
Was ist Robots.txt in SEO: Wie man es erstellt und optimiert
Veröffentlicht: 2022-04-22Das heutige Thema steht nicht in direktem Zusammenhang mit der Traffic-Monetarisierung. Die robots.txt-Datei kann sich jedoch auf die SEO Ihrer Website und schließlich auf die Menge des erhaltenen Datenverkehrs auswirken. Viele Web-Admins haben das Ranking ihrer Websites durch verpfuschte robots.txt-Einträge ruiniert. Dieser Leitfaden hilft Ihnen, all diese Fallstricke zu vermeiden. Unbedingt bis zum Ende lesen!
- Was ist eine robots.txt-Datei?
- Wie sieht eine robots.txt-Datei aus?
- So finden Sie Ihre robots.txt-Datei
- Wie funktioniert eine Robots.txt-Datei?
- Robots.txt-Syntax
- Unterstützte Direktiven
- User-Agent*
- Erlauben
- Nicht zulassen
- Seitenverzeichnis
- Nicht unterstützte Anweisungen
- Crawl-Verzögerung
- Kein Index
- Nicht folgen
- Benötigen Sie eine robots.txt-Datei?
- Erstellen einer robots.txt-Datei
- Robots.txt-Datei: Best Practices für SEO
- Verwenden Sie für jede Anweisung eine neue Zeile
- Verwenden Sie Platzhalter, um Anweisungen zu vereinfachen
- Verwenden Sie das Dollarzeichen „$“, um das Ende einer URL anzugeben
- Verwenden Sie jeden User-Agent nur einmal
- Verwenden Sie spezifische Anweisungen, um unbeabsichtigte Fehler zu vermeiden
- Geben Sie Kommentare mit einem Hash in die robots.txt-Datei ein
- Verwenden Sie für jede Subdomain unterschiedliche robots.txt-Dateien
- Blockieren Sie keine guten Inhalte
- Überbeanspruchen Sie die Crawl-Verzögerung nicht
- Achten Sie auf Groß- und Kleinschreibung
- Weitere Best Practices:
- Verwenden von robots.txt zum Verhindern der Indexierung von Inhalten
- Verwendung von robots.txt zum Schutz privater Inhalte
- Verwendung von robots.txt zum Verstecken bösartiger doppelter Inhalte
- All-Access für alle Bots
- Kein Zugriff für alle Bots
- Blockieren Sie ein Unterverzeichnis für alle Bots
- Ein Unterverzeichnis für alle Bots sperren (mit einer erlaubten Datei)
- Blockieren Sie eine Datei für alle Bots
- Blockieren Sie einen Dateityp (PDF) für alle Bots
- Blockieren Sie alle parametrisierten URLs nur für den Googlebot
- So testen Sie Ihre robots.txt-Datei auf Fehler
- Eingesendete URL durch robots.txt blockiert
- Blockiert durch robots.txt
- Indiziert, obwohl von robots.txt blockiert
- Robots.txt vs. Meta-Roboter vs. X-Roboter
- Weiterlesen
- Einpacken
Was ist eine robots.txt-Datei?
Die robots.txt oder Robot Exclusion Protocol ist eine Reihe von Webstandards, die steuern, wie Suchmaschinen-Robots jede Webseite durchsuchen, bis hin zu den Schema-Markups auf dieser Seite. Es handelt sich um eine Standard-Textdatei, die sogar verhindern kann, dass Webcrawler Zugriff auf Ihre gesamte Website oder Teile davon erhalten.
Während Sie SEO anpassen und technische Probleme lösen, können Sie damit beginnen, passives Einkommen aus Anzeigen zu erzielen. Eine einzige Codezeile auf Ihrer Website gibt regelmäßige Auszahlungen zurück!
Zum Inhaltsverzeichnis ↑Wie sieht eine robots.txt-Datei aus?
