
Web Data Scraping im Zeitalter von Big Data: Chancen und ethische Dilemmata
Veröffentlicht: 2024-05-29Web Data Scraping und Big Data Analytics
Web Data Scraping hat sich zu einem zentralen Mechanismus für die Erfassung von Online-Daten entwickelt. Dieser Prozess beinhaltet den automatisierten Abruf von Informationen von Websites und verwandelt das unstrukturierte Web in eine Fülle strukturierter Daten, die zur Analyse bereit sind.
Bildquelle: https://www.sas.com/
Gleichzeitig hat sich die Big-Data-Analyse eine Nische bei der Erkennung von Mustern, Trends und Erkenntnissen aus den riesigen Datenmengen geschaffen, die häufig durch Web-Data-Scraping gesammelt werden. Da riesige Datenmengen (ca. 2,5 Trillionen Bytes an Daten, die jeden Tag generiert werden) immer zugänglicher werden, eröffnet die Synthese von Web-Data-Scraping mit Big-Data-Analysen unzählige Möglichkeiten für Unternehmen, Forscher und politische Entscheidungsträger.
Durch die geschickte Kombination dieser technologischen Fähigkeiten sind sie in der Lage, von datengestützter Entscheidungsfindung zu profitieren, Serviceinnovationen voranzutreiben und strategische Vorhaben zu gestalten, die auf ihre Ziele zugeschnitten sind. Dennoch ist es wichtig, die auftauchenden ethischen Dilemmata anzuerkennen, die sich aus der synergetischen Beziehung zwischen diesen fortschrittlichen Werkzeugen ergeben.
Bei der entscheidenden Balance zwischen der Maximierung des Datenwerts und der Wahrung der Privatsphäre des Einzelnen muss ein schmaler Grat beschritten werden, um sicherzustellen, dass keiner der beiden Aspekte den anderen in den Schatten stellt.
Vorteile von Web Data Scraping für Big-Data-Projekte
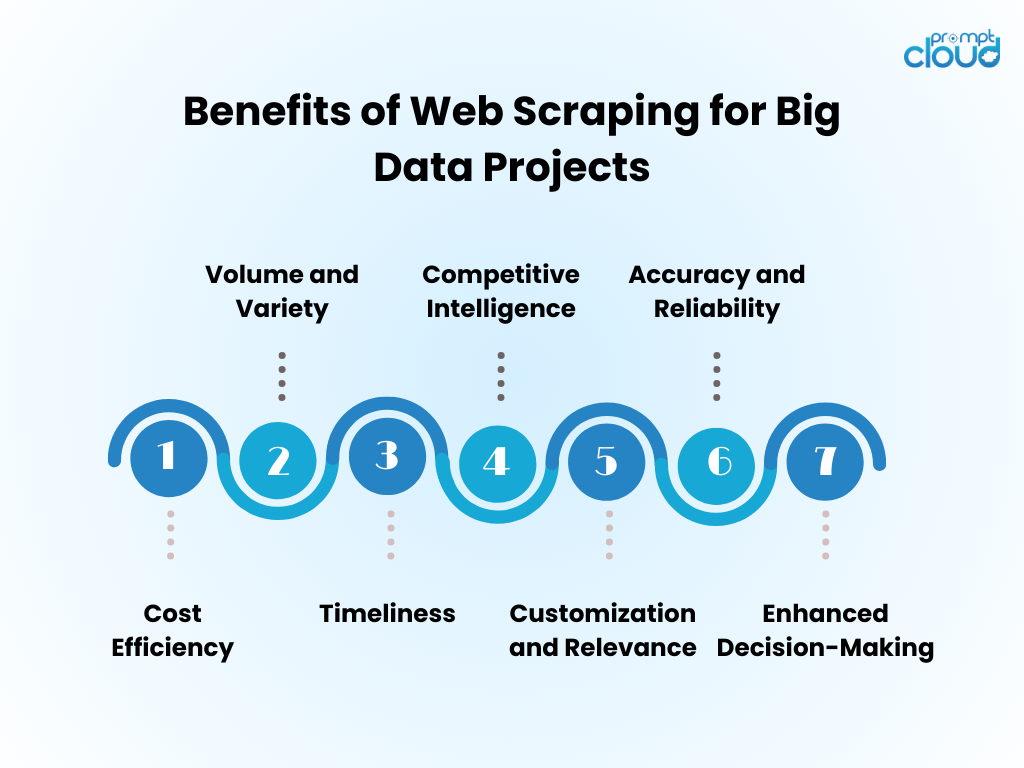
- Kosteneffizienz : Durch die Automatisierung der Datenerfassung durch Web Scraping werden die Personalkosten erheblich gesenkt und die Zeit bis zur Erkenntnis verkürzt.
