
Webcrawler – Ein vollständiger Leitfaden
Veröffentlicht: 2023-12-12Web-Crawling
Webcrawling, ein grundlegender Prozess im Bereich der Webindizierung und Suchmaschinentechnologie, bezieht sich auf das automatisierte Durchsuchen des World Wide Web durch ein Softwareprogramm, das als Webcrawler bekannt ist. Diese Crawler, manchmal auch Spiders oder Bots genannt, navigieren systematisch durch das Internet, um Informationen von Websites zu sammeln. Dieser Prozess ermöglicht die Sammlung und Indexierung von Daten, die für Suchmaschinen von entscheidender Bedeutung sind, um aktuelle und relevante Suchergebnisse bereitzustellen.
Hauptfunktionen des Web-Crawlings:
- Inhalt indizieren : Webcrawler scannen Webseiten und indizieren ihren Inhalt, um ihn durchsuchbar zu machen. Bei diesem Indexierungsprozess werden Text, Bilder und andere Inhalte auf einer Seite analysiert, um deren Thema zu verstehen.
- Linkanalyse : Crawler folgen Links von einer Webseite zur anderen. Dies hilft nicht nur beim Entdecken neuer Webseiten, sondern auch beim Verständnis der Beziehungen und Hierarchien zwischen verschiedenen Webseiten.
- Erkennung von Inhaltsaktualisierungen : Durch den regelmäßigen erneuten Besuch von Webseiten können Crawler Aktualisierungen und Änderungen erkennen und so sicherstellen, dass der indizierte Inhalt aktuell bleibt.
Unsere Schritt-für-Schritt-Anleitung zum Erstellen eines Webcrawlers hilft Ihnen, mehr über den Webcrawler-Prozess zu verstehen.
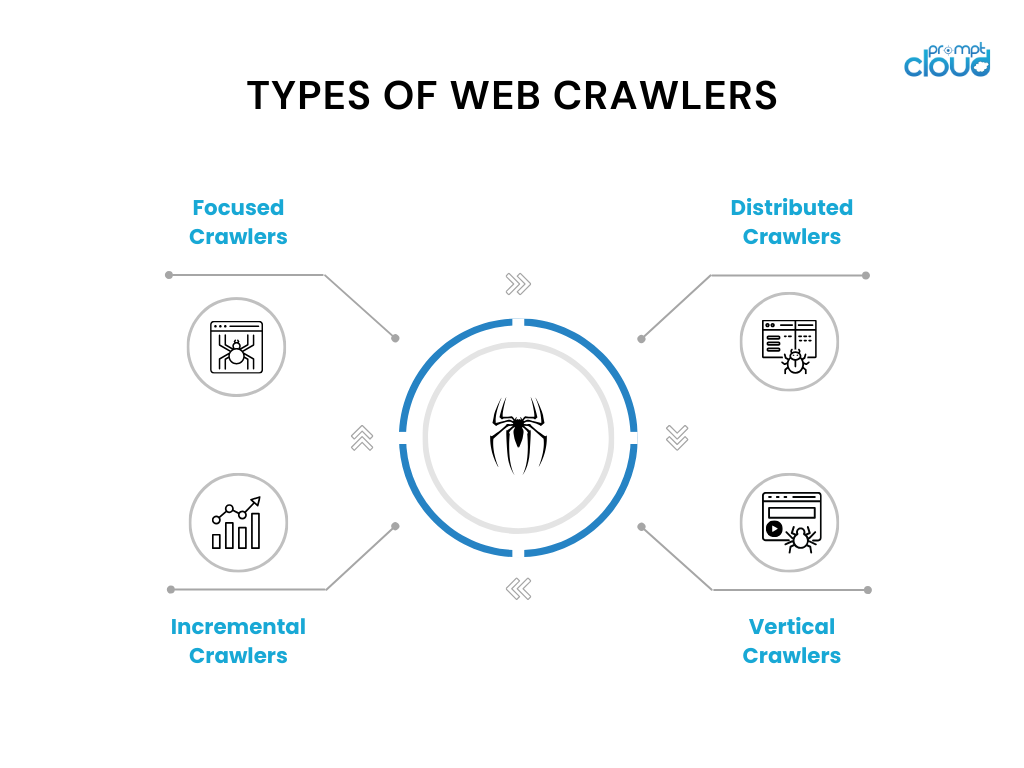
Was ist ein Webcrawler?
