
Welche Technologie verwenden Suchmaschinen zum Crawlen von Websites?
Veröffentlicht: 2023-03-02
Wenn Sie sich jemals gefragt haben, welche Technologie Suchmaschinen zum Crawlen von Websites verwenden, dann machen Sie sich bereit, endlich Antworten auf Ihre Fragen zu erhalten. Sie erfahren, was ein Webcrawler ist, welche vielen verschiedenen Arten von Webcrawlern von großen Suchmaschinen verwendet werden und worum es beim Suchindizierungsprozess geht. Außerdem erfahren Sie, wie sich all dies auf die Suchmaschinenergebnisse auswirkt und wie Websitebesitzer den Webcrawlern der Suchmaschinen mitteilen können, dass sie Inhalte nach ihren Wünschen indizieren sollen. Erfahren Sie mehr über diese Technologie, mit der Suchmaschinen Milliarden relevanter Suchergebnisse genau an Menschen liefern, die im World Wide Web nach Informationen suchen.
Was sind Webcrawler oder Suchmaschinen-Bots?
Webcrawler-Bots, auch Spider genannt, sind automatisierte Programme, mit denen Unternehmen wie Google und Microsoft ihren Suchmaschinen beibringen, was auf jeder zugänglichen Webseite jeder Website vorhanden ist, die sie im Internet finden können. Nur wenn diese Suchmaschinen erfahren, welche Informationen auf einer Webseite enthalten sind, können sie diese Informationen genau abrufen, wenn einer ihrer Benutzer eine Suchanfrage eingibt und nach Informationen zu einem bestimmten Thema fragt.
Die Arten von Web-Crawler-Bots
Jede Suchmaschine hat ihre Webcrawler. Hier sind einige der am häufigsten verwendeten.
GoogleBot
Google ist die beliebteste Suchmaschine der Welt und nutzt zwei Versionen von Webcrawlern, um Hunderte Milliarden Webseiten zu indizieren. Der GoogleBot Desktop untersucht Seiten, die das Verhalten einer Person nachahmen, die einen Desktop-Computer zum Surfen im Internet verwendet, während der GoogleBot Mobile dasselbe für Smartphone-Benutzer tut.
Der GoogleBot ist einer der effektivsten Such-Bot-Typen aller Zeiten und kann Webseiten schnell crawlen und indizieren. Es gibt jedoch einige Probleme beim Crawlen sehr komplexer Website-Strukturen. Darüber hinaus kann es oft viele Tage oder Wochen dauern, bis der GoogleBot eine neu veröffentlichte Webseite crawlt, was bedeutet, dass sie eine Zeit lang nicht in den relevanten Ergebnissen erscheint.
Bingbot
Der Bingbot ist Microsofts Antwort auf Googles eigene Suchmaschine Bing. Dies funktioniert ähnlich wie der Webcrawler von Google und beinhaltet sogar ein Abruftool, das angibt, wie der Bot eine Seite crawlen wird, sodass Sie sehen können, ob hier Probleme vorliegen.
Slurp Bot
Der Slurp Bot ist der von Yahoo verwendete Webcrawler, obwohl sie auch Bingbot verwenden, um ihre Suchmaschinenergebnisse bereitzustellen. Der Websitebesitzer muss dem Slurp Bot Zugriff gewähren, wenn der Inhalt seiner Webseite in den Suchergebnissen von Yahoo Mobile angezeigt werden soll. Darüber hinaus kann der Slurp Bot auch auf die Partnerseiten von Yahoo zugreifen, um Inhalte zu deren Websites Yahoo News, Yahoo Sports und Yahoo Finance hinzuzufügen.
DuckDuckBot
Dies ist der Webcrawler, der von DuckDuckGo verwendet wird, einer Suchmaschine, die dafür bekannt ist, ihren Nutzern ein unübertroffenes Maß an Privatsphäre zu bieten, indem sie ihre Aktivitäten nicht wie viele beliebte Suchmaschinen verfolgt. Sie stellen Suchergebnisse bereit, die sie von ihrem DuckDuckBot sowie von Crowdsourcing-Websites wie Wikipedia und anderen Suchmaschinen erhalten.