Die Syntax ist einfach: Sie geben Bots Regeln, indem Sie ihren Benutzeragenten und ihre Anweisungen angeben. Die Datei hat folgendes Grundformat:
Sitemap: [URL-Speicherort der Sitemap]
User-Agent: [Bot-ID]
[Richtlinie 1]
[Richtlinie 2]
[Richtlinie …]
User-Agent: [eine andere Bot-Kennung]
[Richtlinie 1]
[Richtlinie 2]
[Richtlinie …]
So finden Sie Ihre robots.txt-Datei
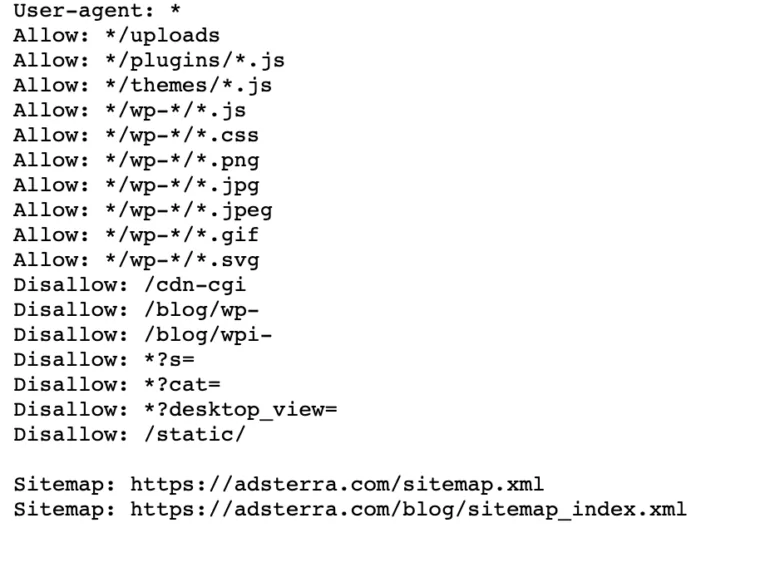
Wenn Ihre Website bereits über eine robot.txt-Datei verfügt, können Sie sie finden, indem Sie in Ihrem Browser zu dieser URL gehen: https://yourdomainname.com/robots.txt . Hier ist zum Beispiel unsere Datei
Wie funktioniert eine Robots.txt-Datei?
Eine robots.txt-Datei ist eine einfache Textdatei, die keinen HTML-Markup-Code enthält (daher die Erweiterung .txt). Diese Datei wird, wie alle anderen Dateien auf der Website, auf dem Webserver gespeichert. Es ist unwahrscheinlich, dass Benutzer diese Seite besuchen, da sie mit keiner Ihrer Seiten verlinkt ist, aber die meisten Web-Crawler-Bots suchen danach, bevor sie die gesamte Website durchsuchen.
Eine robots.txt-Datei kann Bots Anweisungen geben, diese Anweisungen jedoch nicht erzwingen. Ein guter Bot, z. B. ein Webcrawler oder ein Newsfeed-Bot, prüft die Datei und befolgt die Anweisungen, bevor er eine Domain-Seite besucht. Aber böswillige Bots werden die Datei entweder ignorieren oder verarbeiten, um verbotene Webseiten zu finden.
In einer Situation, in der eine robots.txt-Datei widersprüchliche Befehle enthält, verwendet der Bot die spezifischsten Anweisungen.
Zum Inhaltsverzeichnis ↑Robots.txt-Syntax
Eine robots.txt-Datei besteht aus mehreren Abschnitten von „Anweisungen“, die jeweils mit einem Benutzeragenten beginnen. Der User-Agent gibt den Crawl-Bot an, mit dem der Code kommuniziert. Sie können entweder alle Suchmaschinen auf einmal ansprechen oder einzelne Suchmaschinen verwalten.
Immer wenn ein Bot eine Website durchsucht, wirkt er auf die Teile der Website ein, die ihn aufrufen.
User-Agent: *
Nicht zulassen: /
User-Agent: Googlebot
Nicht zulassen:
Benutzeragent: Bingbot
Nicht zulassen: /not-for-bing/
Unterstützte Direktiven
Direktiven sind Richtlinien, die die von Ihnen deklarierten Benutzeragenten befolgen sollen. Google unterstützt derzeit die folgenden Richtlinien.
