
Was ist Data Labeling beim maschinellen Lernen und wie funktioniert es?
Veröffentlicht: 2022-04-29Daten sind der neue Reichtum für Unternehmen von heute. Da Technologien wie künstliche Intelligenz nach und nach die meisten unserer täglichen Aktivitäten übernehmen, hat die richtige Nutzung aller Daten die Gesellschaft positiv beeinflusst. Durch die effiziente Trennung und Kennzeichnung von Daten können ML-Algorithmen die Probleme erkennen und praktische und relevante Lösungen bereitstellen.
Mithilfe der Datenkennzeichnung bringen wir der Maschine verschiedene Techniken bei und geben die Informationen in verschiedenen Formaten ein, damit sie sich „smart“ verhalten. Die Wissenschaft hinter der Datenkennzeichnung beinhaltet eine ganze Menge Hausaufgaben in Form der Kommentierung oder Kennzeichnung der Datensätze mit mehreren Variationen derselben Informationen. Obwohl das Endergebnis überrascht und unser tägliches Leben erleichtert, ist die Arbeit dahinter immens und die Hingabe lobenswert.
Was ist Datenkennzeichnung?
Beim maschinellen Lernen bestimmen die Qualität und Art der Eingabedaten die Qualität und Art der Ausgabe. Die Qualität der zum Trainieren der Maschine verwendeten Daten erhöht die Genauigkeit Ihres KI-Modells.
Mit anderen Worten, die Datenkennzeichnung ist ein Prozess, bei dem eine Maschine trainiert wird, die Unterschiede und Ähnlichkeiten zwischen den unstrukturierten oder strukturierten Datensätzen zu finden, indem sie gekennzeichnet oder kommentiert werden.
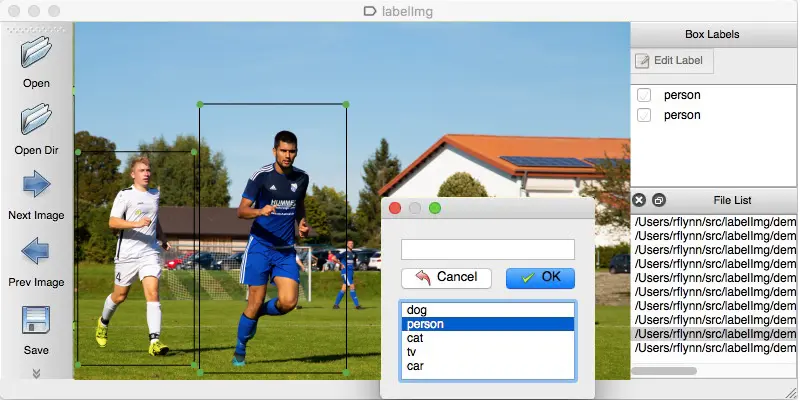
Lassen Sie uns dies anhand eines Beispiels verstehen. Um der Maschine beizubringen, dass rotes Licht das Stoppzeichen ist, müssen Sie alle roten Lichter in verschiedenen Bildern markieren, damit die Maschine das Signal versteht. Basierend darauf erstellt die KI einen Algorithmus, der die rote Ampel in jedem gegebenen Szenario als Stoppsignal interpretiert. Ein weiteres Beispiel ist, dass Musikgenres mit mehreren Datensätzen unter den Labels Jazz, Pop, Rock, Klassik und mehr getrennt werden können.
Herausforderungen bei der Datenkennzeichnung
Alle neuen Änderungen/Fortschritte in Technologie oder Struktur bringen Vorteile und Herausforderungen mit sich. Bei der Datenkennzeichnung ist das nicht anders. Während die Datenkennzeichnung die Zeit für die Skalierung eines Unternehmens drastisch verkürzen kann , ist sie mit Kosten verbunden. Lassen Sie uns auf einige der Herausforderungen eingehen, die die Datenkennzeichnung mit sich bringt.