Ein Webcrawler, auch Spider oder Bot genannt, ist ein automatisiertes Softwareprogramm, das das World Wide Web zum Zwecke der Webindizierung systematisch durchsucht. Seine Hauptfunktion besteht darin, den Inhalt von Webseiten, einschließlich Text, Bildern und anderen Medien, zu scannen und zu indizieren. Webcrawler beginnen mit einem bekannten Satz von Webseiten und folgen den Links auf diesen Seiten, um neue Seiten zu entdecken. Dabei verhalten sie sich ähnlich wie eine Person, die im Internet surft. Durch diesen Prozess können Suchmaschinen ihre Daten sammeln und aktualisieren und so sicherstellen, dass Benutzer aktuelle und umfassende Suchergebnisse erhalten. Das effiziente Funktionieren von Webcrawlern ist von entscheidender Bedeutung, um den riesigen und ständig wachsenden Bestand an Online-Informationen zugänglich und durchsuchbar zu halten.
So funktioniert ein Webcrawler
Webcrawler funktionieren, indem sie systematisch das Internet durchsuchen, um Website-Inhalte zu sammeln und zu indizieren, ein Prozess, der für Suchmaschinen von entscheidender Bedeutung ist. Sie beginnen mit einer Reihe bekannter URLs und greifen auf diese Webseiten zu, um Inhalte abzurufen. Während sie die Seiten analysieren, identifizieren sie alle Hyperlinks und fügen sie der Liste der als nächstes zu besuchenden URLs hinzu, wodurch die Struktur des Webs effektiv abgebildet wird. Jede besuchte Seite wird verarbeitet, um relevante Informationen wie Text, Bilder und Metadaten zu extrahieren, die dann in einer Datenbank gespeichert werden. Diese Daten bilden die Grundlage für den Index einer Suchmaschine und ermöglichen so die Bereitstellung schneller und relevanter Suchergebnisse.
Webcrawler müssen bestimmte Einschränkungen einhalten, z. B. die von Websitebesitzern in robots.txt-Dateien festgelegten Regeln befolgen und eine Überlastung der Server vermeiden, um einen ethischen und effizienten Crawling-Prozess sicherzustellen. Während sie durch Milliarden von Webseiten navigieren, stehen diese Crawler vor Herausforderungen wie dem Umgang mit dynamischen Inhalten, der Verwaltung doppelter Seiten und der Aktualisierung der neuesten Webtechnologien, was ihre Rolle im digitalen Ökosystem sowohl komplex als auch unverzichtbar macht. Hier finden Sie einen ausführlichen Artikel zur Funktionsweise von Webcrawlern.
