
Webスクレイピングによるリードの生成 – 完全ガイド
公開: 2023-10-27あなたが小さなマーケティング代理店を経営しており、別の都市でビジネスを確立しようとしていると想像してください。 しかしそのためには、新しい都市に顧客が必要です。
インターネットを Web サイトごとに手動で検索して、理想的な顧客プロファイルに一致する連絡先情報やビジネスの詳細を収集することもできますが、それは面倒で時間がかかることがわかります。
もっと賢い方法がある、Web スクレイピングです。 これは、広大なインターネットを巧みに横断し、関連情報を取得し、あなただけの潜在的な見込み客の名簿を作成する、不屈のデジタル コンパニオンを持つものであると考えてください。
このガイドでは、Web スクレイピングが見込み顧客発掘の取り組みを促進し、プロセスがより合理化されるだけでなく、より強力になることを保証する方法について詳しく説明します。
見込み顧客獲得のための Web スクレイピングを理解する
Web スクレイピングは、Web ハーベスティングまたは Web データ取得とも呼ばれ、Web サイトからのデータの自動抽出を伴います。 これには、Web ページへのリクエストの送信、HTML またはその他の構造化データの解析、およびさまざまな目的のための特定の情報の抽出が含まれます。 リード生成のコンテキストでは、Web スクレイピングを使用すると、潜在的な顧客に関する貴重な情報をオンライン ソースから収集できます。
見込み顧客発掘に Web スクレイピングを使用する理由
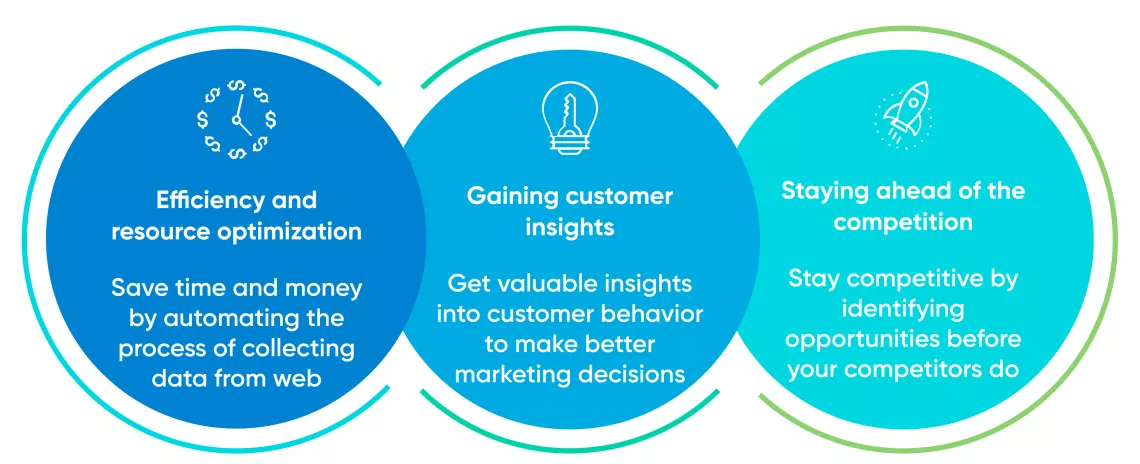
Web スクレイピングには、リード生成に関していくつかの利点があります。
- 効率:リードデータ収集のプロセスを自動化し、時間と労力を節約できます。
- 精度: Web スクレイピング ツールは、一貫して正確にデータを抽出できます。
- スケーラビリティ:多数の Web サイトやソースから情報を収集できます。
- カスタマイズ: Web スクレイピング スクリプトを調整して、基準に一致する特定のリードをターゲットにします。
画像出典:https://scrape-it.cloud/
適切なツールとテクノロジーの選択
人気のある Web スクレイピング ツールとライブラリ
Web スクレイピングには、次のようなよく知られたオプションを選択できる多数のツールとライブラリが自由に利用できます。
- Beautiful Soup: この Python ライブラリは、HTML および XML ドキュメントから情報を抽出するために設計されています。
- Scrapy: Web クローリングとデータ抽出用に調整された広範な Python フレームワーク。
- Selenium: 主にブラウザの自動化に使用されるツールですが、Web スクレイピングにも使用できます。
適切なプログラミング言語の選択
Python は、その親しみやすい構文と、Web データ抽出用に設計された幅広いライブラリがあるため、Web スクレイピングによく使用されます。 あるいは、特定の開発者は、Web スクレイピング タスクを実行するために Node.js、Ruby、Java などの言語を選択します。
