
リバース ETL: 各段階でデータドリブンの意思決定を強化
公開: 2022-09-29ETL (抽出、変換、ロード) は、アクセスして操作できるリポジトリにデータをソーシング、クリーニング、およびロードする 3 つの段階を含むデータ分析パイプライン プロセスです。
しかし、ETL を元に戻すことができたらどうでしょうか? つまり、ソースから収集されたデータを使用して、プロセスの各段階で意思決定を行うことができます。
データ アーキテクチャには常に不規則性や脆弱性が存在しますが、リバース ETL は、誰もが同じ情報に基づいて作業し、レポートの数値が正確で、会社の業績をより正確に予測できるようにするための最良の方法です。
このガイドは、リバース ETL、それが役立つ理由、および日常的なユース ケースを理解するのに役立ちます。
重要ポイント
- リバース ETL を使用すると、クリーンですぐに使用できるデータをソース システムからダウンストリームの分析および BI ツールに取得するプロセスを自動化できます。
- リバース ETL を使用して、データを操作しながら、効率、柔軟性、可視性、一貫性を向上させます。
- 専用のリバース ETL ツールを活用して、信頼性の低い (そしてコストのかかる) カスタム ソリューションや、面倒なポイント ツー ポイントの自動化から離れましょう。
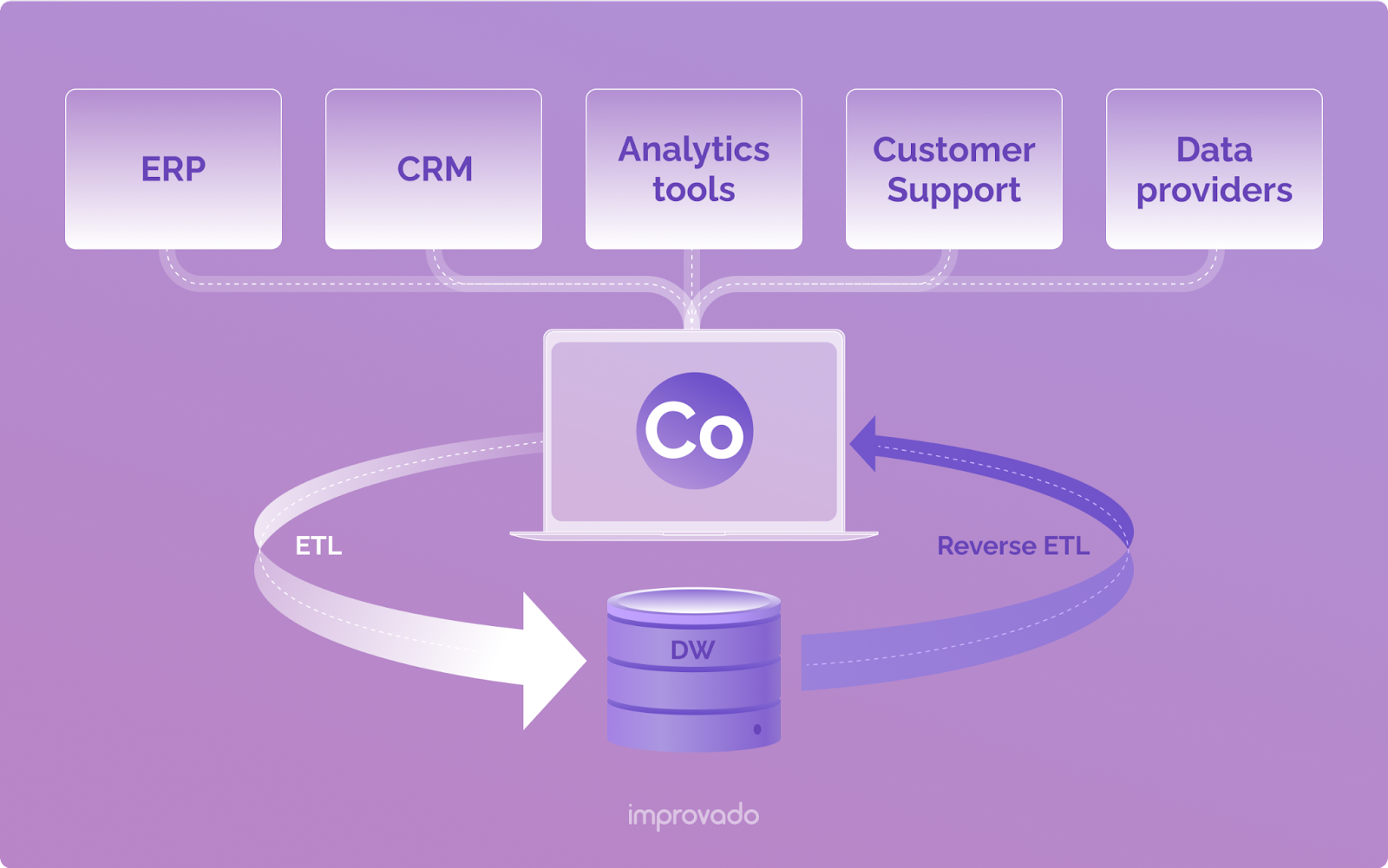
リバース ETL とは何ですか?
