Klicken auf „Dienstkonto verwalten“ einen neuen Schlüssel oder ein neues Dienstkonto erstellen, für das Sie die Zugangsdaten herunterladen können.
Anschließend möchten Sie sicherstellen, dass Ihr Dienstkonto über die Berechtigung verfügt, auf Ihr BigQuery-Projekt zuzugreifen und es zu bearbeiten. Navigieren Sie erneut zur IAM-Seite unter „IAM & Admin“ in der Seitenleiste. Dort können Sie Ihrem Dienstkonto Zugriff auf das entsprechende Projekt gewähren, indem Sie oben auf der Seite auf die Schaltfläche „Zugriff gewähren“ klicken.
Sobald Sie das geklärt haben, können Sie den Autorisierungscode schreiben:
bqcreds = service_account.Credentials.from_service_account_file('myjson.json', scopes = ['https://www.googleapis.com/auth/cloud-platform'])
client = bigquery.Client(credentials=bqcreds, project=bqcreds.project_id,)
Als Nächstes müssen Sie Ihre Daten in einen Datenrahmen übertragen. Datenrahmen gehören zum Pandas-Paket und sind sehr einfach zu erstellen. Gehen Sie zum Einlesen aus einer CSV wie folgt vor:
data = pd.read_csv('C:\\Users\\Tom Brown\\Documents\\Semetrical\\Blogs\\mycsv.csv')
Natürlich müssen Sie den obigen Pfad durch den zu Ihrer eigenen CSV-Datei ersetzen. Gehen Sie zum Einlesen aus einer Excel-Datei wie folgt vor:
data = pd.read_excel('C:\\Users\\Tom Brown\\Documents\\Semetrical\\Blogs\\myxl.xlsx', sheet_name='mytab'>
Das Einlesen aus Google Sheets ist schwierig und erfordert eine weitere Autorisierungsrunde. Wir müssen einige neue Pakete importieren und die JSON-Anmeldeinformationsdatei verwenden, die wir im obigen R-Tutorial abgerufen haben. Sie können diesem Code folgen, um Ihre Daten zu autorisieren und zu lesen:
import gspread
from oauth2client.service_account import ServiceAccountCredentials
credentials = ServiceAccountCredentials.from_json_keyfile_name('myjson.json', scopes = ['https://spreadsheets.google.com/feeds'])
gc = gspead.authorize(credentials)
ss = gc.open_by_key('<spreadsheet key>')
sheet = ss.worksheet('<name of tab>')
data = pd.DataFrame(sheet.get_all_records())
Sobald Sie Ihre Daten in Ihrem Datenrahmen haben, ist es Zeit, sie erneut auf BigQuery hochzuladen! Sie können dies tun, indem Sie dieser Vorlage folgen:
table_id = “<your project>.<your dataset>.<your table>”
job_config0 = bigquery.LoadJobConfig(write_disposition = 'WRITE_TRUNCATE')
job = client.load_table_from_dataframe(data, table_id, job_config=job_config0)
job.result()
Als Beispiel ist hier der Code, den ich gerade geschrieben habe, um die zuvor erstellten Daten hochzuladen:
table_
job_config0 = bigquery.LoadJobConfig(write_disposition = 'WRITE_TRUNCATE')
job = client.load_table_from_dataframe(data, table_id, job_config=job_config0)
job.result()
Sobald dies erledigt ist, sollten die Daten sofort in BigQuery erscheinen!
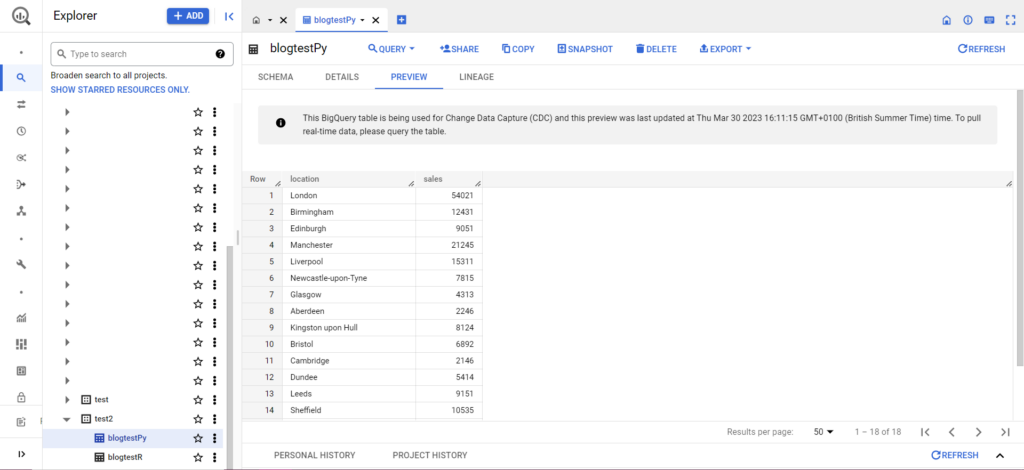
Mit diesen Funktionen können Sie noch viel mehr machen, wenn Sie erst einmal den Dreh raus haben. Wenn Sie mehr Kontrolle über Ihr Analyse-Setup erlangen möchten, ist Semetrical hier, um Ihnen zu helfen! Weitere Informationen dazu, wie Sie das Beste aus Ihren Daten herausholen, finden Sie in unserem Blog. Wenn Sie weitere Unterstützung rund um die Analyse benötigen, besuchen Sie bitte Web Analytics, um herauszufinden, wie wir Ihnen helfen können.