
LLM スループットを向上させるための高度なテクニック
公開: 2024-04-02ペースの速いテクノロジーの世界では、大規模言語モデル (LLM) が、私たちがデジタル情報をどのように扱うかにおいて重要な役割を果たしています。 これらの強力なツールは、記事を書いたり、質問に答えたり、会話をしたりすることができますが、課題がないわけではありません。 これらのモデルにさらに多くのことを要求すると、特にモデルをより高速かつ効率的に動作させる場合に、ハードルにぶつかります。 このブログは、それらのハードルに真正面から取り組むことを目的としています。
私たちは、出力の品質を損なうことなく、これらのモデルの動作速度を向上させるために設計されたいくつかの賢い戦略を検討しています。 レースカーの速度を向上させながら、タイトなコーナーを完璧にナビゲートできるようにすることを想像してみてください。それが、私たちが大規模な言語モデルで目指していることです。 情報をよりスムーズに処理するのに役立つ連続バッチ処理などの手法や、LLM のデジタル推論をより注意深く、より迅速に行うためのページドやフラッシュ アテンションなどの革新的なアプローチを検討します。
したがって、これらの AI 巨人ができることの限界を押し上げることに興味があるなら、あなたは正しい場所にいます。 これらの高度な技術が LLM の未来をどのように形成し、LLM をこれまで以上に高速かつ優れたものにするのかを一緒に探ってみましょう。
LLM のより高いスループットを達成するための課題
大規模言語モデル (LLM) でより高いスループットを達成するには、いくつかの重大な課題に直面しており、それぞれがこれらのモデルの動作速度と効率に対するハードルとなっています。 主な障害の 1 つは、これらのモデルが扱う膨大な量のデータを処理および保存するために必要なメモリ要件が膨大であることです。 LLM の複雑さとサイズが増大するにつれて、計算リソースへの需要が増大し、処理速度の向上はおろか、維持することも困難になります。
もう 1 つの大きな課題は、特にテキストの生成に使用されるモデルにおける LLM の自己回帰的な性質です。 これは、各ステップの出力が前のステップの出力に依存していることを意味し、タスクの実行速度を本質的に制限する逐次処理要件が生じます。 各ステップは、先行するステップが完了するまで待たなければ続行できないため、この逐次的な依存関係がボトルネックになることが多く、より高いスループットを達成する取り組みが妨げられます。
さらに、精度と速度のバランスは微妙です。 出力の品質を損なうことなくスループットを向上させることは綱渡りであり、計算効率とモデルの有効性の複雑な状況を乗り切ることができる革新的なソリューションが必要です。
これらの課題は、LLM 最適化の進歩の背景を形成し、自然言語処理およびそれを超えた領域で可能なことの限界を押し広げます。
メモリ要件
デコード フェーズでは各タイム ステップで 1 つのトークンが生成されますが、各トークンは以前のすべてのトークン (プリフィル時に計算された入力トークンの KV テンソル、および現在のタイム ステップまでに計算された新しい KV テンソルを含む) のキー テンソルと値テンソルに依存します。 。
したがって、毎回の冗長な計算を最小限に抑え、各タイム ステップですべてのトークンのこれらすべてのテンソルを再計算することを避けるために、それらを GPU メモリにキャッシュすることが可能です。 反復ごとに、新しい要素が計算されると、それらは次の反復で使用されるために実行中のキャッシュに追加されるだけです。 これは本質的に KV キャッシュとして知られています。
これにより、必要な計算量が大幅に削減されますが、大規模な言語モデルではすでにより高いメモリ要件に加えて、メモリ要件も導入されるため、汎用 GPU での実行が困難になります。 モデル パラメーターのサイズが増加し (7B から 33B に)、精度が高くなる (fp16 から fp32) ため、メモリ要件も増加します。 必要なメモリ容量の例を見てみましょう。
ご存知のとおり、メモリを占有する主な要素は次の 2 つです。
- モデル自身の重みをメモリに保存することはできません。 7B などのパラメータと各パラメータのデータ型 (例: fp16 の 7B(2 バイト) ~= メモリ内 14GB)
- KV キャッシュ: 冗長な計算を避けるためにセルフ アテンション ステージのキー値に使用されるキャッシュ。
トークンごとの KV キャッシュのサイズ (バイト単位) = 2 * (num_layers) * (hidden_size) * precision_in_bytes
最初の因数 2 は、K 行列と V 行列を説明します。 これらの hidden_size と dim_head は、モデルのカードまたは構成ファイルから取得できます。
上記の式はトークンごとであるため、入力シーケンスの場合、seq_len * size_of_kv_per_token になります。 したがって、上記の式は次のように変形されます。
KV キャッシュの合計サイズ (バイト単位) = (sequence_length) * 2 * (num_layers) * (hidden_size) * precision_in_bytes
たとえば、fp16 の LLAMA 2 では、サイズは (4096) * 2 * (32) * (4096) * 2 となり、約 2GB になります。