User-Agent*
Wenn ein Programm eine Verbindung zu einem Webserver (einem Roboter oder einem normalen Webbrowser) herstellt, sendet es einen HTTP-Header namens „User-Agent“, der grundlegende Informationen über seine Identität enthält. Jede Suchmaschine hat einen User-Agent. Die Roboter von Google sind als Googlebot bekannt, die von Yahoo – als Slurp und die von Bing – als BingBot. Der Benutzeragent initiiert eine Folge von Anweisungen, die für bestimmte Benutzeragenten oder alle Benutzeragenten gelten können.
Erlauben
Die Allow-Direktive weist Suchmaschinen an, eine Seite oder ein Unterverzeichnis zu crawlen, sogar ein eingeschränktes Verzeichnis. Wenn Sie beispielsweise möchten, dass Suchmaschinen nicht auf alle Posts Ihres Blogs bis auf einen zugreifen können, könnte Ihre robots.txt-Datei so aussehen:
User-Agent: *
Nicht zulassen: /blog
Erlauben: /blog/allowed-post
Suchmaschinen können jedoch auf /blog/allowed-post zugreifen, aber sie können keinen Zugriff erhalten auf:
/blog/anderer-beitrag
/blog/noch-ein-anderer-beitrag
/blog/download-me.pd
Nicht zulassen
Die Disallow-Anweisung (die der robots.txt-Datei einer Website hinzugefügt wird) weist Suchmaschinen an, eine bestimmte Seite nicht zu crawlen. In den meisten Fällen verhindert dies auch, dass eine Seite in den Suchergebnissen erscheint.
Sie können diese Anweisung verwenden, um Suchmaschinen anzuweisen, Dateien und Seiten in einem bestimmten Ordner, den Sie vor der Öffentlichkeit verbergen, nicht zu crawlen. Zum Beispiel Inhalte, an denen Sie noch arbeiten, aber versehentlich veröffentlicht wurden. Ihre robots.txt-Datei könnte so aussehen, wenn Sie verhindern möchten, dass alle Suchmaschinen auf Ihr Blog zugreifen:
User-Agent: *
Nicht zulassen: /blog
Das bedeutet, dass auch alle Unterverzeichnisse des /blog-Verzeichnisses nicht gecrawlt werden. Dies würde Google auch daran hindern, auf URLs zuzugreifen, die /blog enthalten.
Zum Inhaltsverzeichnis ↑Seitenverzeichnis
Sitemaps sind eine Liste von Seiten, die von Suchmaschinen gecrawlt und indexiert werden sollen. Wenn Sie die Sitemap-Direktive verwenden, kennen Suchmaschinen den Speicherort Ihrer XML-Sitemap. Die beste Option besteht darin, sie an die Webmaster-Tools der Suchmaschinen zu senden, da jedes wertvolle Informationen über Ihre Website für Besucher bereitstellen kann.
Es ist wichtig zu beachten, dass das Wiederholen der Sitemap-Anweisung für jeden Benutzeragenten unnötig ist und nicht für einen Suchagenten gilt. Fügen Sie Ihre Sitemap-Anweisungen am Anfang oder Ende Ihrer robots.txt-Datei hinzu.
Ein Beispiel für eine Sitemap-Direktive in der Datei:
Sitemap: https://www.domain.com/sitemap.xml
User-Agent: Googlebot
Nicht zulassen: /blog/
Erlauben: /blog/post-title/
Benutzeragent: Bingbot
Nicht zulassen: /services/
Zum Inhaltsverzeichnis ↑Nicht unterstützte Anweisungen
Die folgenden Richtlinien werden von Google nicht mehr unterstützt – einige davon wurden technisch nie unterstützt.
Crawl-Verzögerung
Yahoo, Bing und Yandex reagieren schnell auf die Indexierung von Websites und reagieren auf die Crawl-Delay-Direktive, die sie für eine Weile in Schach hält.
Wenden Sie diese Zeile auf Ihren Block an:
Benutzeragent: Bingbot
Kriechverzögerung: 10
Das bedeutet, dass die Suchmaschinen zehn Sekunden warten können, bevor sie die Website crawlen, oder zehn Sekunden, bevor sie nach dem Crawlen erneut auf die Website zugreifen, was dasselbe ist, aber je nach verwendetem User-Agent leicht unterschiedlich ist.
