
Was ist Datenextraktion: Ein Leitfaden für Anfänger
Veröffentlicht: 2023-11-07In einer Zeit, in der Daten so wertvoll sind wie Währungen, kann die Fähigkeit, diese Daten effizient zu extrahieren, Ihr Unternehmen von der Konkurrenz abheben. Die Datenextraktion ist nicht nur ein technischer Prozess; Es ist eine strategische Angelegenheit, die, wenn sie richtig umgesetzt wird, Erkenntnisse liefern kann, die zu intelligenteren Geschäftsentscheidungen und robustem Wachstum führen. Dieser Blogbeitrag befasst sich mit dem Was, Warum und Wie der Datenextraktion und vermittelt Ihnen das Wissen, um ihr volles Potenzial auszuschöpfen.
Was ist Datenextraktion?
Bei der Datenextraktion werden strukturierte oder unstrukturierte Daten aus verschiedenen Quellen wie Datenbanken, Websites, Dokumenten, Bildern usw. abgerufen. Diese Daten werden dann in ein besser verwaltbares und benutzerfreundlicheres Format konvertiert, beispielsweise in eine Tabellenkalkulation oder eine Datenbank. Ziel ist es, diese Informationen so zu sammeln, dass ihre Bedeutung erhalten bleibt und sie gleichzeitig für Analysen und Business Intelligence zugänglich gemacht werden.
Quelle: https://papersoft-dms.com/
Warum ist die Datenextraktion so wichtig?
- Fundierte Entscheidungsfindung: Extrahierte Daten bilden die Grundlage für Analysen, die Trends aufdecken, Ergebnisse vorhersagen und strategische Entscheidungen leiten können.
- Effizienz: Die Automatisierung von Datenextraktionsprozessen spart Zeit und Ressourcen und eliminiert manuelle Fehler und Redundanzen.
- Integration: Es ermöglicht die Zusammenführung von Daten aus unterschiedlichen Quellen und bietet so eine ganzheitliche Sicht auf den Betrieb.
- Wettbewerbsvorteil: Der schnelle Zugriff auf relevante Daten kann der Vorteil sein, den ein Unternehmen benötigt, um sich von der Konkurrenz abzuheben.
Arten der Datenextraktion
In der informationsintensiven Welt, in der wir leben, ist die Fähigkeit, Daten effizient aus einer Vielzahl von Quellen zu extrahieren, von unschätzbarem Wert. Datenextraktionsverfahren unterscheiden sich nicht nur in ihrer Methodik, sondern auch in ihrer Anwendung. Wenn Sie die Arten der Datenextraktion verstehen, können Sie die geeignete Technik für Ihre Datenanforderungen auswählen.
1. Manuelle Datenextraktion
Die manuelle Datenextraktion ist die einfachste Form und erfordert menschliche Eingaben, um Daten aus physischen oder digitalen Quellen zu sammeln. Diese Methode ist oft langsam und fehleranfällig, kann jedoch beim Umgang mit komplexen Informationen nützlich sein, die menschliches Urteilsvermögen erfordern.
2. Automatisierte Datenextraktion
Dieser Typ nutzt Software und Tools zur automatischen Erfassung und Verarbeitung von Daten, wodurch der Prozess erheblich beschleunigt und die Fehlerwahrscheinlichkeit verringert wird.
3. Web-Datenextraktion (Web Scraping)
Web Scraping ist eine Technik zum Extrahieren von Daten aus Websites. Dies geschieht durch Software, die das Surfen von Menschen im Internet nachahmt, um spezifische Informationen aus Online-Quellen zu sammeln.
4. Strukturierte Datenextraktion
Dieser Typ bezieht sich auf den Abruf von Daten, die in einem strukturierten Format wie Datenbanken oder Tabellenkalkulationen organisiert sind, wobei die Daten konsistent sind und einem bestimmten Schema folgen.
5. Extraktion unstrukturierter Daten
Bei der Extraktion unstrukturierter Daten handelt es sich um Daten, die keinem bestimmten Format oder keiner bestimmten Struktur folgen, wie z. B. E-Mails, PDFs oder Multimedia.