Kosten in Bezug auf Zeit und Aufwand
Es ist an sich schon eine herausfordernde Aufgabe, die nischenspezifischen Daten in riesigen Mengen zu erhalten. Das manuelle Hinzufügen von Tags für jeden Artikel trägt nur zu der ohnehin schon zeitaufwändigen Aufgabe bei. Wenn das Projekt intern bearbeitet wird, wird die meiste Projektzeit für datenbezogene Aufgaben wie das Sammeln, Aufbereiten und Kennzeichnen von Daten aufgewendet.
Um diese Aufgaben effektiv zu bewältigen und die Arbeit auf Anhieb richtig zu machen, benötigen Sie erfahrene Etikettierer mit diesem spezifischen Fachwissen. Auch das ist ein teures Unterfangen, das nicht nur zeitlich, sondern auch finanziell kostspielig wird.
Inkonsistenz
Annotatoren mit unterschiedlichem Fachwissen können unterschiedliche Kennzeichnungskriterien haben. Folglich besteht eine hohe Wahrscheinlichkeit einer inkonsistenten Kennzeichnung. Wenn mehrere Personen denselben Datensatz beschriften, sind die Datengenauigkeitsraten jedoch viel höher.
Domain-Know-how
Für bestimmte Branchen werden Sie die Notwendigkeit verspüren, Etikettierer mit spezifischem Fachwissen einzustellen. Um beispielsweise eine ML-App für die Gesundheitsbranche zu erstellen , wird es für Kommentatoren ohne einschlägige Fachkenntnisse sehr schwierig sein, die Elemente korrekt zu taggen.
Mängel
Jede sich wiederholende Arbeit, die von Menschen ausgeführt wird, ist fehleranfällig. Welches Fachwissen der menschliche Etikettierer auch haben mag, manuelles Etikettieren wird immer den Bereich der Unvollkommenheit aufweisen. Null Fehler zu gewährleisten ist so gut wie unmöglich, da die Kommentatoren mit großen Sätzen von Rohdaten für die Kennzeichnung umgehen müssen.
Ansätze zur Datenkennzeichnung
Wie oben erwähnt, ist die Datenkennzeichnung eine zeitaufwändige Aufgabe, die ein Auge fürs Detail erfordert. Basierend auf der Problemstellung, der Menge der zu markierenden Daten, der Komplexität der Daten und dem Stil variiert die Strategie, die zum Annotieren von Daten angewendet wird.
Sehen wir uns verschiedene Ansätze an, für die sich Ihr Unternehmen basierend auf den finanziellen Ressourcen und der verfügbaren Zeit entscheiden kann.
Eigene Datenkennzeichnung
Basierend auf dem Branchentyp, der verfügbaren Zeit zum Abschluss des jeweiligen KI-Projekts und der Verfügbarkeit der erforderlichen Ressourcen kann der Datenkennzeichnungsprozess von den Organisationen intern durchgeführt werden.
Vorteile:
- Hohe Genauigkeit
- Hohe Qualität
- Vereinfachte Verfolgung
Nachteile:
- Zeitaufwändig/langsam
- Erfordern umfangreiche Ressourcen
Crowdsourcing
Sourcing-Datensätze, die von Freiberuflern gelabelt werden, sind auf verschiedenen Crowdsourcing-Plattformen verfügbar. Diese Methode kann zum Kommentieren verallgemeinerter Daten wie Bilder verwendet werden.
Das bekannteste Beispiel für die Datenkennzeichnung durch Crowdsourcing ist Recaptcha. Der Benutzer wird aufgefordert, bestimmte Arten von Bildern zu identifizieren, um zu beweisen, dass es sich um Menschen handelt. Diese werden anhand der Eingaben anderer Nutzer verifiziert. Dies fungiert als Datenbank mit Etiketten für eine Reihe von Bildern.
Vorteile:
- Schnell und einfach
- Kosteneffizient
Nachteile:
- Kann nicht für Daten verwendet werden, die Fachkenntnisse erfordern
- Qualität wird nicht garantiert
Auslagerung
Outsourcing kann als Mittelweg zwischen interner Datenkennzeichnung und Crowdsourcing fungieren. Die Beauftragung von Drittorganisationen oder Einzelpersonen mit Fachkenntnissen kann Organisationen bei allen – langfristigen und kurzfristigen Projekten – helfen.