有料 Web スクレイピング ツールと無料 Web スクレイピング ツール
Webスクレイピングツールは有料と無料の両方が利用可能です。 無料ツールは初心者に最適で、簡単なスクレイピングタスクのための基本的な機能と機能を提供します。 ただし、プロジェクトがより高度な場合やリソースを大量に消費する場合は、有料オプションを検討してください。 これらのプレミアム ツールは、高度な機能、信頼性の向上、より優れたサポートを提供します。

スタンドアロン ソフトウェアに加えて、有料ではありますが、便利でスケーラブルなソリューションを提供する Web スクレイピング サービス プロバイダーを探すこともできます。 プロジェクトの特定の要件と予算を評価して、Web スクレイピングのニーズに最適な選択を行います。
見込み顧客発掘のための Web スクレイピングのプロセス
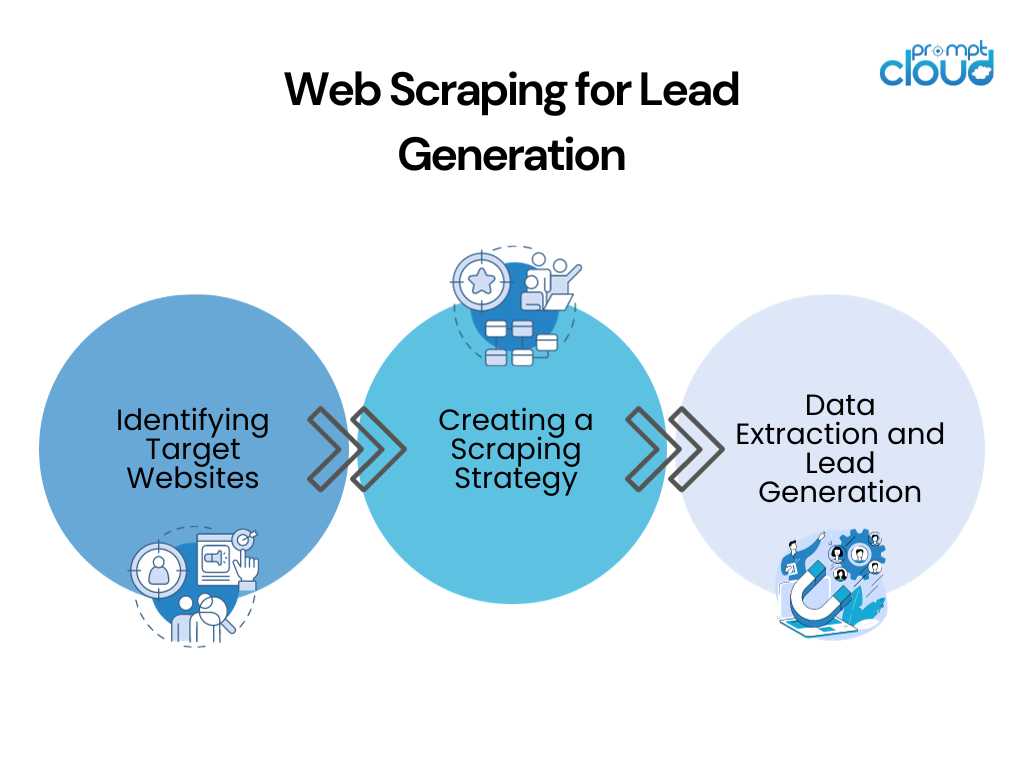
ターゲット Web サイトの特定
Web スクレイピングを使用して潜在顧客を発掘する最初のステップは、ターゲット Web サイトを特定することです。 これらは、潜在的な顧客が存在すると思われる Web サイトです。 これは、業界固有のフォーラム、ソーシャル メディア プラットフォーム、オンライン ディレクトリなどです。 対象ユーザーに関する最新かつ正確な情報が掲載されている可能性が高い Web サイトを選択することが重要です。
スクレイピング戦略の作成
対象とする Web サイトを特定したら、次のタスクにはスクレイピング戦略の開発が含まれます。 これには、抽出する特定のデータを決定し、そのデータを見つけるために Web サイトの構造を横断する計画を立てることが含まれます。 効果的なスクレイピング戦略を策定するための包括的な段階的なプロセスを次に示します。
- データの目的を指定する:対象となる Web サイトから取得する予定の正確な情報を明確に定義します。 これには、連絡先の詳細、役職、会社名、または潜在顧客の発掘に重要なその他の関連データ ポイントが含まれる場合があります。
- Web サイトのフレームワークを調査する:ブラウザー開発者ツールや特殊なソフトウェアなどの Web スクレイピング ツールを使用して、選択した Web サイトの HTML 構造を注意深く調査します。 目標は、探しているデータが格納されているタグ、クラス、またはその他の特徴的なマーカーを見つけることです。
- スクレイピング ロジックを構築する: Web サイトの構造に関する洞察に基づいて、目的のデータに移動するために必要な論理手順の概要を説明します。 これには、情報にアクセスするためのリンクのクリック、フォームの送信、ページのスクロールなどのアクションが含まれる場合があります。
- スクレイピング方法の選択: ターゲット Web サイトの複雑さに基づいて、適切なスクレイピング方法を選択します。 これには、ブラウザ拡張機能の使用、Python などの言語でのカスタム スクリプトの作成、専用のスクレイピング ツールの使用などが含まれます。