6. Halbstrukturierte Datenextraktion
Die halbstrukturierte Datenextraktion eignet sich für Daten, die sich nicht in einer relationalen Datenbank befinden, aber einige Organisationseigenschaften aufweisen, wodurch sie einfacher zu analysieren sind als unstrukturierte Daten.
7. Abfragebasierte Datenextraktion
Bei dieser Methode werden Abfragen verwendet, um Daten aus Datenbanken abzurufen. Es handelt sich um eine hocheffiziente Form der strukturierten Datenextraktion und kann den Informationsabruf in Echtzeit oder nach Zeitplan ermöglichen.
Datenextraktionstechniken
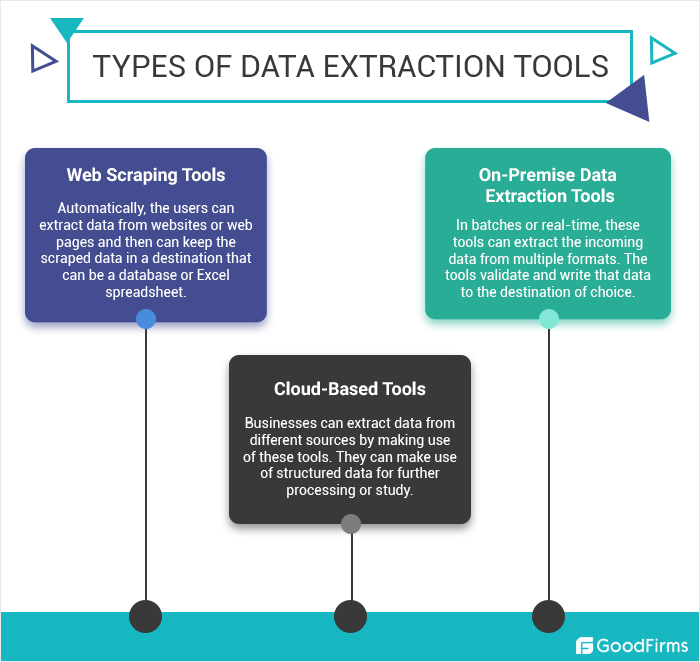
- Automatisierte Datenerfassung: Tools, die relevante Informationen automatisch aus Dokumenten oder Webseiten erkennen und extrahieren.
- Web Scraping: Verwendung von Software zur Simulation der menschlichen Erkundung des Webs, um bestimmte Daten zu sammeln.
- Textanalyse: Einsatz natürlicher Sprachverarbeitung, um Informationen aus unstrukturiertem Text zu extrahieren.
- ETL-Prozesse: Die Abkürzung steht für Extract, Transform, Load. Hierbei handelt es sich um integrierte Systeme, die Daten aus verschiedenen Quellen abrufen, in ein nützliches Format konvertieren und in einem Data Warehouse speichern.
Best Practices für eine effektive Datenextraktion
- Definieren Sie klare Ziele: Informieren Sie sich darüber, was Sie für Ihre Datenextraktionsbemühungen benötigen, um die richtigen Tools und Methoden auszuwählen.
- Stellen Sie die Datenqualität sicher: Validieren und bereinigen Sie Ihre Daten im Rahmen des Extraktionsprozesses, um die Integrität zu wahren.
- Bleiben Sie konform: Beachten Sie die Datenschutzgesetze und -vorschriften, um sicherzustellen, dass Ihre Datenextraktionsmethoden legal sind.
- Skalierbarkeit: Wählen Sie Lösungen, die mit Ihren Datenanforderungen wachsen können, um zukünftige Überarbeitungen zu vermeiden.
Herausforderungen bei der Datenextraktion
Die Datenextraktion ist zwar von unschätzbarem Wert, stellt jedoch eine Vielzahl von Herausforderungen dar, die den Prozess sowohl für Unternehmen als auch für Einzelpersonen erschweren können. Diese Herausforderungen können sich auf die Qualität, Geschwindigkeit und Effizienz datengesteuerter Initiativen auswirken. Im Folgenden gehen wir auf einige der häufigsten Hindernisse ein, die bei der Datenextraktion auftreten.