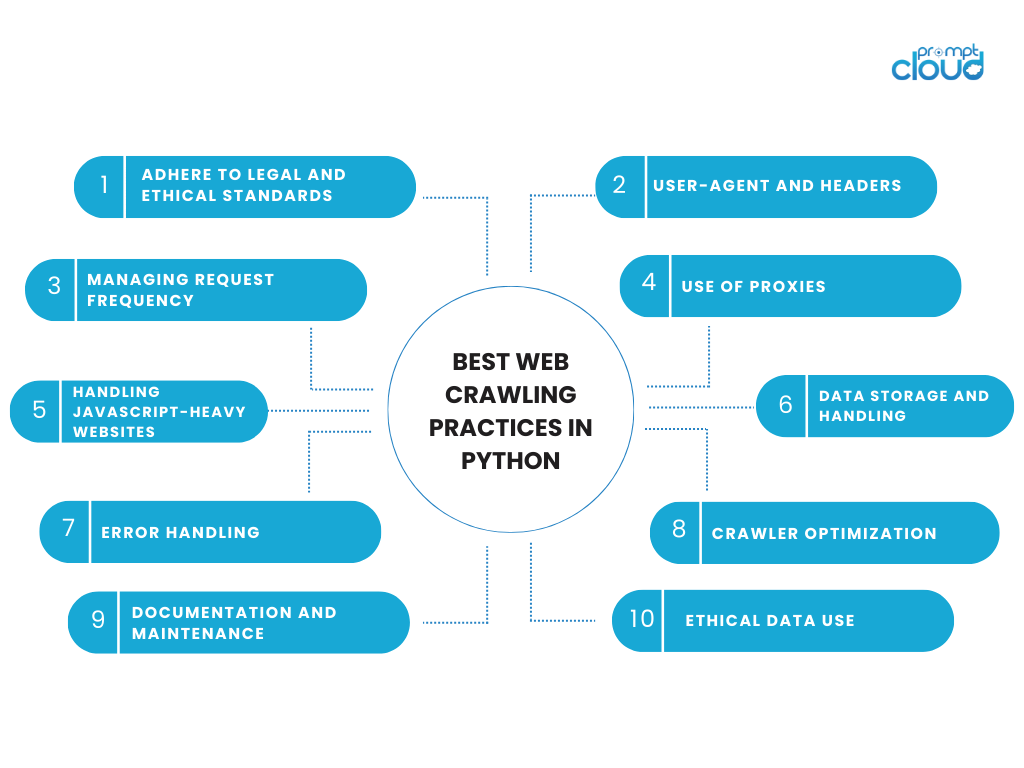
Python-Webcrawler
Python, bekannt für seine Einfachheit und Lesbarkeit, ist eine ideale Programmiersprache zum Erstellen von Webcrawlern. Sein umfangreiches Ökosystem an Bibliotheken und Frameworks vereinfacht das Schreiben von Skripten, die im Web navigieren, Daten analysieren und Daten daraus extrahieren. Hier sind die wichtigsten Aspekte, die Python zur ersten Wahl für das Web-Crawling machen:
Wichtige Python-Bibliotheken für das Web-Crawling:
- Anfragen : Diese Bibliothek wird zum Senden von HTTP-Anfragen an Webseiten verwendet. Es ist einfach zu bedienen und kann verschiedene Arten von Anfragen verarbeiten, die für den Zugriff auf Webseiteninhalte unerlässlich sind.
- Beautiful Soup : Beautiful Soup ist auf das Parsen von HTML- und XML-Dokumenten spezialisiert und ermöglicht die einfache Extraktion von Daten aus Webseiten, wodurch die Navigation durch die Tag-Struktur des Dokuments einfacher wird.
- Scrapy : Scrapy ist ein Open-Source-Webcrawler-Framework und bietet ein Komplettpaket zum Schreiben von Webcrawlern. Es verarbeitet Anfragen, Antwortanalyse und Datenextraktion nahtlos.
Vorteile der Verwendung von Python für das Web-Crawling:
- Benutzerfreundlichkeit : Die unkomplizierte Syntax von Python macht es auch für Programmieranfänger zugänglich.
- Robuster Community-Support : Eine große Community und eine Fülle von Dokumentationen helfen bei der Fehlerbehebung und Verbesserung der Crawler-Funktionalität.
- Flexibilität und Skalierbarkeit : Python-Crawler können je nach Bedarf so einfach oder komplex sein und von kleinen bis hin zu großen Projekten skaliert werden.