上記は単一入力の場合であり、複数の入力では急速に増加するため、このオンフライトのメモリ割り当てと管理は、メモリ不足や断片化の問題が発生しない場合でも、最適なパフォーマンスを達成するための重要なステップになります。
場合によっては、メモリ要件が GPU の容量を超える場合があります。その場合、モデルの並列処理やテンソルの並列処理を検討する必要があります。これについてはここでは説明しませんが、その方向で検討することができます。
自動回帰性とメモリ制限のある操作
ご覧のとおり、大規模な言語モデルの出力生成部分は本質的に自己回帰的です。 は、新しいトークンが生成されることを示します。それは、以前のすべてのトークンとその中間状態に依存します。 出力ステージでは、すべてのトークンがさらなる計算に利用できるわけではなく、ベクトル (次のトークン用) と前のステージのブロックが 1 つしかないため、これは、GPU の計算能力を十分に活用しない行列ベクトル演算のようになります。プレフィルフェーズとの比較。 データ (重み、キー、値、アクティベーション) がメモリから GPU に転送される速度がレイテンシーを支配します。実際の計算速度ではありません。 言い換えれば、これはメモリに依存した操作です。
スループットの課題を克服する革新的なソリューション
連続バッチ処理
デコード ステージのメモリ制約を軽減するための非常に簡単な手順は、入力をバッチ処理し、複数の入力の計算を一度に実行することです。 しかし、単純な定数バッチ処理では、生成されるシーケンスの長さが異なるという性質により、パフォーマンスが低下します。ここで、バッチのレイテンシーは、バッチ内で生成される最長のシーケンスに依存し、また、複数の入力が行われるためメモリ要件の増大にも依存します。一気に処理されるようになりました。

したがって、単純な静的バッチ処理は効果がなく、継続的なバッチ処理が必要になります。 その本質は、受信リクエストのバッチを動的に集約し、変動する到着率に適応し、可能な限り並列処理の機会を活用することにあります。 これにより、同様の長さのシーケンスを各バッチにグループ化することでメモリ使用率も最適化され、短いシーケンスに必要なパディングの量が最小限に抑えられ、過剰なパディングによる計算リソースの浪費が回避されます。
現在のメモリ容量、計算リソース、入力シーケンスの長さなどの要素に基づいてバッチ サイズを適応的に調整します。 これにより、メモリ制約を超えることなく、さまざまな条件下でモデルが最適に動作することが保証されます。 これは、ページング アテンション (以下で説明) に役立ち、レイテンシを短縮し、スループットを向上させるのに役立ちます。
詳細: 連続バッチ処理により、p50 レイテンシを削減しながら LLM 推論で 23 倍のスループットを実現する方法
ページングされたアテンション
スループットを向上させるためにバッチ処理を行うと、同時に複数の入力を処理することになるため、KV キャッシュ メモリ要件が増加するという犠牲も伴います。 これらのシーケンスは利用可能な計算リソースのメモリ容量を超える可能性があり、その全体を処理することが非現実的になります。
また、KV キャッシュの単純なメモリ割り当てでは、メモリの不均等な割り当てが原因でコンピュータ システムで観察されるのと同じように、大量のメモリの断片化が発生することも観察されています。 vLLM は、KV キャッシュの増大する要件を効率的に処理するために、オペレーティング システムのページングと仮想メモリの概念からインスピレーションを得たメモリ管理技術であるページド アテンションを導入しました。
ページド アテンションは、アテンション メカニズムを小さなページまたはセグメントに分割し、それぞれが入力シーケンスのサブセットをカバーすることでメモリの制約に対処します。 入力シーケンス全体の注意スコアを一度に計算するのではなく、モデルは一度に 1 ページに焦点を当て、順次処理します。
推論またはトレーニング中に、モデルは入力シーケンスの各ページを反復処理し、注意スコアを計算し、それに応じて出力を生成します。 ページが処理されると、その結果が保存され、モデルは次のページに進みます。
ページド アテンションでは、アテンション メカニズムをページに分割することで、大規模言語モデルがメモリ制約を超えることなく任意の長さの入力シーケンスを処理できるようになります。 長いシーケンスの処理に必要なメモリ フットプリントが効果的に削減され、大規模なドキュメントやバッチの処理が可能になります。
詳細: vLLM と PagedAttendant を使用した高速 LLM サービス
フラッシュアテンション
アテンション メカニズムは、大規模言語モデルのベースとなるトランスフォーマー モデルにとって重要であるため、モデルが予測を行うときに入力テキストの関連部分に焦点を当てるのに役立ちます。 ただし、トランスフォーマーベースのモデルが大規模かつ複雑になるにつれて、セルフアテンション メカニズムはますます遅くなり、メモリを大量に消費するようになり、前述したようにメモリ ボトルネックの問題が発生します。 フラッシュ アテンションは、アテンション操作を最適化することでこの問題を軽減することを目的としたもう 1 つの最適化手法であり、より高速なトレーニングと推論を可能にします。
フラッシュ アテンションの主な特徴:
カーネル フュージョン: GPU のコンピューティング使用量を最大化するだけでなく、可能な限り効率的な操作を行うことが重要です。 Flash アテンションは、複数の計算ステップを 1 つの操作に結合し、反復的なデータ転送の必要性を減らします。 この合理化されたアプローチにより、実装プロセスが簡素化され、計算効率が向上します。
タイリング: Flash アテンションは、ロードされたデータを小さなブロックに分割し、並列処理を支援します。 この戦略によりメモリ使用量が最適化され、入力サイズが大きいモデルに対してスケーラブルなソリューションが可能になります。
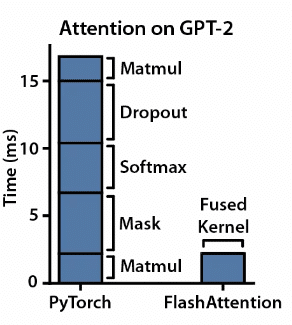
(タイル化と融合によって計算に必要な時間がどのように短縮されるかを示す融合された CUDA カーネル、画像ソース: FlashAttend: IO-Awareness を使用した高速でメモリ効率の高い正確なアテンション)
メモリの最適化: Flash アテンションは、最近計算されたトークンからのアクティベーションを再利用し、過去のいくつかのトークンのパラメーターのみを読み込みます。 このスライディング ウィンドウ アプローチにより、重みをロードするための IO リクエストの数が減り、フラッシュ メモリのスループットが最大化されます。
データ転送の削減: フラッシュ アテンションは、高帯域幅メモリ (HBM) や SRAM (スタティック ランダム アクセス メモリ) などのメモリ タイプ間の往復のデータ転送を最小限に抑えます。 すべてのデータ (クエリ、キー、値) を 1 回だけロードすることで、反復的なデータ転送のオーバーヘッドが軽減されます。
ケーススタディ – 投機的デコードによる推論の最適化
自己回帰言語モデルでテキスト生成を促進するために使用されるもう 1 つの方法は、投機的デコードです。 投機的デコードの主な目的は、生成されたテキストの品質をターゲット配布の品質と同等のレベルに保ちながら、テキストの生成を高速化することです。
投機的デコードでは、シーケンス内の後続のトークンを予測する小規模/ドラフト モデルが導入され、事前定義された基準に基づいてメイン モデルによって受け入れ/拒否されます。 より小さいドラフト モデルをターゲット モデルと統合すると、テキスト生成の速度が大幅に向上します。これはメモリ要件の性質によるものです。 ドラフトモデルは小さいため、必要な数は少なくなります。 ロードされるニューロンの重みとその数。 メイン モデルと比較して計算量も減り、これによりレイテンシが短縮され、出力生成プロセスが高速化されます。 次に、メイン モデルは生成された結果を評価し、それが次に考えられるトークンのターゲット分布内に収まることを確認します。
基本的に、投機的デコードは、後続のトークンを予測するためにより小型で迅速なドラフト モデルを活用することでテキスト生成プロセスを合理化し、それにより、生成されたコンテンツの品質をターゲット配布に近い状態に維持しながら、テキスト生成の全体的な速度を加速します。
小規模なモデルによって生成されたトークンが常に常に拒否されるわけではないことが非常に重要です。この場合、パフォーマンスの向上ではなくパフォーマンスの低下につながります。 実験とユースケースの性質を通じて、より小さなモデルを選択したり、推論プロセスに推測的なデコーディングを導入したりできます。
結論
大規模言語モデル (LLM) のスループットを向上させるための高度な技術を通じた旅は、自然言語処理の領域における今後の道筋を明らかにし、課題だけでなく、課題に正面から対処できる革新的なソリューションを示します。 連続バッチ処理からページ化およびフラッシュ アテンションに至るこれらの技術、および投機的デコードの興味深いアプローチは、単なる段階的な改善以上のものです。 これらは、大規模な言語モデルをより高速かつ効率的に作成し、最終的には幅広いアプリケーションでよりアクセスしやすくするという私たちの能力における大きな進歩を表しています。
これらの進歩の重要性は、どれだけ強調してもしすぎることはありません。 LLM スループットの最適化とパフォーマンスの向上において、私たちはこれらの強力なモデルのエンジンを調整するだけではありません。 私たちは処理速度と効率の観点から何が可能かを再定義しています。 これにより、会話の速度で動作できるリアルタイム言語翻訳サービスから、前例のない速度で膨大なデータセットを処理できる高度な分析ツールに至るまで、大規模言語モデルのアプリケーションに新たな地平が開かれます。
さらに、これらの手法は、大規模な言語モデルの最適化に対するバランスの取れたアプローチ、つまり速度、精度、計算リソースの間の相互作用を慎重に考慮するアプローチの重要性を強調しています。 LLM 機能の限界を押し上げる中で、これらのモデルが無数の業界にわたって多用途で信頼性の高いツールとして機能し続けるためには、このバランスを維持することが重要になります。
大規模言語モデルのスループットを向上させるための高度な技術は、単なる技術的な成果ではありません。 それらは、人工知能の継続的な進化におけるマイルストーンです。 これらは、LLM をより適応性、効率性、強力なものにし、デジタル環境を変革し続ける将来のイノベーションへの道を開くことを約束します。
大規模言語モデルの推論最適化のための GPU アーキテクチャの詳細については、最近のブログ投稿をご覧ください。