
Web クローラーの仕組み
公開: 2023-12-05Web クローラーは、インターネット上に存在する広範な情報のインデックス作成と構造化において重要な機能を果たします。 彼らの役割には、Web ページを走査し、データを収集し、それを検索可能にすることが含まれます。 この記事では、Web クローラーの仕組みを詳しく説明し、そのコンポーネント、操作、およびさまざまなカテゴリについての洞察を提供します。 Web クローラーの世界を深く掘り下げてみましょう。
ウェブ クローラーとは
スパイダーまたはボットと呼ばれる Web クローラーは、インターネット Web サイトを体系的にナビゲートするように設計された自動スクリプトまたはプログラムです。 シード URL から始まり、HTML リンクをたどって他の Web ページにアクセスし、インデックス付けと分析が可能な相互接続されたページのネットワークを形成します。
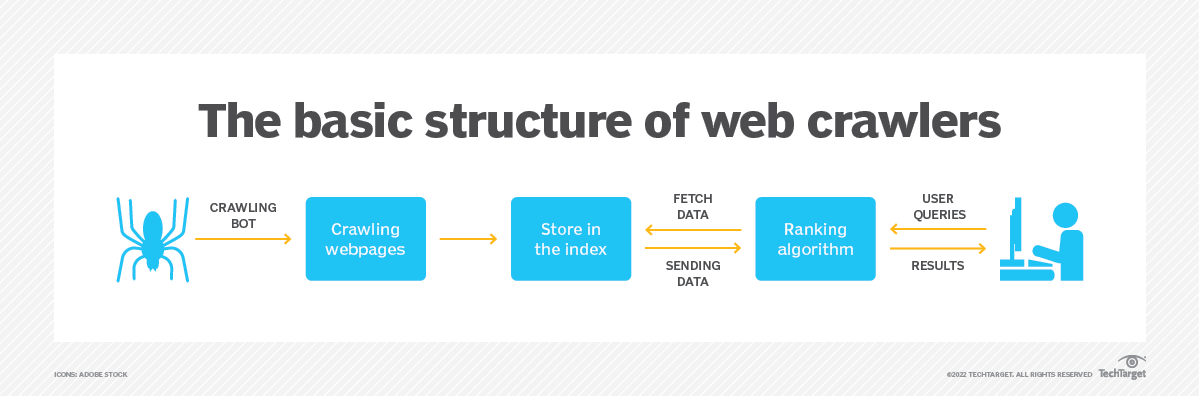
画像出典: https://www.techtarget.com/
Web クローラーの目的
Web クローラーの主な目的は、Web ページから情報を収集し、効率的に取得するための検索可能なインデックスを生成することです。 Google、Bing、Yahoo などの主要な検索エンジンは、検索データベースを構築するために Web クローラーに大きく依存しています。 Web コンテンツを体系的に検査することで、検索エンジンは適切な最新の検索結果をユーザーに提供できます。
Web クローラーのアプリケーションは検索エンジンを超えて拡張されることに注意することが重要です。 また、データ マイニング、コンテンツ集約、Web サイトの監視、さらにはサイバーセキュリティなどのタスクのためにさまざまな組織でも使用されています。
Web クローラーのコンポーネント
Web クローラーは、その目標を達成するために連携して動作するいくつかのコンポーネントで構成されています。 Web クローラーの主要なコンポーネントは次のとおりです。
- URL フロンティア:このコンポーネントは、クロールを待機している URL のコレクションを管理します。 関連性、鮮度、Web サイトの重要性などの要素に基づいて URL に優先順位を付けます。
- ダウンローダー:ダウンローダーは、URL フロンティアによって提供される URL に基づいて Web ページを取得します。 HTTP リクエストを Web サーバーに送信し、応答を受信し、取得した Web コンテンツをさらなる処理のために保存します。
- パーサー:パーサーはダウンロードされた Web ページを処理し、リンク、テキスト、画像、メタデータなどの有用な情報を抽出します。 ページの構造を分析し、リンクされたページの URL を抽出して URL フロンティアに追加します。
- データ ストレージ:データ ストレージ コンポーネントは、Web ページ、抽出された情報、インデックス データなどの収集されたデータを保存します。 このデータは、データベースや分散ファイル システムなどのさまざまな形式で保存できます。