Beispiel eines einfachen Python-Webcrawlers:
Importanfragen

aus bs4 Import BeautifulSoup
# Definieren Sie die zu crawlende URL
URL = „http://example.com“
# Senden Sie eine HTTP-Anfrage an die URL
Antwort = Anfragen.get(URL)
# Analysieren Sie den HTML-Inhalt der Seite
Suppe = BeautifulSoup(response.text, 'html.parser')
# Extrahieren und drucken Sie alle Hyperlinks
für Link in Suppe.find_all('a'):
print(link.get('href'))
Dieses einfache Skript demonstriert die grundlegende Funktionsweise eines Python-Webcrawlers. Es ruft mithilfe von Anfragen den HTML-Inhalt einer Webseite ab, analysiert ihn mit Beautiful Soup und extrahiert alle Hyperlinks.
Python-Webcrawler zeichnen sich durch einfache Entwicklung und Effizienz bei der Datenextraktion aus.
Ob für SEO-Analysen, Data Mining oder digitales Marketing – Python bietet eine robuste und flexible Grundlage für Web-Crawling-Aufgaben und ist damit eine ausgezeichnete Wahl für Programmierer und Datenwissenschaftler gleichermaßen.
Anwendungsfälle für Web-Crawling
Web-Crawling hat ein breites Anwendungsspektrum in verschiedenen Branchen, was seine Vielseitigkeit und Bedeutung im digitalen Zeitalter widerspiegelt. Hier sind einige der wichtigsten Anwendungsfälle:
Suchmaschinenindizierung
Der bekannteste Einsatz von Webcrawlern ist die Erstellung eines durchsuchbaren Index des Webs durch Suchmaschinen wie Google, Bing und Yahoo. Crawler scannen Webseiten, indizieren ihren Inhalt und ordnen sie anhand verschiedener Algorithmen, sodass sie für Benutzer durchsuchbar sind.
Data Mining und Analyse
Unternehmen nutzen Webcrawler, um Daten über Markttrends, Verbraucherpräferenzen und Wettbewerb zu sammeln. Forscher setzen Crawler ein, um Daten aus mehreren Quellen für akademische Studien zusammenzufassen.
SEO-Überwachung
Webmaster nutzen Crawler, um zu verstehen, wie Suchmaschinen ihre Websites sehen, und helfen so bei der Optimierung der Website-Struktur, des Inhalts und der Leistung. Sie werden auch verwendet, um die Websites von Wettbewerbern zu analysieren, um deren SEO-Strategien zu verstehen.
Inhaltsaggregation
Crawler werden von Nachrichten- und Content-Aggregationsplattformen verwendet, um Artikel und Informationen aus verschiedenen Quellen zu sammeln. Aggregation von Inhalten von Social-Media-Plattformen, um Trends, beliebte Themen oder spezifische Erwähnungen zu verfolgen.
E-Commerce und Preisvergleich
Crawler helfen bei der Verfolgung von Produktpreisen auf verschiedenen E-Commerce-Plattformen und unterstützen so wettbewerbsfähige Preisstrategien. Sie werden auch zum Katalogisieren von Produkten verschiedener E-Commerce-Sites auf einer einzigen Plattform verwendet.
Immobilienanzeigen
Crawler sammeln Immobilienangebote von verschiedenen Immobilien-Websites, um Benutzern einen konsolidierten Überblick über den Markt zu bieten.
Stellenangebote und Rekrutierung
Aggregation von Stellenangeboten verschiedener Websites zur Bereitstellung einer umfassenden Plattform für die Jobsuche. Einige Personalvermittler nutzen Crawler, um das Internet nach potenziellen Kandidaten mit bestimmten Qualifikationen zu durchsuchen.
Maschinelles Lernen und KI-Training
Crawler können riesige Datenmengen aus dem Web sammeln, die zum Trainieren von Modellen für maschinelles Lernen in verschiedenen Anwendungen verwendet werden können.
Web Scraping vs. Web Crawling
Web Scraping und Web Crawling sind zwei Techniken, die häufig zum Sammeln von Daten von Websites verwendet werden, aber sie dienen unterschiedlichen Zwecken und funktionieren auf unterschiedliche Weise. Das Verständnis der Unterschiede ist für jeden, der an der Datenextraktion oder Webanalyse beteiligt ist, von entscheidender Bedeutung.