Vorteile:
- Optimal für temporäre Projekte auf hohem Niveau
- Outsourcing-Unternehmen von Drittanbietern stellen geprüftes Personal zur Verfügung
- Bietet sowohl vorgefertigte als auch benutzerdefinierte Tools zur Datenkennzeichnung gemäß Ihren Geschäftsanforderungen
- Kann die Option von Experten für nischenspezifische Datenkennzeichnung erhalten
Nachteile:
- Die Verwaltung des Drittanbieters kann zeitaufwändig sein
Maschinenbasiert
Eine der neuesten Formen der Datenkennzeichnung und -anmerkung, die in der Industrie weit verbreitet und akzeptiert ist, ist die maschinenbasierte Annotation. Die Automatisierung des Datenkennzeichnungsprozesses mithilfe von Datenkennzeichnungssoftware reduziert menschliche Eingriffe und erhöht die Geschwindigkeit, mit der die Kennzeichnung erfolgen kann. Mit der als aktives Lernen bezeichneten Technik können Daten mit Tags versehen werden, auf deren Grundlage die Tags automatisch zu Trainingsdatensätzen hinzugefügt werden können.
Vorteile:
- Schnellere Datenverarbeitung und Etikettierung
- Beinhaltet weniger menschliche Eingriffe
Nachteile:
- Obwohl bessere Qualität, aber nicht auf Augenhöhe mit menschlichem Tagging
- Im Fehlerfall ist dennoch menschliches Eingreifen erforderlich

Wie funktioniert die Datenkennzeichnung?
Basierend auf Ihren geschäftlichen Anforderungen können Sie den Ansatz wählen, der Ihren Anforderungen am besten entspricht. Der Datenkennzeichnungsprozess funktioniert jedoch chronologisch in der folgenden Reihenfolge.
Datensammlung
Die Basis jedes maschinellen Lernprojekts sind Daten. Das Sammeln der richtigen Menge an Rohdaten in verschiedenen Formaten ist der erste Schritt der Datenkennzeichnung. Die Erfassung von Daten kann auf zwei Arten erfolgen – eine, die das Unternehmen intern erfasst hat, und die andere, die aus externen, öffentlich zugänglichen Quellen erfasst wird.
Da diese Daten in Rohform vorliegen, müssen sie bereinigt und verarbeitet werden, bevor die Etiketten für die Datensätze erstellt werden. Diese bereinigten und vorverarbeiteten Daten werden dann dem Modell zum Training zugeführt. Je größer und diversifizierter die Daten sind, desto genauer sind die Ergebnisse.

Datenanmerkung
Sobald die Daten bereinigt sind, gehen die Domänenexperten die Daten durch und fügen Labels hinzu, indem sie verschiedenen Datenlabeling-Ansätzen folgen. Dem Modell wird der aussagekräftige Kontext beigefügt, der als Ground Truth verwendet werden kann. Dies sind die Zielvariablen wie Bilder, die das Modell vorhersagen soll.
Qualitätssicherung
Der Erfolg des ML-Modelltrainings hängt stark von der Qualität der Daten ab, die zuverlässig, genau und konsistent sein sollten. Um diese präzisen und genauen Datenetiketten zu gewährleisten, müssen regelmäßige QA-Kontrollen durchgeführt werden. Mithilfe von QA-Algorithmen wie dem Consensus und Cronbachs Alpha-Test kann die Genauigkeit dieser Annotationen bestimmt werden. Regelmäßige QS-Kontrollen tragen wesentlich zur Genauigkeit der Ergebnisse bei.
Modelltraining und -test
Die Durchführung aller oben genannten Schritte ist nur sinnvoll, wenn die Daten auf Richtigkeit geprüft werden. Die Eingabe des unstrukturierten Datensatzes, um zu sehen, ob er die erwarteten Ergebnisse liefert, testet den Prozess.
