
バザールの声
公開: 2024-04-24レガシーシステムの最新化に関するこの記事は、機械学習プロジェクトの成功を確実にするためのベストプラクティスを活用してデータから価値を生み出すことについて、ソフトウェア企業向けの AWS Data Summit で私が最近発表した講演の補足です。 必要に応じて、ここで一番下までジャンプして視聴することができます。
正直に言って、ソフトウェアは保守するよりも書く方が簡単です。 これが、ソフトウェア エンジニアである私たちが、他の開発者 (または過去の自分) が何を考えていたかを理解しようとするのではなく、単に「それを取り除いてやり直す」ことを好む理由です。 私たちは、「プログラムは人が読めるように書かれなければならず、たまたま機械が実行できるように書かれなければならない」ということを忘れているようです。
ご存知の通り、それは真実です。私たちは皆、スパゲッティ コードと薄い旧世界スタイルの抽象概念の入ったキャセロールを苦労してトレースしてプログラムの核心を掘り起こし、結局皿の底に散らかったものしか見つけられなかったことがあるでしょう。
「なんてことだ」と叫び、前の開発者を責めるのは簡単ですが、真実はもっと複雑であることがよくあります。 私たちには未来が見えないため、まったく新しいシステムを設計するときに、要件、テクノロジー、またはビジネス目標がどのように成長するかを理解することは不可能です。 その結果、ビジネスの依存度が高まるにつれてシステムの範囲が拡大し、システムが判読できなくなる可能性があります。 これは少し矛盾しています。多くの場合、古くて保守が難しいシステムが最大の価値を提供します。 会社とともに成長してきたものなので、取り組むのは難しく、それを壊すと大惨事になる可能性があるため、取り組むのは怖いです。
ここで私はあなたに呼びかけています: 難しくてやりがいのある問題が好きなら、ぜひ試してみてください。 所有している最も古いシステムを保守しやすいものにしましょう。 私が話しているのはご存知の通り、誰も「所有」しないものです。 他の部門は頼りにしているが、エンジニアは嫌がります。 最初に Log4Shell にパッチを適用する必要があったもの。 やれ。 出来ることならどうぞ。
最近、Bazaarvoice で 10 年前の機械学習システムを更新する機会がありました。 表面的には、面白くないように思えました。これにはニューラル ネットワークさえありませんでした。 誰が気にする! まあ…それは重要でした。 このシステムは、Bazaarvoice が受け取るほぼすべてのユーザー作成の製品レビュー (毎月約 900 万件) を処理し、機械学習モデルへの 9,000 万件の推論呼び出しを使用して処理します。 そう、9,000 万通りの推論です! とてもスケールが大きくて、飛び込むのが待ちきれませんでした。
この投稿では、このレガシー システムを書き直すのではなく再アーキテクチャによって最新化することで、コードをすべて削除して最初からやり直すことなく、システムをスケーラブルでコスト効率の高いものにすることができた方法を紹介します。 結果として得られるシステムはサーバーレスでコンテナ化されており、保守可能でありながら、ホスティング コストを 80% 近く削減します。
レガシーシステムとは何ですか?