Baiduspider und Yandex Bot
Dies sind die Crawler-Bots, die von den Suchmaschinen Baidu aus China bzw. Yandex aus Russland verwendet werden. Baidu hat einen Anteil von über 80 % am Suchmaschinenmarkt auf dem chinesischen Festland.
Wie Web-Crawling, Suchindizierung und Suchmaschinen-Ranking funktionieren
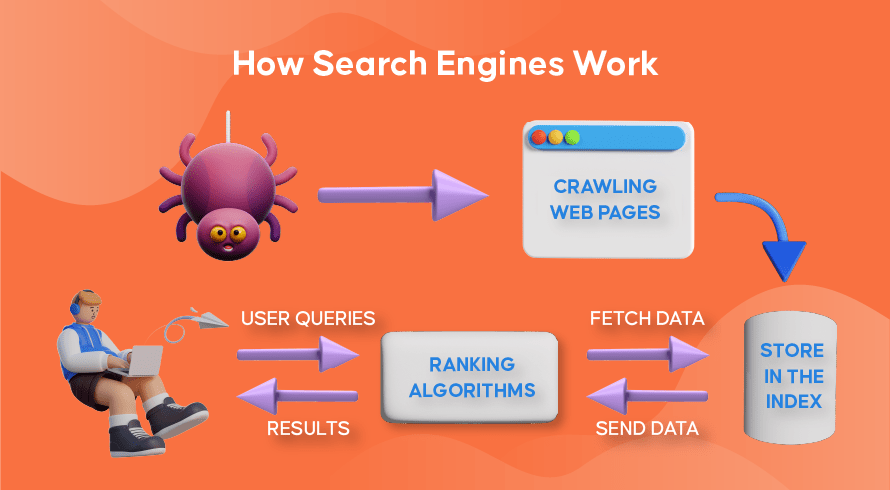
Lassen Sie uns nun untersuchen, wie die meisten Suchmaschinen Webcrawler verwenden, um auf Websites enthaltene Informationen zu finden, zu speichern, zu organisieren und abzurufen.
Wie Webcrawler funktionieren
Das Auffinden neuer und aktualisierter Inhalte auf Websites wird als „Webcrawlen“ bezeichnet, daher der Name der Softwareprogramme, die diese Funktion ausführen. Bots beginnen zunächst mit dem Crawlen einiger Webseiten, finden deren Inhalte und folgen dann den auf dieser Webseite enthaltenen Hyperlinks, um neue URLs zu entdecken, die zu noch mehr Inhalten führen.
So funktioniert die Suchmaschinenindizierung
Nachdem die Bots durch Web-Crawling neue oder aktualisierte Inhalte entdeckt haben, wird alles, was sie finden, einer riesigen Datenbank hinzugefügt, die als „Suchmaschinenindex“ bezeichnet wird. Dies ist wie eine Bibliothek, in der die Bücher wie Webseiten organisiert sind, damit sie später leicht abgerufen werden können. Enthält in jedem Buch den größten Teil des auf einer Webseite enthaltenen Textes, den wir sehen können (mit Ausnahme von Wörtern wie „ein“, „ein“ und „der“) sowie die Metadaten, die nur die Crawler sehen. Metadaten werden von Suchmaschinen verwendet, um den Inhalt einer Webseite zu verstehen. Der Metatitel und die Metabeschreibung sind Beispiele für Metadaten.
So funktioniert das Suchranking
Immer wenn ein Benutzer eine Suchanfrage eingibt, überprüft die jeweilige Suchmaschine ihren Index, findet die relevantesten Informationen, die dieser Anfrage entsprechen, organisiert die Liste der Weblinks, die den relevanten Inhalt enthalten, und präsentiert diese dem Benutzer in der Suchmaschine Ergebnisseiten (SERPs).
Diese Organisation der SERPs nennt sich „Suchranking“ und wird von einem Suchalgorithmus durchgeführt, der die gesammelten Daten einschließlich Metadaten, die Glaubwürdigkeit der Website (Autorität) sowie Schlüsselwörter und Links berücksichtigt. Websites, die als sehr glaubwürdige Quellen gelten und hochrelevante Inhalte enthalten, die für Benutzer nützlich sind, werden einen hohen Rang einnehmen und in den SERPs die besten Ergebnisse erzielen. Deshalb hat jeder Websitebesitzer Strategien, um seine Website in den SERPs zu platzieren.