Branchenspezifische Anwendungsfälle für die Datenkennzeichnung
Nachdem wir nun wissen, was Data Labeling ist und wie es funktioniert, wollen wir uns die wichtigsten Anwendungsfälle ansehen.
Computer Vision (Lebenslauf)
Dies ist eine Teilmenge der KI, die es den Maschinen ermöglicht, aus den Eingaben in Form von Bildern und Videos (zum Taggen extrahierte Standbilder) eine sinnvolle Interpretation abzuleiten.
Computer Vision Annotation kann in verschiedenen Branchen verwendet werden, um die praktischen Vorteile von KI zu implementieren.
- In der Automobilindustrie wird die Kennzeichnung von Bildern und Videos zur Segmentierung von Straßen, Gebäuden, Fußgängern und anderen Objekten autonomen Fahrzeugen helfen, zwischen diesen Einheiten zu unterscheiden, um einen Kontakt im wirklichen Leben zu vermeiden.
- In der Gesundheitsbranche können Krankheitssymptome in einem Röntgen-, MRT- und CT-Scan segmentiert werden. Mit Hilfe mikroskopischer Bilder lassen sich die meisten kritischen Erkrankungen frühzeitig diagnostizieren.
- QR-Codes, Label-Barcodes usw. können als Etiketten in der Transport- und Logistikbranche zur Warenverfolgung verwendet werden.
Verarbeitung natürlicher Sprache (NLP)
Dies ist eine Teilmenge, die es KI-Maschinen ermöglicht, menschliche Sprache und Statistiken zu interpretieren. Durch die Ableitung von Bedeutung aus Text und Sprache kann der Algorithmus verschiedene sprachliche Aspekte analysieren.
NLP wird zunehmend in vielen Unternehmenslösungen eingesetzt .
- Es wird in allen Branchen häufig als E-Mail-Assistent, Autovervollständigungsfunktion, Rechtschreibprüfung, Trennung von Spam- und Nicht-Spam-E-Mails und vielem mehr verwendet.
- In Form von Chatbots werden die grundlegenden Anfragen der Kunden ohne menschliches Zutun in Echtzeit interpretiert und beantwortet. Es wird prognostiziert, dass bis zum Jahr 2023 70 % der Kundeninteraktionen von Chatbots und mobilen Messaging-Anwendungen verwaltet werden.
- Das Verständnis der negativen und positiven Polarität des Textes zur Erfassung der Kundenstimmung wird durch Datenkennzeichnung im E-Commerce erreicht.
Appinventiv hat erfolgreich eine Social-Media-App für Vyrb entwickelt , die es Benutzern ermöglicht, für Bluetooth-Wearables optimierte Audionachrichten zu senden und zu empfangen.

Überblick über den KI-Datenkennzeichnungsmarkt
Die Datenkennzeichnung ist eine florierende Branche, die aus der KI-Technologie hervorgegangen ist . Da die Datenkennzeichnung weitgehend davon abhängt, dass genaue Daten dem maschinellen Lernen zugeführt werden, wird sie in den nächsten Jahren zwangsläufig wachsen.