Web クローラーの仕組み
関連する要素を理解したら、Web クローラーの機能を説明する一連の手順を詳しく見てみましょう。
- シード URL:クローラーはシード URL から開始します。これは、任意の Web ページまたは URL のリストです。 この URL は、クロール プロセスを開始するために URL フロンティアに追加されます。
- フェッチ:クローラーは URL フロンティアから URL を選択し、対応する Web サーバーに HTTP リクエストを送信します。 サーバーは Web ページのコンテンツで応答し、それがダウンローダー コンポーネントによってフェッチされます。
- 解析:パーサーは取得した Web ページを処理し、リンク、テキスト、メタデータなどの関連情報を抽出します。 また、ページ上で見つかった新しい URL を識別して URL フロンティアに追加します。
- リンク分析:クローラーは、関連性、鮮度、重要性などの特定の基準に基づいて、抽出された URL に優先順位を付けて URL フロンティアに追加します。 これは、クローラーがページにアクセスしてクロールする順序を決定するのに役立ちます。
- プロセスの繰り返し:クローラーは、URL フロンティアから URL を選択し、その Web コンテンツを取得し、ページを解析し、さらに URL を抽出することでプロセスを継続します。 このプロセスは、クロールする URL がなくなるか、事前定義された制限に達するまで繰り返されます。
- データ ストレージ:クロール プロセス全体を通じて、収集されたデータはデータ ストレージ コンポーネントに保存されます。 このデータは、後でインデックス付け、分析、またはその他の目的に使用できます。
Web クローラーの種類
Web クローラーにはさまざまなバリエーションがあり、特定の使用例があります。 一般的に使用される Web クローラーのタイプをいくつか示します。

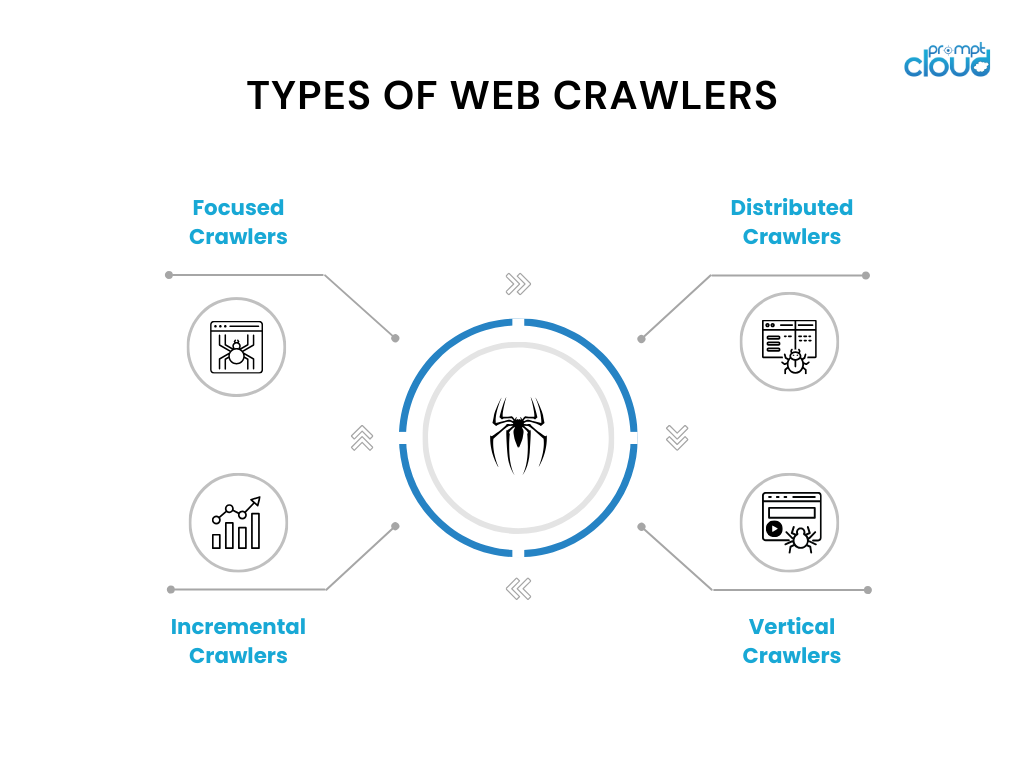
- 集中型クローラー:これらのクローラーは、特定のドメインまたはトピック内で動作し、そのドメインに関連するページをクロールします。 例には、ニュース Web サイトや研究論文に使用されるトピック クローラーが含まれます。
- 増分クローラー:増分クローラーは、最後のクロール以降に新しいコンテンツまたは更新されたコンテンツをクロールすることに重点を置きます。 タイムスタンプ分析や変更検出アルゴリズムなどの技術を利用して、変更されたページを特定してクロールします。
- 分散クローラー:分散クローラーでは、クローラーの複数のインスタンスが並行して実行され、膨大な数のページをクロールするワークロードを共有します。 このアプローチにより、クロールが高速化され、スケーラビリティが向上します。