Kein Index
Das noindex-Meta-Tag ist eine großartige Möglichkeit, Suchmaschinen daran zu hindern, eine Ihrer Seiten zu indizieren. Das Tag ermöglicht Bots den Zugriff auf die Webseiten, weist Roboter aber auch an, sie nicht zu indizieren.
- HTTP-Antwortheader mit noindex-Tag. Sie können dieses Tag auf zwei Arten implementieren: einen HTTP-Antwort-Header mit einem X-Robots-Tag oder ein <meta>-Tag innerhalb des <head>-Abschnitts. So sollte Ihr <meta>-Tag aussehen:
<meta name=“robots“ content=“noindex“>
- 404 & 410 HTTP-Statuscode. Die Statuscodes 404 und 410 zeigen an, dass eine Seite nicht mehr verfügbar ist. Nach dem Crawlen und Verarbeiten von 404/410-Seiten werden sie automatisch aus dem Google-Index entfernt. Um das Risiko von 404- und 410-Fehlerseiten zu verringern, crawlen Sie Ihre Website regelmäßig und verwenden Sie 301-Weiterleitungen, um den Datenverkehr bei Bedarf auf eine vorhandene Seite zu leiten.
Nicht folgen
Nofollow weist Suchmaschinen an, Links auf Seiten und Dateien unter einem bestimmten Pfad nicht zu folgen. Seit dem 1. März 2020 betrachtet Google nofollow-Attribute nicht mehr als Anweisungen. Stattdessen handelt es sich um Hinweise, ähnlich wie bei kanonischen Tags. Wenn Sie ein „nofollow“-Attribut für alle Links auf einer Seite wünschen, verwenden Sie das Meta-Tag des Robots, den x-robots-Header oder das rel= „nofollow“ -Link-Attribut.
Bisher konnten Sie die folgende Anweisung verwenden, um Google daran zu hindern, allen Links in Ihrem Blog zu folgen:
User-Agent: Googlebot
Nicht folgen: /blog/
Benötigen Sie eine robots.txt-Datei?
Viele weniger komplexe Websites benötigen keine. Obwohl Google Webseiten, die durch die robots.txt-Datei blockiert werden, normalerweise nicht indiziert, kann nicht garantiert werden, dass diese Seiten nicht in den Suchergebnissen erscheinen. Mit dieser Datei haben Sie mehr Kontrolle und Sicherheit über den Inhalt Ihrer Website gegenüber Suchmaschinen.
Robots-Dateien helfen Ihnen auch dabei, Folgendes zu erreichen:
- Verhindern Sie, dass doppelte Inhalte gecrawlt werden.
- Bewahren Sie die Privatsphäre für verschiedene Website-Bereiche.
- Beschränken Sie das Crawlen von internen Suchergebnissen.
- Serverüberlastung verhindern.
- Vermeiden Sie „Crawl-Budget“-Verschwendung.
- Halten Sie Bilder, Videos und Ressourcendateien aus den Google-Suchergebnissen fern.
Diese Maßnahmen wirken sich letztendlich auf Ihre SEO-Taktik aus. Zum Beispiel verwirrt doppelter Inhalt Suchmaschinen und zwingt sie, zu entscheiden, welche von zwei Seiten zuerst gerankt werden soll. Unabhängig davon, wer den Inhalt erstellt hat, darf Google die Originalseite nicht für die Top-Suchergebnisse auswählen.

In Fällen, in denen Google doppelte Inhalte erkennt, die darauf abzielen, Benutzer zu täuschen oder Rankings zu manipulieren, passen sie die Indexierung und das Ranking Ihrer Website an. Infolgedessen kann das Ranking Ihrer Website darunter leiden oder vollständig aus dem Google-Index entfernt werden und aus den Suchergebnissen verschwinden.
Die Wahrung der Privatsphäre für verschiedene Website-Bereiche verbessert auch die Sicherheit Ihrer Website und schützt sie vor Hackern. Langfristig machen diese Maßnahmen Ihre Website sicherer, vertrauenswürdiger und rentabler.