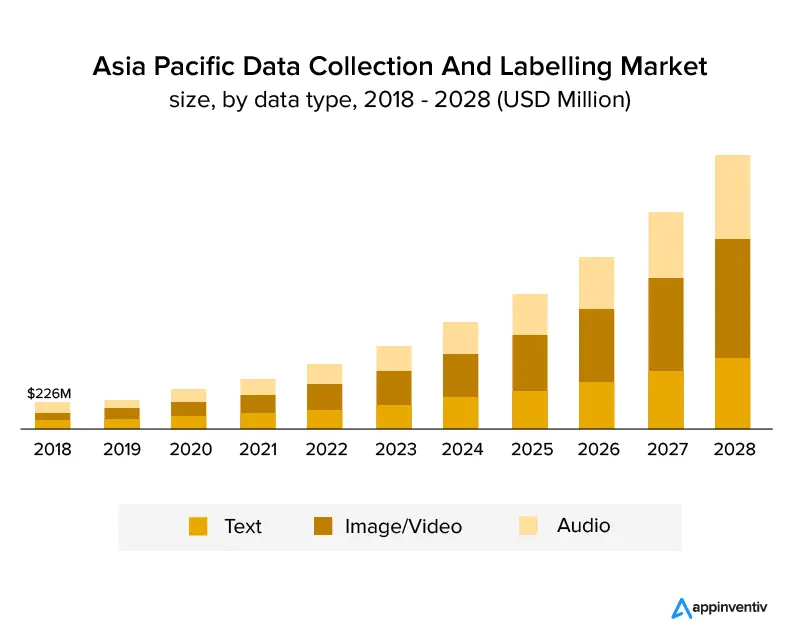
Die folgende Grafik zeigt deutlich, dass die Branche gewachsen ist und in den kommenden Jahren weiter wachsen wird. Es wird erwartet, dass es mit einem durchschnittlichen jährlichen Wachstum von 25,6 % wachsen und bis 2028 eine Marktgröße von 8,22 Milliarden USD erreichen wird. Die folgende Grafik zeigt das Wachstum nach Datentyp.
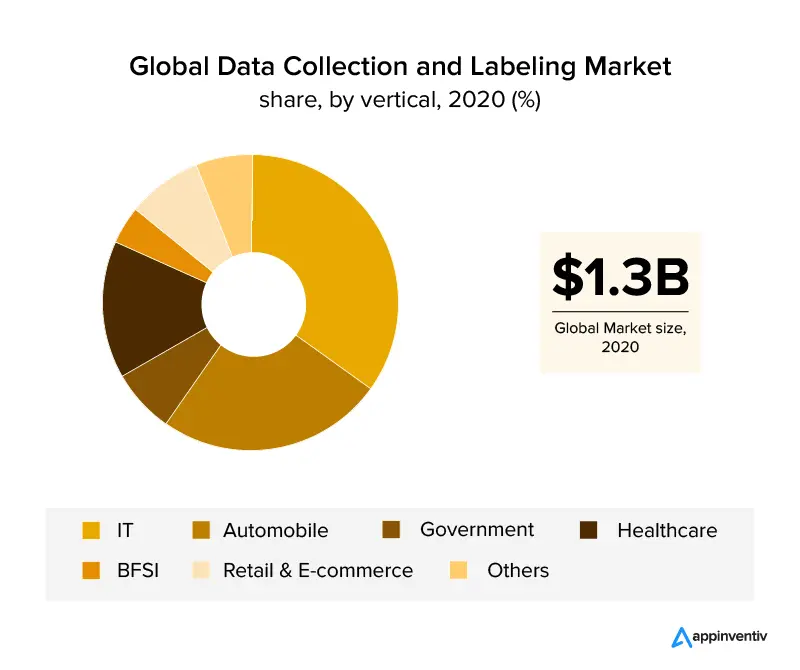
Ein Überblick über die Branchen, die Data Labeling genutzt haben, ist die IT- und Automobilbranche, die einen Anteil von über 30 % am weltweiten Umsatz ausmacht. Mit dem Wachstum der Gesundheitsbranche wird erwartet, dass die Datenkennzeichnung aufgrund der genauen Datenanforderungen für effiziente KI-basierte Anwendungen in diesem Sektor boomen wird. Mit Hilfe der Bildkennzeichnung haben sich auch der Einzelhandel und die E-Commerce-Branche einen bedeutenden Marktanteil in der Datenkennzeichnungsbranche gesichert.
Daten mit Appinventiv kennzeichnen
Aus strategischer Sicht haben Unternehmen Datenerfassungs- und Kennzeichnungsdienste ausgelagert, um starke Modelle für maschinelles Lernen zu erstellen.