リバース ETL は、信頼できるソース (通常はデータ ウェアハウスまたはデータ レイク) からのデータを、CRM、広告プラットフォーム、ERP などのさまざまなビジネス アプリケーションに直接同期する方法です。
概念をよりよく理解するために、ETL システムと ELT システムの簡単な復習と、リバース ETL の違いについて説明します。
ETL、ELT、リバース ETL はすべてデータ パイプラインです。 途中でデータに変換を適用しながら、システム A からシステム B にデータを移動します。 「E」は「extract」、「T」は「transform」、「L」は「load」です。 具体的には:
- ETL では、1 つ以上のソースからデータを抽出し、ターゲット システムにロードできる形式に変換します。
- ELT は、Transform ステップと Load ステップの順序を逆にする同様のプロセスです。 データはまずターゲット システムにロードされ、次にそのシステムの要件に適合するように変換されます。
- リバース ETL は、抽出ステップとロード ステップの順序を逆にします。 データはソース システムから抽出され、変換されることなくターゲット システムに直接ロードされます。
リバース ETL により、中間の変換ステップが不要になるため、時間とリソースを節約できます。 ただし、データがターゲット システムと互換性がなく、使用する前にさらに処理が必要になる可能性があることも意味します。
その結果、リバース ETL は、ソース システムとターゲット システムが非常に類似している場合や、データを変換する必要がない場合に適しています。
リバース ETL を統合する利点
リバース ETL ツールは、いわゆるハブ アンド スポーク アプローチを使用します。 つまり、すべてのアウトバウンド接続にデータ ウェアハウスを使用できます。 ビジネス ツールは、同じ信頼できる基本的なソースからデータを引き出すことができるため、多くのポイント ツー ポイント統合間の潜在的な違いを回避できます。
リバース ETL の利点は次のとおりです。
- データの運用化:技術スタックの各「スポーク」にデータを表示することで、チームは抽象的な情報を取得し、それを具体的で測定可能なものに変えることができます。
- データの一貫性:統一されたソースからデータを取り込むことで、全員が同じ情報を使用していると確信できます。 会社の業績を予測するために正確なレポートを必要とする営業およびマーケティング チームにとって、一元化されたデータへのアクセスは非常に重要です。
- 効率の向上:リバース ETL を適切に実装すると、特にデータ チームにとって、中間の変換ステップが不要になるため、時間とリソースを節約できます。 すべての API 接続はウェアハウスと統合されるため、カスタム コードを内部で構築または維持することについて心配する必要はありません。 したがって、リバース ETL により、データ チームは解放され、価値の高い作業に専念できます。
- 柔軟性の向上:リバース ETL を使用すると、同期するデータと同期するタイミングを選択できるため、必要に応じてリバース ETL プロセスからアプリケーションを簡単に追加または削除できます。
- 可視性の向上:リバース ETL はデータ フローの全体像を提供し、潜在的なエラーや改善が必要な領域を簡単に特定できるようにします。
- ツールの一貫性:変換されたデータをビジネス アプリケーションに直接送信することで、ユーザーは、BI ツールよりも快適に使用できるネイティブ ツールを使用できます。

リバース ETL のユースケース
リバース ETL の利点について説明したので、このフレームワークが効果的な特定の使用例を見てみましょう。
CRMへの顧客データのアップロード
このシナリオでは、ERP、財務、注文管理ツールなどの内部システムからデータを抽出します。
このデータは CRM システムに読み込まれるため、販売およびマーケティング チームは 1 つの場所から顧客情報にアクセスできます。 既に互換性のある形式になっているため、データを変換する必要はありません。
2 つの類似システム間のデータの同期
この使用例は上記のものと似ていますが、2 つのシステムは必ずしも互換性があるわけではありません。 ロードする前に、データをターゲット システムに変換する必要がある場合があります。 たとえば、データを CSV から JSON 形式に変換する必要がある場合があります。
新しいシステムへのデータの移行
オンプレミスのデータ ウェアハウスからクラウドベースのソリューションに移行したり、CRM システムを切り替えたりすることができます。 どのような場合でも、データへのリバース ETL 転送を設定できます。
この統合により、データを手動で転送したり、カスタム スクリプトを作成したりする必要がなくなります。 新しいシステムの要件に合わせてデータを変換する必要がある場合があることに注意してください。
バックアップの作成
バックアップの管理は、リバース ETL の日常的な使用例です。 データはソース システムから抽出され、バックアップ システムにロードされます。 バックアップ以外には必要ないため、データを変換する必要はありません。
リバース ETL が最新のデータ スタックにどのように適合するか