- Volumen und Vielfalt : Es ermöglicht die Erfassung großer Datenmengen aus verschiedenen Quellen, die für die Bereitstellung von Big-Data-Analysen von entscheidender Bedeutung sind.
- Aktualität : Web Scraping liefert Daten in Echtzeit oder nahezu in Echtzeit und ermöglicht so eine flexiblere Reaktion auf Markttrends.
- Competitive Intelligence : Es gibt Unternehmen die Möglichkeit, Wettbewerber und Branchenveränderungen genau zu überwachen.
- Anpassung und Relevanz : Daten können auf spezifische Bedürfnisse zugeschnitten werden, um sicherzustellen, dass die Analyse relevant und fokussiert ist.
- Genauigkeit und Zuverlässigkeit : Automatisiertes Scraping minimiert menschliche Fehler und führt zu genaueren Datensätzen.
- Verbesserte Entscheidungsfindung : Der Zugriff auf zeitnahe, relevante Daten unterstützt fundierte Entscheidungsfindung und strategische Planung.
Web-Scraping-Techniken: Von einfach bis fortgeschritten

Bildquelle: loginworks
Das Web-Data-Scraping hat sich mit der Technologie weiterentwickelt, angefangen bei grundlegenden Techniken, die mit zunehmender Datenkomplexität weiterentwickelt werden.
- Grundlegende Techniken : Zunächst rufen Scraper Daten über einfache HTTP-Anfragen ab, um HTML-Seiten zu erhalten, und analysieren den Inhalt über Bibliotheken wie Beautiful Soup in Python. Diese Tools kommen mit unkomplizierten Websites gut zurecht.
- Fortgeschrittene Techniken : Für dynamische Inhalte entwickeln sich die Techniken weiter und umfassen Automatisierungstools wie Selenium, die mit JavaScript interagieren und das Browserverhalten nachahmen können.
- Fortgeschrittene Techniken : Auf dem Weg zum fortgeschrittenen Scraping umfassen die Methoden Headless-Browser und Proxyserver, um Anti-Scraping-Maßnahmen zu umgehen. Die Datenextraktion wird durch maschinelle Lernalgorithmen verfeinert, indem natürliche Sprache und Bilder verarbeitet werden, um Informationen abzurufen.
- Ethische Überlegungen : Unabhängig von der Komplexität der Technik bleiben ethische Dilemmata bestehen, die ein Gleichgewicht zwischen Datenzugriff und Respekt für Privatsphäre und Eigentum erfordern.
Einbindung von Web-Scraped-Daten in Big Data Analytics
Web-Scraping-Daten können, wenn sie in Big-Data-Analysen integriert werden, umfassende Markteinblicke und Verbrauchertrends aufdecken. Analysten verschmelzen im Internet gesammelte Informationen mit vorhandenen Datensätzen und verbessern so die Tiefe und Breite der Analyseergebnisse. Diese Verschmelzung führt zu verbesserten Vorhersagemodellen, maßgeschneiderten Marketingstrategien und verfeinerten Verbraucherprofilen.

- Datenbereinigung: Gekratzte Daten erfordern eine sorgfältige Bereinigung, um die Genauigkeit der Analysen sicherzustellen.
- Datenintegration: Die Kombination von Scraped-Daten mit anderen Quellen erfordert fortschrittliche Datenintegrationstechniken.
- Analyseverbesserung: Mit zusätzlichen Daten können maschinelle Lernalgorithmen differenziertere Muster aufdecken.
- Ethische Überlegungen: Analysten müssen sicherstellen, dass die Nutzung von Webdaten den rechtlichen und ethischen Standards entspricht.