- 垂直クローラー:垂直クローラーは、画像、ビデオ、製品情報など、Web ページ内の特定の種類のコンテンツまたはデータをターゲットとします。 これらは、特殊な検索エンジン用に特定の種類のデータを抽出してインデックスを作成するように設計されています。
Web ページをどのくらいの頻度でクロールする必要がありますか?
Web ページのクロール頻度は、Web サイトのサイズと更新頻度、ページの重要性、利用可能なリソースなどのいくつかの要因によって異なります。 最新情報のインデックスを確実に作成するために頻繁なクロールが必要な Web サイトもあれば、クロールの頻度が低い Web サイトもあります。
トラフィックの多い Web サイトや、コンテンツが急速に変化する Web サイトの場合、最新の情報を維持するには、より頻繁にクロールすることが不可欠です。 一方、小規模な Web サイトや更新頻度の低いページは、クロールの頻度が低くなり、必要な作業負荷とリソースが軽減されます。
社内 Web クローラーと Web クローリング ツール
Web クローラーの作成を検討する場合、複雑さ、拡張性、必要なリソースを評価することが重要です。 クローラーをゼロから構築することは、同時実行性の管理、分散システムの監視、インフラストラクチャの障害への対処などの作業を含む、時間のかかる作業になる可能性があります。 逆に、Web クローリング ツールまたはフレームワークを選択すると、より迅速かつ効果的な解決策が得られます。
あるいは、Web クローリング ツールまたはフレームワークを使用すると、より高速で効率的なソリューションを提供できます。 これらのツールは、カスタマイズ可能なクロール ルール、データ抽出機能、データ ストレージ オプションなどの機能を提供します。 既存のツールを活用することで、開発者はデータ分析や他のシステムとの統合などの特定の要件に集中できます。
ただし、カスタマイズ、データ所有権、潜在的な価格モデルの制限など、サードパーティ ツールの使用に関連する制限とコストを考慮することが重要です。
結論
検索エンジンは、インターネット上に存在する広範な情報を整理してカタログ化するタスクに役立つ Web クローラーに大きく依存しています。 Web クローラーの仕組み、コンポーネント、さまざまなカテゴリを理解することで、この基本的なプロセスを支える複雑なテクノロジーをより深く理解できるようになります。
Web クローラーを最初から構築する場合でも、Web クローリング用の既存のツールを活用する場合でも、特定のニーズに合わせたアプローチを採用することが不可欠になります。 これには、スケーラビリティ、複雑さ、自由に使えるリソースなどの要素を考慮する必要があります。 これらの要素を考慮することで、Web クローリングを効果的に利用して貴重なデータを収集および分析し、ビジネスや研究の取り組みを前進させることができます。
PromptCloud では、Web データ抽出を専門とし、公開されているオンライン リソースからデータを調達します。 sales@promptcloud.comまでご連絡ください。