Sind Sie ein Website-Besitzer, der vom Traffic profitieren möchte? Mit Adsterra erhalten Sie passives Einkommen von jeder Website!
Zum Inhaltsverzeichnis ↑Erstellen einer robots.txt-Datei
Sie benötigen einen Texteditor wie Notepad.
- Erstellen Sie ein neues Blatt, speichern Sie die leere Seite als „robots.txt“ und beginnen Sie mit der Eingabe von Anweisungen in das leere .txt-Dokument.
- Melden Sie sich bei Ihrem cPanel an, navigieren Sie zum Stammverzeichnis der Website und suchen Sie nach dem Ordner public_html .
- Ziehen Sie Ihre Datei in diesen Ordner und überprüfen Sie dann, ob die Berechtigung der Datei richtig eingestellt ist.
Sie können die Datei als Eigentümer schreiben, lesen und bearbeiten, aber Dritte sind nicht zugelassen. In der Datei sollte ein Berechtigungscode „0644“ erscheinen. Wenn nicht, klicken Sie mit der rechten Maustaste auf die Datei und wählen Sie „Dateiberechtigung“.
Robots.txt-Datei: Best Practices für SEO
Verwenden Sie für jede Anweisung eine neue Zeile
Sie müssen jede Direktive in einer separaten Zeile deklarieren. Sonst werden Suchmaschinen verwirrt.
User-Agent: *
Nicht zulassen: /Verzeichnis/
Nicht zulassen: /anderes-verzeichnis/
Verwenden Sie Platzhalter, um Anweisungen zu vereinfachen
Sie können Platzhalter (*) für alle Benutzeragenten verwenden und URL-Muster abgleichen, wenn Sie Anweisungen deklarieren. Platzhalter eignen sich gut für URLs mit einem einheitlichen Muster. Beispielsweise möchten Sie möglicherweise verhindern, dass alle Filterseiten mit einem Fragezeichen (?) in ihren URLs gecrawlt werden.
User-Agent: *
Nicht zulassen: /*?
Verwenden Sie das Dollarzeichen „$“, um das Ende einer URL anzugeben
Suchmaschinen können nicht auf URLs zugreifen, die auf Erweiterungen wie .pdf enden. Das bedeutet, dass sie nicht auf /file.pdf zugreifen können, aber sie können auf /file.pdf?id=68937586 zugreifen, das nicht auf „.pdf“ endet. Wenn Sie beispielsweise verhindern möchten, dass Suchmaschinen auf alle PDF-Dateien auf Ihrer Website zugreifen, könnte Ihre robots.txt-Datei so aussehen:
User-Agent: *
Nicht zulassen: /*.pdf$
Verwenden Sie jeden User-Agent nur einmal
Bei Google spielt es keine Rolle, ob Sie denselben User-Agent mehr als einmal verwenden. Es wird einfach alle Regeln aus den verschiedenen Erklärungen in einer einzigen Richtlinie zusammenfassen und ihr folgen. Es ist jedoch sinnvoll, jeden Benutzeragenten nur einmal zu deklarieren, da dies weniger verwirrend ist.
Wenn Sie Ihre Anweisungen sauber und einfach halten, verringert sich das Risiko kritischer Fehler. Zum Beispiel, wenn Ihre robots.txt-Datei die folgenden Benutzeragenten und Anweisungen enthält.
User-Agent: Googlebot
Nicht zulassen: /a/
User-Agent: Googlebot
Nicht zulassen: /b/
Verwenden Sie spezifische Anweisungen, um unbeabsichtigte Fehler zu vermeiden
Wenn Sie Anweisungen festlegen, kann das Fehlen spezifischer Anweisungen zu Fehlern führen, die Ihrer SEO schaden können. Angenommen, Sie haben eine mehrsprachige Site und arbeiten an einer deutschen Version für das Unterverzeichnis /de/.