Appinventiv ist ein KI- und ML-Entwicklungsunternehmen , das Organisationen seit vielen Jahren dabei unterstützt, Möglichkeiten mit KI-gesteuerten Lösungen zu erschließen . Mit fast einem Jahrzehnt Erfahrung in der Transformation von Unternehmen haben wir viele komplexe KI-Projekte für verschiedene Branchen erfolgreich durchgeführt.
Beispielsweise hat Appinventiv den Bankprozess für eine führende Bank in Europa erfolgreich automatisiert . Der Automatisierungsprozess half der Bank, die Genauigkeit um 50 % und das Serviceniveau der Geldautomaten um 92 % zu verbessern.
Ein weiteres Beispiel, bei dem Appinventiv YouCOMM beim Aufbau einer revolutionären Lösung zur Transformation der Patientenkommunikation im Krankenhaus geholfen hat, indem es Echtzeitzugriff auf medizinische Hilfe bietet. Mit einem anpassbaren Patientennachrichtensystem können Patienten das Personal einfach über Sprachbefehle und die Verwendung von Kopfgesten über ihre Bedürfnisse informieren.
Mit unserem Fachwissen und unserem kundenorientierten Team bieten wir die Datenkennzeichnungsdienste, die Ihnen helfen, die Herausforderungen zu meistern, indem wir Ihnen ganzheitliche Datenkennzeichnungsdienste basierend auf Ihren spezifischen Bedürfnissen und Anforderungen anbieten.
Durch die Nutzung der Vielzahl von Tools, die für das Tagging und die Datenanmerkung erforderlich sind, kann Appinventiv Ihre Datentrainingsprozesse verbessern, um komplexe Modelle zu vereinfachen. Dies ermöglicht es uns, in Bezug auf die Genauigkeit der Segmentierung, Klassifizierung und anschließenden Datenkennzeichnung schnell und einfach zu übertreffen.
Abschluss!
„Die Macht der künstlichen Intelligenz ist so unglaublich, dass sie die Gesellschaft auf sehr tiefgreifende Weise verändern wird.“ - Bill Gates
Künstliche Intelligenz hat das Potenzial, das Leben der Menschen zu erleichtern und damit der Gesellschaft Gutes zu tun. Seine Fähigkeit, riesige Datenmengen mit Hilfe von Data Labeling in aussagekräftige Anweisungen zu sortieren, hat der Industrie geholfen, voranzukommen und sprunghaft zu wachsen.
FAQ
F. Was sind die Best Practices für eine perfekte Datenkennzeichnung?
A. Basierend auf dem Ansatz, den Sie für die Datenkennzeichnung verfolgen, gibt es einige Best Practices, die Sie befolgen können:
- Stellen Sie sicher, dass die gesammelten Daten angemessen, ordnungsgemäß bereinigt und verarbeitet sind.
- Weisen Sie den Job basierend auf der Branche nur Domänenexperten für Datenbeschriftungen zu.
- Stellen Sie sicher, dass das Team einen einheitlichen Ansatz verfolgt, indem Sie ihm die zu befolgenden Kriterien für die Annotationstechniken zur Verfügung stellen.
- Folgen Sie einem Maker-Checker-Prozess, indem Sie mehrere Annotatoren für Cross-Labeling zuweisen.
F. Welche Vorteile hat die Datenkennzeichnung?
A. Die Datenkennzeichnung trägt dazu bei, den Kontext, die Qualität und die Benutzerfreundlichkeit besser zu verdeutlichen, um eine genaue Vorhersage der Daten zu treffen. Dies wiederum trägt dazu bei, die Datenverwendbarkeit von Variablen im Modell zu verbessern.
F. Was sind die verschiedenen Elemente, die bei der Auswahl von Unternehmen für Datenkennzeichnung zu berücksichtigen sind?
A. Bei der Auswahl der Datenlabeldienste für maschinelles Lernen sind fünf Parameter zu berücksichtigen.
- Skalierbarkeit des Datenkennzeichnungsprozesses
- Kosten für den Datenbeschriftungsdienst
- Datensicherheit
- Plattform für die Datenkennzeichnung