- Probleme mit der Datenqualität:
- Inkonsistente Daten: Das Extrahieren von Daten aus verschiedenen Quellen bedeutet häufig den Umgang mit Inkonsistenzen in Format, Struktur und Qualität, die zu ungenauen Datensätzen führen können.
- Unvollständige Daten: Fehlende Werte oder unvollständige Datensätze während der Extraktion können die Analyseergebnisse verfälschen.
- Duplikate: Bei der Extraktion können redundante Daten auftreten, die zu Ineffizienzen und verzerrten Analyseergebnissen führen.
- Bedenken hinsichtlich der Skalierbarkeit:
- Volumen: Da die Datenmengen wachsen, wird es immer schwieriger, Informationen zeitnah und effizient zu extrahieren, ohne die Systemleistung zu beeinträchtigen.
- Sich weiterentwickelnde Daten: Die kontinuierliche Weiterentwicklung von Daten erfordert einen skalierbaren Extraktionsprozess, der sich an Änderungen anpassen kann, ohne dass umfangreiche Neukonfigurationen erforderlich sind.
- Komplexe und vielfältige Datenquellen:
- Vielfalt: Das Extrahieren von Daten aus einer Vielzahl von Quellen mit unterschiedlichen Formaten (PDFs, Webseiten, Datenbanken usw.) erfordert vielseitige und ausgefeilte Extraktionstools.
- Zugänglichkeit: Der Zugriff und die Extraktion von Daten, die in Altsystemen oder in proprietären Formaten gesperrt sind, können besonders schwierig sein.
- Technische Einschränkungen:
- Integrationsschwierigkeiten: Die Integration extrahierter Daten in bestehende Systeme kann technische Herausforderungen mit sich bringen, insbesondere wenn es um unterschiedliche Technologien oder veraltete Infrastruktur geht.
- Mangel an Fachwissen: Die für eine effiziente Datenextraktion erforderlichen Tools und Techniken sind oft mit einer steilen Lernkurve verbunden, die Spezialwissen erfordert.
- Rechts- und Compliance-Fragen:
- Datenschutzbestimmungen: Die Einhaltung strenger Datenschutzgesetze wie DSGVO oder HIPAA kann den Extraktionsprozess erschweren, da für bestimmte Daten möglicherweise zusätzliche Verarbeitungsprotokolle erforderlich sind.
- Geistiges Eigentum: Beim Extrahieren von Daten aus externen Quellen besteht das Risiko einer Verletzung geistiger Eigentumsrechte, was zu rechtlichen Komplikationen führen kann.
- Datenextraktion in Echtzeit:
- Latenz: In bestimmten Bereichen wie Finanzen oder Sicherheit, in denen Latenz erhebliche Auswirkungen auf die Entscheidungsfindung haben kann, besteht ein wachsender Bedarf an Echtzeit-Datenextraktion.
- Infrastruktur: Die Datenextraktion in Echtzeit erfordert eine robuste Infrastruktur, die kontinuierliche Datenflüsse ohne Engpässe bewältigen kann.
- Datentransformation:
- Formatkonvertierung: Extrahierte Daten müssen zur Analyse häufig in ein anderes Format umgewandelt werden, was ein komplexer und fehleranfälliger Prozess sein kann.
- Kontextbewahrung: Sicherzustellen, dass Daten nach der Extraktion und Transformation ihre Bedeutung behalten, ist von entscheidender Bedeutung, aber auch eine Herausforderung, insbesondere beim Umgang mit unstrukturierten Daten.
- Sicherheitsbedenken:
- Datenschutzverletzungen: Beim Extrahieren sensibler oder vertraulicher Informationen besteht immer das Risiko von Datenschutzverletzungen, was strenge Sicherheitsmaßnahmen erfordert.
- Datenbeschädigung: Daten können während der Extraktion aufgrund von Softwarefehlern, Kompatibilitätsproblemen oder Hardwarefehlern beschädigt werden.
Abschluss
Als Lebensader des Datenanalyseprozesses kann die Datenextraktion entmutigend wirken, aber mit dem richtigen Ansatz wird sie zu einem Katalysator für Erkenntnisse und Chancen. Durch das Verständnis der Prinzipien und den Einsatz aktueller Technologien kann jedes Unternehmen das volle Potenzial seiner Daten ausschöpfen.