Sie möchten nicht, dass Suchmaschinen darauf zugreifen können, da es noch nicht fertig ist. Die folgende robots.txt-Datei hindert Suchmaschinen daran, diesen Unterordner und seinen Inhalt zu indizieren:
User-Agent: *
Verbieten: /de
Es wird jedoch Suchmaschinen daran hindern, Seiten oder Dateien zu crawlen, die mit /de beginnen. In diesem Fall ist das Hinzufügen eines abschließenden Schrägstrichs die einfache Lösung.
User-Agent: *
Verbieten: /de/
Zum Inhaltsverzeichnis ↑Geben Sie Kommentare mit einem Hash in die robots.txt-Datei ein
Kommentare helfen Entwicklern und möglicherweise sogar Ihnen, Ihre robots.txt-Datei zu verstehen. Beginnen Sie die Zeile mit einem Hash (#), um einen Kommentar einzufügen. Crawler ignorieren Zeilen, die mit einem Hash beginnen.
# Dies weist den Bing-Bot an, unsere Website nicht zu crawlen.
Benutzeragent: Bingbot
Nicht zulassen: /
Verwenden Sie für jede Subdomain unterschiedliche robots.txt-Dateien
Robots.txt wirkt sich nur auf das Crawlen auf seiner Host-Domain aus. Sie benötigen eine weitere Datei, um das Crawlen auf eine andere Subdomain einzuschränken. Wenn Sie beispielsweise Ihre Haupt-Website auf example.com und Ihr Blog auf blog.example.com hosten, benötigen Sie zwei robots.txt-Dateien. Platzieren Sie eine im Stammverzeichnis der Hauptdomäne, während die andere Datei im Stammverzeichnis des Blogs liegen sollte.
Blockieren Sie keine guten Inhalte
Verwenden Sie keine robots.txt-Datei oder ein noindex-Tag, um hochwertige Inhalte zu blockieren, die Sie veröffentlichen möchten, um negative Auswirkungen auf die SEO-Ergebnisse zu vermeiden. Überprüfen Sie gründlich noindex-Tags und Disallow-Regeln auf Ihren Seiten.
Überbeanspruchen Sie die Crawl-Verzögerung nicht
Wir haben die Crawling-Verzögerung erklärt, aber Sie sollten sie nicht häufig verwenden, da sie Bots daran hindert, alle Seiten zu crawlen. Es mag für einige Websites funktionieren, aber Sie können Ihr Ranking und Ihren Traffic beeinträchtigen, wenn Sie eine große Website haben.
Achten Sie auf Groß- und Kleinschreibung
Bei der Datei „Robots.txt“ wird zwischen Groß- und Kleinschreibung unterschieden, daher müssen Sie sicherstellen, dass Sie eine Robots-Datei im richtigen Format erstellen. Die Robots-Datei sollte „robots.txt“ heißen und nur aus Kleinbuchstaben bestehen. Sonst geht es nicht.
Weitere Best Practices:
- Stellen Sie sicher, dass Sie das Crawlen von Inhalten oder Abschnitten Ihrer Website nicht blockieren.
- Verwenden Sie robots.txt nicht, um sensible Daten (private Benutzerinformationen) aus den SERP-Ergebnissen fernzuhalten. Verwenden Sie eine andere Methode, z. B. Datenverschlüsselung oder die Meta-Direktive noindex , um den Zugriff einzuschränken, wenn andere Seiten direkt auf die private Seite verlinken.
- Einige Suchmaschinen haben mehr als einen User-Agent. Google verwendet beispielsweise Googlebot für organische Suchen und Googlebot-Image für Bilder. Das Angeben von Anweisungen für die mehreren Crawler jeder Suchmaschine ist nicht erforderlich, da die meisten Benutzeragenten derselben Suchmaschine denselben Regeln folgen.
- Eine Suchmaschine speichert die robots.txt-Inhalte im Cache, aktualisiert sie jedoch täglich. Wenn Sie die Datei ändern und schneller aktualisieren möchten, können Sie die Datei-URL an Google senden.
Verwenden von robots.txt zum Verhindern der Indexierung von Inhalten
Das Deaktivieren einer Seite ist die effektivste Methode, um zu verhindern, dass Bots sie direkt crawlen. Es funktioniert jedoch nicht in den folgenden Situationen:
- Wenn eine andere Quelle Links zu der Seite hat, werden die Bots sie dennoch crawlen und indizieren.