Der erweiterte Datenpool treibt Innovationen voran, erfordert jedoch eine strenge Methodik und ethische Kontrolle.
Best Practices für effizientes Web Scraping
- Respektieren Sie die robots.txt-Protokolle. Scrapen Sie keine Websites, die dies über ihre Robots-Datei nicht zulassen.
- Planen Sie Scraping-Aktivitäten außerhalb der Spitzenzeiten, um die Auswirkungen auf die Leistung des Zielservers zu minimieren.
- Nutzen Sie Caching, um ein erneutes Scrapen desselben Inhalts zu vermeiden, die Daten der Website zu respektieren und Bandbreite zu sparen.
- Implementieren Sie eine entsprechende Fehlerbehandlung, um einen Absturz Ihres Scrapers zu verhindern und im Fehlerfall nicht zu viele Anfragen zu senden.
- Rotieren Sie Benutzeragenten und IP-Adressen, um eine Blockierung zu verhindern und so ein natürlicheres Surfverhalten zu simulieren.
- Bleiben Sie über rechtliche und ethische Web-Scraping-Praktiken auf dem Laufenden und stellen Sie sicher, dass Ihre Scraping-Aktivitäten nicht gegen Urheberrechte oder Datenschutzgesetze verstoßen.
- Optimieren Sie den Code, um effizient zu sein und die Belastung sowohl des Scraping-Systems als auch der Zielwebsites zu reduzieren.
- Aktualisieren Sie den Scraping-Code regelmäßig, um ihn an Änderungen im Website-Layout oder in der Technologie anzupassen und so die Wirksamkeit und Genauigkeit Ihres Datenabrufs aufrechtzuerhalten.
- Speichern Sie gesammelte Daten sicher und verwalten Sie sie unter Einhaltung aller relevanten Datenschutzbestimmungen.
Zukunft des Web Scraping im Zeitalter von Big Data
Da Big Data immer weiter wächst, wird das Web Data Scraping noch stärker in die Datenanalyse und Business Intelligence integriert. Die Zukunft wird wahrscheinlich Folgendes sehen:
- Verbesserte Modelle für maschinelles Lernen, die mit riesigen Datensätzen trainiert wurden, die durch Scraping gewonnen wurden, und so die Genauigkeit und Erkenntnisse verbessern.
- Erhöhte Nachfrage nach Daten-Scraping in Echtzeit, das es Unternehmen ermöglicht, schnellere, datengesteuerte Entscheidungen zu treffen.
- Entwicklung ausgefeilterer Scraping-Tools zur Navigation durch Anti-Scraping-Technologien und zur Aufrechterhaltung ethischer Datenerfassungspraktiken.
- Strengere Vorschriften und Datenschutzgesetze prägen die Web-Data-Scraping-Methoden und stellen sicher, dass Daten verantwortungsvoll und mit Einwilligung erfasst werden.
- Das Aufkommen von Scraping-as-a-Service-Plattformen, die maßgeschneiderte Datenextraktion für Unternehmen jeder Größe bieten.
Mit diesen Fortschritten wird Web Scraping weiterhin ein wichtiges Werkzeug im Big-Data-Toolkit bleiben.
Sollte manuelles Web-Scraping entmutigend sein oder Hilfe bei der Bewältigung komplizierter Herausforderungen im Zusammenhang mit der Beschaffung wertvoller Daten benötigt werden, können Sie sicher sein, dass PromptCloud bereit ist, Ihnen zu helfen!
Wir sind auf die Bereitstellung umfassender Web-Scraping-Lösungen spezialisiert, die speziell für Big-Data-Initiativen entwickelt wurden und eine zuverlässige Datenextraktion in großem Maßstab gewährleisten.
Vertrauen Sie darauf, dass wir die anspruchsvollen Aspekte angehen, sodass Sie sich auf die Generierung fundierter Entscheidungen mithilfe robuster und aussagekräftiger Datensätze konzentrieren können. Kontaktieren Sie uns unter sales@promptcloud.com und erfahren Sie, wie unser Fachwissen Ihren Big-Data-Plan vorantreiben kann!