- エラー処理を実装する: ログイン要件や CAPTCHA チャレンジなど、スクレイピング プロセス中に発生する可能性のあるエラーや障害を予測します。 エラー処理手法を実装して、スムーズで中断のないスクレイピング エクスペリエンスを確保します。
データ抽出とリード生成
Web スクレイピング戦略の設定がすべて完了したので、データ抽出とリード生成プロセスを開始します。 段階的に詳しく見ていきましょう。
- 必須ツールを入手する:スクレイピング戦略を効果的に実装するために必要なソフトウェア、ツール、またはプログラミングの専門知識があることを確認してください。 これには、スクレイピング ライブラリのインストールやカスタム コードの作成が含まれる場合があります。
- スクレイピング環境を準備する: 適切なプログラミング言語の選択、必要なパッケージのインストール、必要に応じてプロキシまたは IP ローテーション メカニズムのセットアップなど、スクレイピング環境をセットアップします。
- スクレイピング戦略を実行する: 戦略で概説されている手順に従って、スクレイピング ロジックを実装します。 特定された HTML 構造を使用して Web サイトを移動し、必要なデータを抽出し、CSV ファイルや Excel ファイルなどの構造化された形式で保存します。
- 抽出されたデータを検証する: 抽出されたデータをレビューして、その正確性と完全性を確認します。 重複、誤ったエントリ、または無関係な情報を削除します。
- データをリード生成プロセスに統合する: データを抽出して検証したら、それをリード生成プロセスに統合します。 これには、CRM システムへのデータのインポート、電子メール マーケティング プラットフォームへのアップロード、またはその他の関連するマーケティング ツールや販売ツールでのデータの利用が含まれる場合があります。
結論
Web スクレイピングは見込み顧客発掘の分野で強力な味方となり、企業に見込み客に関する貴重な洞察の宝庫を提供します。 このガイドに記載されている包括的な手順を進めていくと、Web スクレイピングの力を活用して、関心のある特定の Web サイトを特定し、効果的なスクレイピング戦略を考案し、貴重なリードをうまく獲得する方法がわかります。
Web スクレイピング活動に従事する際には、倫理的行動に対する強い取り組みと Web サイトの利用規約を深く尊重し続けることが重要です。 適切な方法論を使用すれば、Web スクレイピングは、この分野での取り組みを強化することを目指す企業にとって、見込み客発掘に革命を起こす可能性を秘めています。
見込み顧客発掘のための Web スクレイピングの信頼できるソリューションをお探しですか? PromptCloud があなたをサポートします! Web データ抽出における当社の経験と専門知識により、ビジネスのリードを生み出すために必要な正確で関連性の高いデータを提供することを信頼していただけます。