リバース ETL を使用してデータを運用化するアプリケーションは無限にあります。 データ スタックでリバース ETL を使用する 3 つの例を見てみましょう。
営業チームのデータを CRM に同期
Salesforce のような CRM ツールには、すぐに使える優れたレポート ソリューションがいくつかあり、通常、営業チームがほとんどの時間を費やす場所です。
ウェアハウスで未加工の Salesforce データを抽出してロードし、それを他の会社のデータと組み合わせて、通常の ETL/ELT パイプラインでカスタム メトリックを作成します。
ただし、リバース ETL ツールを使用して、その新しいカスタマイズされたデータと指標を倉庫から営業チームの CRM に同期できます。
営業チームは引き続き共有倉庫ロジックを使用していますが、それを確認するために別のレポート ツールに移動する必要はありません。 また、必要なものを把握するためにカスタム レポートを作成する必要もありません。

マーケティング キャンペーンに顧客データを使用する
あなたのマーケティング チームは、新しいマーケティング キャンペーンのために、データ ウェアハウスから顧客のセグメント化されたリストを作成したいと考えています。 クエリを作成してデータをエクスポートするのではなく、リバース ETL を使用して、ウェアハウスから Google スプレッドシート、スプレッドシート、または同様のものにデータを自動的に送信できます。
マーケティング チームは必要に応じてデータを使用でき、エンジニアリング チームにデータの取得を依頼する必要はありません。
データでカスタマーサポートを改善
カスタマー サポートでは、Slack と Zendesk を組み合わせてカスタマー チケットを管理しています。 しかし、ウェアハウスのデータを使用して、チケットを適切なサポート エージェントに自動的に転送できるとしたらどうでしょうか?
リバース ETL を使用して、特定の発生についてデータを監視し、それに応じてアクションを実行できます。 この場合、チケットの詳細を含むメッセージを Slack に送信し、それを適切なサポート エージェントに割り当てます。
こうすることで、カスタマー サポート チームはチケットのルーティングではなく、チケットの解決に集中できます。 そして、正しいチケットが正しい人に届くことを確信できます。
リバース ETL でできることに制限はありません。 重要なのは、それを使用して完全なデータ パイプラインを形成する方法を理解することです。
構築するか購入するか: どのリバース ETL ソリューションを選択すべきか?
リバース ETL の概念は新しいものではありませんが、最近まで、実装に役立つツールはありませんでした。 クラウドベースのデータ ウェアハウスの登場により、状況が変わりました。
以前は、チャネル間でデータを同期するためにカスタム アプリケーションを作成する必要がありました。 このような取り組みには、API の接続と管理、およびインターフェイスの設計を担当することが含まれます。 さらに重要なことに、製品とコードの両方を維持する必要があります。
このアプローチの問題点は、何か問題が発生した場合に 1 人または 2 人のエンジニアが対応できる必要があることです。
もう 1 つのアプローチは、ダッシュボード内の別の BI ツールでデータを模倣しようとすることです。 ただし、この方法を使用して数字を正確に一致させることは困難です。
Zapier や Make などの自動化ツールを使用することもできます。 これらのツールは、1 回限りのトリガーを作成する場合など、ワークロードが小さい場合に効果的です。 ただし、これらの同期の数はニーズに応じて急速に増加するため、自動化は意図した用途以外には実用的ではありません.
そこでリバース ETL ツールの出番です。このツールは、カスタム コードを必要とせず、エンジニアに頼ることなくデータ同期を管理する方法を提供します。
他の部門への依存を制限することで、カスタム ビルドのソリューションよりも迅速に稼働させることができます。 ベンダーがサポートと更新を提供するため、使用と保守も簡単です。
さらに重要なことは、変換されたデータをビジネス アプリケーションに直接送信するということは、チームが使い慣れたソフトウェアを使い続けることができるということです。
リバース ETL は、保守性を維持しながらニーズに合わせて拡張できるスケーラブルなソリューションです。 そのため、チャネル全体でデータを管理するための頼りになるソリューションになりつつあります。
リバース ETL モデルを実装するための次のステップ
データ駆動型の意思決定を行うには、適切なタイミングで適切な形式の正しいデータが必要であり、リバース ETL はほとんどの条件を満たします。
リバース ETL システムを統合することで、クリーンですぐに使用できるデータをソース システムからダウンストリームの分析および BI ツールに取得するプロセスを自動化できます。 その結果、意思決定を改善し、これまでにない速さでデータからより多くの洞察を得ることができます。
独自のニーズに合ったリバース ETL ソリューションをお探しの場合は、Improvado のチームがお手伝いします。 モデルを構築し、すぐにデータ主導の意思決定をより適切かつ迅速に行えるように支援します。