- Illegitime Bots werden den Inhalt weiterhin crawlen und indizieren.
Verwendung von robots.txt zum Schutz privater Inhalte
Einige private Inhalte wie PDFs oder Dankesseiten können auch dann indexierbar sein, wenn Sie die Bots blockieren. Das Platzieren aller Ihrer exklusiven Seiten hinter einem Login ist eine der besten Möglichkeiten, die Disallow-Richtlinie zu stärken. Ihre Inhalte bleiben verfügbar, aber Ihre Besucher müssen einen zusätzlichen Schritt unternehmen, um darauf zuzugreifen.
Verwendung von robots.txt zum Verstecken bösartiger doppelter Inhalte
Duplicate Content ist entweder identisch oder sehr ähnlich zu anderen Inhalten in derselben Sprache. Google versucht, Seiten mit einzigartigem Inhalt zu indizieren und anzuzeigen. Wenn Ihre Website beispielsweise „normale“ und „Druck“-Versionen jedes Artikels hat und ein noindex-Tag keine davon blockiert, wird eine davon aufgelistet.
Beispiele für robots.txt-Dateien
Im Folgenden finden Sie einige Beispiele für robots.txt-Dateien. Diese sind in erster Linie für Ideen gedacht, aber wenn eine davon Ihren Anforderungen entspricht, kopieren Sie sie und fügen Sie sie in ein Textdokument ein, speichern Sie sie als „robots.txt“ und laden Sie sie in das richtige Verzeichnis hoch.
All-Access für alle Bots
Es gibt mehrere Möglichkeiten, Suchmaschinen anzuweisen, auf alle Dateien zuzugreifen, einschließlich einer leeren robots.txt-Datei oder keiner.
User-Agent: *
Nicht zulassen:
Kein Zugriff für alle Bots
Die folgende robots.txt-Datei weist alle Suchmaschinen an, den Zugriff auf die gesamte Website zu vermeiden:
User-Agent: *
Nicht zulassen: /
Blockieren Sie ein Unterverzeichnis für alle Bots
User-Agent: *
Nicht zulassen: /Ordner/
Ein Unterverzeichnis für alle Bots sperren (mit einer erlaubten Datei)
User-Agent: *
Nicht zulassen: /Ordner/
Zulassen: /Ordner/Seite.html
Blockieren Sie eine Datei für alle Bots
User-Agent: *
Nicht zulassen: /this-is-a-file.pdf
Blockieren Sie einen Dateityp (PDF) für alle Bots
User-Agent: *
Nicht zulassen: /*.pdf$
Blockieren Sie alle parametrisierten URLs nur für den Googlebot
User-Agent: Googlebot
Nicht zulassen: /*?
So testen Sie Ihre robots.txt-Datei auf Fehler
Fehler in Robots.txt können schwerwiegend sein, daher ist es wichtig, sie zu überwachen. Überprüfen Sie regelmäßig den Bericht „Coverage“ in der Search Console auf Probleme im Zusammenhang mit robot.txt. Einige der Fehler, auf die Sie stoßen könnten, was sie bedeuten und wie Sie sie beheben können, sind unten aufgeführt.
Eingesendete URL durch robots.txt blockiert
Es zeigt an, dass robots.txt mindestens eine der URLs in Ihrer/Ihren Sitemap(s) blockiert hat. Wenn Ihre Sitemap korrekt ist und keine kanonisierten, nicht indexierten oder umgeleiteten Seiten enthält, sollte robots.txt keine von Ihnen gesendeten Seiten blockieren. Wenn dies der Fall ist, identifizieren Sie die betroffenen Seiten und entfernen Sie die Blockierung aus Ihrer robots.txt-Datei.
Sie können den robots.txt-Tester von Google verwenden, um die Blockierungsrichtlinie zu identifizieren. Seien Sie vorsichtig, wenn Sie Ihre robots.txt-Datei bearbeiten, da sich ein Fehler auf andere Seiten oder Dateien auswirken kann.