Wie Suchmaschinenoptimierung (SEO) ins Spiel kommt
Websitebesitzer können den Inhalt ihrer Seiten so optimieren, dass Suchmaschinen ihn leichter als relevant und nützlich für ihre Benutzer erkennen. Dadurch werden diese Seiten an die Spitze der SERPs gebracht, was zu mehr organischem Traffic auf der Website führt. Die strategische Einbeziehung relevanter Schlüsselwörter in den Seitentext, der Linkaufbau und die Verwendung von Originalbildern und -videos sind einige der Einsatzmöglichkeiten von SEO-Techniken.
Darüber hinaus können Websites auch verschiedene Tools wie SEMrush verwenden, um verschiedene Probleme auf ihren Seiten wie defekte Links zu finden und zu beheben, was ihr Ranking in den Augen von Suchmaschinen weiter verbessert.

Sagen Sie Suchmaschinen, wie sie Ihre Website crawlen sollen

Manchmal werden Sie feststellen, dass die Webcrawler ihre Funktion nicht ausreichend erfüllt haben, was dazu führt, dass wichtige Seiten Ihrer Website im Index fehlen. Dies bedeutet, dass relevante Suchanfragen nicht mit Ihren Inhalten angezeigt werden, was es potenziellen Kunden erschwert, den Weg zu Ihren Seiten zu finden. Glücklicherweise gibt es Möglichkeiten, mit Suchmaschinen zu kommunizieren, sodass Sie ein wenig Kontrolle darüber haben, was indiziert und was ignoriert wird.
Die robots.txt-Datei, die im Stammverzeichnis Ihrer Website gespeichert ist, teilt den Webcrawlern mit, welche Seiten gecrawlt werden sollen, welche ignoriert werden sollen und wie die Architektur Ihrer Website aufgebaut ist. Möglicherweise möchten Sie verhindern, dass bestimmte Seiten indiziert werden, wenn sie zu Testzwecken oder für Sonderaktionen und doppelte URLs im E-Commerce verwendet werden.
GoogleBot crawlt beispielsweise eine Website weiterhin vollständig, auch wenn keine robots.txt-Datei vorhanden ist. Beim Erkennen Ihrer robots.txt-Datei folgt GoogleBot beim Crawlen Ihren Anweisungen. Wenn die Datei nicht erkannt wird oder ein Fehler auftritt, wird Ihre Website möglicherweise nicht gecrawlt. Sie müssen die robots.txt-Datei korrekt verwenden, die Architektur Ihrer Website organisieren und Best Practices für On-Page-SEO anwenden, um Probleme beim Crawlen zu vermeiden. Sie können ein Website-Audit durchführen, um alle Probleme zu analysieren und zu identifizieren, die Ihre Website plagen.
Benötigen Sie SEO-Dienste für Ihre Website?
Wenn Sie auf der Suche nach einem Dienstleister sind, der versteht, wie Webcrawler und Suchindizierung funktionieren, um das Ranking Ihrer Website zu verbessern, dann ist Inquivix der SEO-Partner, nach dem Sie gesucht haben. Wir bieten ein umfassendes Angebot an On-Page-SEO-Diensten von der Inhaltserstellung über die Optimierung der Website-Architektur bis hin zur Analyse der Website-Leistung, um die Qualität Ihres Website-Erlebnisses kontinuierlich zu verbessern. Um mehr zu erfahren, besuchen Sie noch heute Inquivix On-Page SEO Services!
FAQs
Suchmaschinen verwenden Programme namens „Webcrawler“, auch bekannt als „Spider“ oder „Bots“, um sowohl neue als auch aktualisierte Inhalte auf den Seiten einer Website zu entdecken. Anschließend folgt es den auf der Seite enthaltenen Links, um weitere Seiten zu finden. Der auf einer Seite gefundene Inhalt wird in einem Index gespeichert, der zum Abrufen von Informationen für Suchergebnisse verwendet wird, wenn ein Benutzer sie anfordert.
GoogleBot Desktop und GoogleBot Mobile sind in den meisten Ländern die beliebtesten Webcrawler, gefolgt von Bingbot, Slurp Bot und DuckDuckBot. Baiduspider wird hauptsächlich in China verwendet, während Yandex Bot in Russland verwendet wird.