Web Scraping
- Definition : Beim Web Scraping werden bestimmte Daten aus Webseiten extrahiert. Der Schwerpunkt liegt auf der Umwandlung unstrukturierter Webdaten (normalerweise im HTML-Format) in strukturierte Daten, die gespeichert und analysiert werden können.
- Gezielte Datenextraktion : Scraping wird häufig verwendet, um spezifische Informationen von Websites zu sammeln, wie z. B. Produktpreise, Lagerbestandsdaten, Nachrichtenartikel, Kontaktinformationen usw.
- Tools und Techniken : Dabei werden Tools oder Programme (häufig Python, PHP, JavaScript) verwendet, um eine Webseite anzufordern, den HTML-Inhalt zu analysieren und die gewünschten Informationen zu extrahieren.
- Anwendungsfälle : Marktforschung, Preisüberwachung, Lead-Generierung, Daten für Modelle des maschinellen Lernens usw.
Web-Crawling
- Definition : Web-Crawling hingegen ist der Prozess des systematischen Durchsuchens des Internets, um Webinhalte herunterzuladen und zu indizieren. Es wird hauptsächlich mit Suchmaschinen in Verbindung gebracht.
- Indexierung und Linkverfolgung : Crawler oder Spider werden verwendet, um eine Vielzahl von Seiten zu besuchen, um die Struktur und Verknüpfungen der Website zu verstehen. Sie indizieren normalerweise den gesamten Inhalt einer Seite.
- Automatisierung und Skalierung : Web-Crawling ist ein stärker automatisierter Prozess, der die Datenextraktion in großem Umfang über viele Webseiten oder ganze Websites hinweg bewältigen kann.
- Überlegungen : Crawler müssen die von Websites festgelegten Regeln wie die in robots.txt-Dateien respektieren und sind so konzipiert, dass sie navigieren können, ohne Webserver zu überlasten.
Web-Crawling-Tools
Web-Crawling-Tools sind wesentliche Instrumente im digitalen Werkzeugkasten von Unternehmen, Forschern und Entwicklern und bieten eine Möglichkeit, die Datenerfassung von verschiedenen Websites im Internet zu automatisieren. Diese Tools dienen dazu, Webseiten systematisch zu durchsuchen, nützliche Informationen zu extrahieren und für die spätere Verwendung zu speichern. Hier finden Sie eine Übersicht über Webcrawler-Tools und ihre Bedeutung:
Funktionalität : Web-Crawling-Tools sind so programmiert, dass sie durch Websites navigieren, relevante Informationen identifizieren und diese abrufen. Sie ahmen das Surfverhalten von Menschen nach, tun dies jedoch in viel größerem Umfang und mit viel größerer Geschwindigkeit.
Datenextraktion und -indizierung : Diese Tools analysieren die Daten auf Webseiten, die Text, Bilder, Links und andere Medien umfassen können, und organisieren sie dann in einem strukturierten Format. Dies ist besonders nützlich für die Erstellung von Informationsdatenbanken, die leicht durchsucht und analysiert werden können.
Anpassung und Flexibilität : Viele Web-Crawling-Tools bieten Anpassungsoptionen, mit denen Benutzer festlegen können, welche Websites gecrawlt werden sollen, wie tief in die Website-Architektur vorgedrungen werden soll und welche Art von Daten extrahiert werden sollen.
Anwendungsfälle : Sie werden für verschiedene Zwecke verwendet, wie z. B. Suchmaschinenoptimierung (SEO), Marktforschung, Inhaltsaggregation, Wettbewerbsanalyse und Datenerfassung für maschinelle Lernprojekte.
Unser aktueller Artikel bietet einen detaillierten Überblick über die besten Web-Crawling-Tools 2024. Schauen Sie sich den Artikel an, um mehr zu erfahren. Kontaktieren Sie uns unter sales@promptcloud.com für individuelle Web-Crawling-Lösungen.