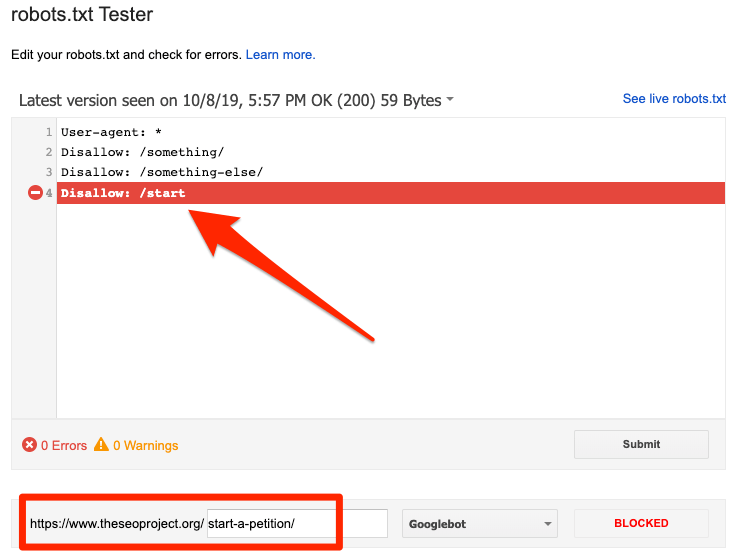
Blockiert durch robots.txt
Dieser Fehler weist darauf hin, dass robots.txt Inhalte blockiert hat, die Google nicht indexieren kann. Entfernen Sie den Crawl-Block in der robots.txt, wenn dieser Inhalt entscheidend ist und indiziert werden soll. (Überprüfen Sie außerdem, dass der Inhalt nicht noindexed ist.)
Wenn Sie Inhalte aus dem Index von Google ausschließen möchten, verwenden Sie ein Robot-Meta-Tag oder einen X-Robots-Header und entfernen Sie den Crawl-Block. Nur so können Inhalte aus dem Index von Google herausgehalten werden.
Indiziert, obwohl von robots.txt blockiert
Das bedeutet, dass Google immer noch einige der von robots.txt blockierten Inhalte indiziert. Robots.txt ist nicht die Lösung, um zu verhindern, dass Ihre Inhalte in den Google-Suchergebnissen angezeigt werden.
Um die Indexierung zu verhindern, entfernen Sie den Crawl-Block und ersetzen Sie ihn durch ein Meta-Robots-Tag oder einen x-robots-Tag-HTTP-Header. Wenn Sie diesen Inhalt versehentlich blockiert haben und möchten, dass Google ihn indexiert, entfernen Sie den Crawling-Block in robots.txt. Es kann dabei helfen, die Sichtbarkeit des Inhalts in der Google-Suche zu verbessern.
Robots.txt vs. Meta-Roboter vs. X-Roboter
Was unterscheidet diese drei Roboterbefehle? Robots.txt ist eine einfache Textdatei, während meta und x-robots Meta-Direktiven sind. Über ihre grundlegenden Rollen hinaus haben die drei unterschiedliche Funktionen. Robots.txt legt das Crawling-Verhalten für die gesamte Website oder das gesamte Verzeichnis fest, während Meta- und X-Robots das Indexierungsverhalten für einzelne Seiten (oder Seitenelemente) definieren.
Weiterlesen
Nützliche Ressourcen
- Wikipedia: Robots Exclusion Protocol
- Googles Dokumentation zu Robots.txt
- Bing (und Yahoo) Dokumentation zu Robots.txt
- Richtlinien erklärt
- Yandex-Dokumentation zu Robots.txt
Einpacken
Wir hoffen, dass Sie die Bedeutung der robot.txt-Datei und ihren Beitrag zu Ihrer gesamten SEO-Praxis und der Rentabilität Ihrer Website vollständig verstanden haben. Wenn Sie immer noch Schwierigkeiten haben, mit Ihrer Website Einnahmen zu erzielen, müssen Sie nicht programmieren, um mit Adsterra-Anzeigen Einnahmen zu erzielen. Platzieren Sie einen Anzeigencode auf Ihrer HTML-, WordPress- oder Blogger-Website und fangen Sie noch heute an, Gewinne zu erzielen!