レガシー システムとは、動作し続けている老朽化したコンピューティング ソフトウェアおよび/またはハードウェアを指します。 当初の目的はまだ果たせるかもしれませんが、将来の成長に向けた拡張性に欠けています。
古いレガシーシステム
まず、ここで扱う内容を見てみましょう。 私のチームが更新していたレガシー システムは、すべての Bazaarvoice のユーザー生成コンテンツを管理します。 具体的には、各コンテンツがクライアントの Web サイトに適切であるかどうかを判断します。

ヘイトスピーチ、汚い言葉、勧誘などの明らかな違反行為を排除する、というと単純そうに聞こえますが、実際にはもっと微妙です。 各クライアントは、何が適切であると考えるかについて独自の要件を持っています。 たとえば、ビール ブランドではアルコールに関する議論が期待されますが、子供向けブランドではそうではない可能性があります。 新しいクライアントをオンボーディングするときに、これらのクライアント固有のオプションを取得し、クライアント サービス チームがそれらを管理データベースにエンコードします。
複雑さをさらに高めるために、人間のモデレーターによってモデレートされるコンテンツのサブセットもサンプリングします。 これにより、モデルのパフォーマンスを継続的に測定し、より多くのモデルを構築する機会を見つけることができます。
従来のシステムの完全なアーキテクチャを以下に示します。
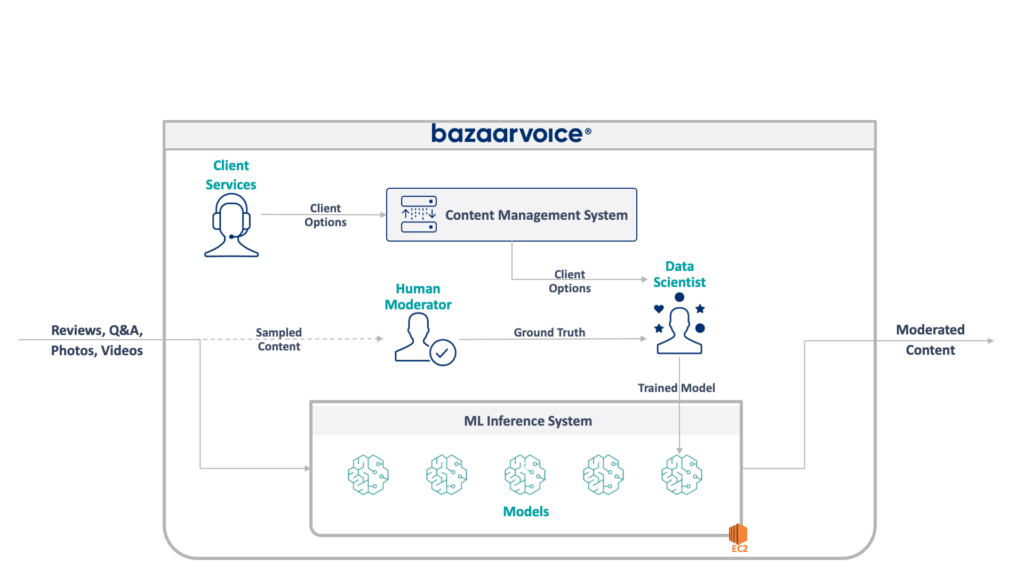
このシステムにはいくつかの重大な欠点があります。 具体的には、すべてのモデルが単一の EC2 インスタンスでホストされています。 これはエンジニアリングが悪いためではなく、元のプログラマーが会社が望む規模を予測できなかっただけです。 ここまで成長するとは誰も思っていませんでした。
さらに、このシステムは開発者の拒否反応にも悩まされました。それは Scala で書かれており、それを理解できるエンジニアはほとんどいませんでした。 したがって、誰も触ろうとしなかったため、改善が見落とされることがよくありました。
その結果、システムは継続的に成長を続けました。 再構築に着手すると、単一の x1e.8xlarge インスタンス上で実行されるようになりました。 この製品には 1 テラバイト近くの RAM が搭載されており、運用には月額約 5,000 ドル (予約なし) がかかります。 ただし、心配しないでください。冗長性を確保するために 2 つ目、QA を目的として 3 つ目を立ち上げたばかりです。
このシステムは運用コストが高く、障害のリスクが高かった (単一の不良モデルがサービス全体をダウンさせる可能性がある)。 さらに、コード ベースは積極的に開発されていなかったため、最新のデータ サイエンス パッケージからすると大幅に時代遅れであり、Scala で記述されたサービスの標準プラクティスに従っていませんでした。
新しいシステム
このシステムを再設計するとき、私たちはスケーラブルにするという明確な目標を掲げました。 運用コストの削減は、モデルとコードの管理を容易にすることと同様に、二次的な目標でした。
私たちが思いついた新しいデザインを以下に示します。

これらすべてを解決するための私たちのアプローチは、各機械学習モデルを分離された SageMaker Serverless エンドポイントに配置することでした。 AWS Lambda 関数と同様に、サーバーレス エンドポイントは使用されていないときはオフになるため、使用頻度の低いモデルのランタイム コストが節約されます。 また、トラフィックの増加に応じて迅速にスケールアウトできます。

さらに、コンテンツを適切なモデルにルーティングする単一のマイクロサービスにクライアント オプションを公開しました。 これが、私たちが書かなければならなかった新しいコードの大部分でした。これは、メンテナンスが簡単で、データ サイエンティストが新しいモデルをより簡単に更新してデプロイできるようにする小さな API でした。
このアプローチには次の利点があります。
- 評価までの時間を 6 倍以上短縮しました。 具体的には、既存のモデルへのトラフィックのルーティングは瞬時に行われ、新しいモデルのデプロイは 30 分ではなく 5 分未満で完了します。
- 無制限に拡張 – 現在 400 のモデルがありますが、自動的にモデレートできるコンテンツの量を増やし続けるために数千まで拡張する予定です
- 使用されていない機能はオフになるため、EC2 から移行すると 82% のコスト削減が見られ、十分に活用されていない最上位マシンに料金を支払う必要がありません。
ただし、単に理想的なアーキテクチャを設計することは、レガシー システムを再構築する際の本当に興味深い難しい部分ではありません。レガシー システムに移行する必要があります。
移行における最初の課題は、SageMaker Serverless はおろか、SageMaker 上で実行できるように Java WEKA モデルを一体どのように移行するかを考えることでした。
幸いなことに、SageMaker は Docker コンテナにモデルをデプロイするため、少なくとも Java と依存関係のバージョンを凍結して古いコードと一致させることができます。 これは、新しいシステムでホストされているモデルが従来のシステムと同じ結果を返すようにするのに役立ちます。

コンテナに SageMaker との互換性を持たせるために必要なのは、いくつかの特定の HTTP エンドポイントを実装することだけです。
-
POST /invocation— 入力を受け入れ、推論を実行し、結果を返します。 -
GET /ping— JVM サーバーが正常な場合は 200 を返します
(私たちは、BYO マルチモデル コンテナーと SageMaker 推論ツールキットに関する難題をすべて無視することにしました。)
com.sun.net.httpserver.HttpServer をいくつか簡単に抽象化すると、準備が整いました。
そして、あなたは何を知っていますか? これは実際かなり楽しかったです。 Docker コンテナをいじったり、10 年前のものを SageMaker Serverless に強制的に組み込んだりするのは、少々いじくり回したような雰囲気がありました。 それが機能するようになったとき、特に Maven の代わりに新しい sbt スタックに構築するためのレガシー システム コードを取得したときは、非常に興奮しました。
新しい sbt スタックにより作業が容易になり、コンテナ化により SageMaker 環境での実行中に適切な動作が確実に得られるようになりました。
新しいシステムへの移行
これでモデルをコンテナに入れて SageMaker にデプロイできるようになりました。これでほぼ完成ですよね? 完全ではありません。
新しいアーキテクチャへの移行に関する難しい教訓は、移行をサポートするためだけに実際のシステムの 3 倍のシステムを構築する必要があるということです。 新しいシステムに加えて、以下を構築する必要がありました。
- モデルからの入力と出力を記録するための古いシステムのデータ キャプチャ パイプライン。 これらを使用して、新しいシステムが同じ結果を返すことを確認しました。
- 結果を計算し、古いシステムのデータと比較するための、新しいシステムのデータ処理パイプライン。 これには Datadog を使用した大量の測定が必要であり、不一致が見つかった場合にデータを再生する機能を提供する必要がありました。
- 古いシステム (モデルを S3 にアップロードするだけ) のユーザーへの影響を回避するための完全なモデル デプロイメント システム。 最終的には API に移行したいと考えていましたが、最初のリリースではシームレスに移行する必要がありました。
これらはすべて、すべてのユーザーの移行が完了したら捨てられることが分かっていた使い捨てコードでしたが、それでもそれを構築し、新しいシステムの出力が古いシステムと一致することを確認する必要がありました。
事前にこれを予想してください。
このプロジェクトでは移行ツールとシステムの構築にエンジニアリング時間の 60% 以上を費やしましたが、これも楽しい経験でした。 単体テストはデータ サイエンスの実験のようになりました。出力が正確に一致することを確認するためにスイート全体を作成しました。 考え方が違ったので、仕事がとても楽しくなりました。 通常の枠から一歩外れたところです。
再アーキテクチャによるレガシー システムの最新化
次回、システムをコードから再構築する誘惑に駆られた場合は、コードではなくアーキテクチャを移行してみることをお勧めします。 興味深くやりがいのある技術的な課題を見つけることができ、新しいコードの予期せぬエッジケースをデバッグするよりもはるかに楽しめるでしょう。
もっと詳しく知りたいですか? 以下の AWS Data Summit で私が行った講演をご覧ください。MLOps の側面について詳しく説明しています。