
Jarvis Rising – 検索では回答を予測できない場合に、Google がどのようにして機械学習モデルを「オンザフライ」で生成し、それらのモデルにインデックスを付けて将来のクエリの回答を予測できるか [特許]
公開: 2023-07-13
PAA および PASF に関連する Google の特許を分析した後、他の最近付与された特許の検討を開始しました。 そして、機械学習モデルの使用に関する別の非常に興味深い問題を明らかにするまで、それほど時間はかかりませんでした。 私が分析したばかりの特許は、クエリに応答して機械学習モデルを使用および/または生成することに焦点を当てています (標準の検索結果では適切な答えが得られないため、Google が答えを予測する必要がある場合)。 この特許を何度も読んだ結果、ユーザーに質の高い回答 (または予測) を提供する必要がある場合に、Google のシステムがいかに洗練され得るかが強調されました。
他の特許と同様に、Google が特許の対象となる内容を実際に実装したかどうかはわかりませんが、その可能性は常にあります。 そして、これが実装されれば、Google はトレーニングされた機械学習モデルを利用してクエリに対する答えを予測できるようになるだけでなく、それらの機械学習モデルにインデックスを付け、さまざまなエンティティやウェブページなどに関連付け、取得したり、それらのモデルを後続の関連検索に使用します。 それが Google にとってどれほど強力でスケーラブルであるかを考えてみましょう。
さらに、この特許では、Google が検索結果の機械学習モデルにインタラクティブなインターフェイスを返すことができるため、ユーザーは検索結果が不十分な場合にクエリの予測を生成するために使用できるパラメータを追加できると説明しています。 この特許の部分を見て、Google が 2020 年 4 月にクエリに対して質の高い検索結果が返されなかったときに SERP で展開したメッセージについて考えさせられました。 現在の実装ではユーザーが操作できるフォームは提供されていませんが、いつかは提供されるようになるでしょう。 そしておそらく、そのインターフェイスは、現時点では表面化しているより曖昧なクエリだけでなく、将来的にはより多くのクエリに使用される可能性があります。 これについては、以下の箇条書きで詳しく説明します。
特許の重要なポイント:
最近の Google 特許を取り上げた前回の投稿と同様に、詳細を取り上げる最善の方法は、重要なポイントを箇条書きで示すことだと思います。
検索リクエストに応じて機械学習モデルを生成および/または利用する
米国 11645277 B2
付与日: 2023 年 5 月 9 日
提出日: 2017 年 12 月 12 日
譲受人名: Google LLC
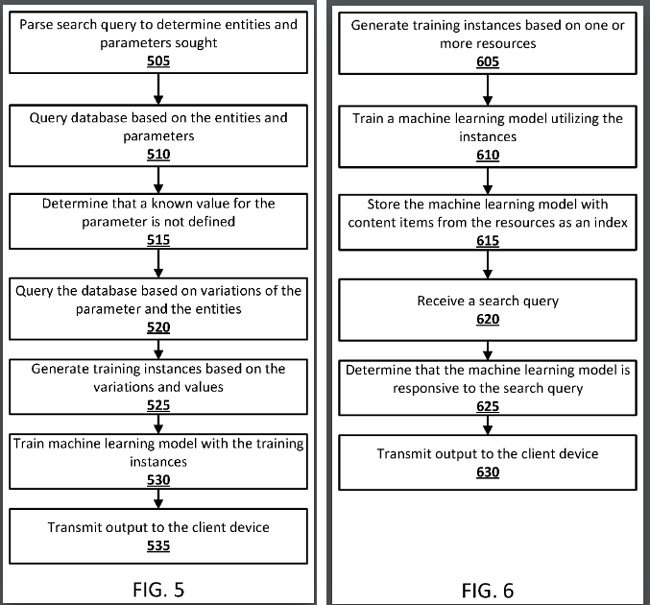
1. Google の特許では、答えを確実に見つけることができず、ユーザーが本質的に予測的なリクエストを送信した場合、トレーニングされた機械学習モデルを使用して予測を生成できると説明しています。
2. たとえば、Google は最初にクエリに基づいて検索結果を生成できますが、結果の品質が十分でない場合は、機械学習モデルを使用してより強力な予測回答を提供できます。 そのため、Google が回答を検証できない場合、システムは機械学習モデルに基づいて予測された回答を提供できます。

3. また、機械学習モデルは「オンザフライ」で生成でき、Google はトレーニングされた機械学習モデルを検索インデックスに保存する可能性があります。 はい、Google は、特定の種類のクエリに基づいて予測を提供するようにトレーニングされたばかりの機械学習モデルにインデックスを付けることができます。 これについては後ほど詳しく説明します。

4. この特許では、「2050 年には中国には何人の医師がいるだろうか?」という質問に基づいた例が提供されています。 標準の検索結果から信頼できる回答を提供できない場合は、クエリをトレーニングされた機械学習モデルに渡して予測を生成できます。

5. 特許ではさらに、システムが 2010 年、2015 年、2020 年などの他の年を要し、それらの年を使用して (これらのパラメーターでトレーニングされた機械学習モデルを介して) 予測を生成する可能性があると説明しています。

6. この特許では、トレーニングされた機械学習モデルは、「モデルのトレーニングに利用されるリソース」からの 1 つ以上のコンテンツ項目によってインデックス付けできると説明されています。 また、将来のクエリのために、システムが機械学習モデルに関連するパラメーターを識別するとき (たとえば、後続のユーザーが「 2040 年の中国には医師は何人いるの?」などの関連する質問をした場合)、機械学習モデルは次のような可能性があります。予測を生成するために使用されます。

7. この特許ではさらに、ナレッジ グラフ内のエンティティ、テーブル名、列名、Web ページ名などの 1 つ以上のコンテンツ アイテムとともに機械学習モデルを保存できると説明しています。 さらに、「中国」や「医師」などのクエリに関連付けられた単語は、機械学習モデルによって予測を生成するために使用される可能性があります。
8. この特許では、このシステムが機械学習モデルに渡すことができるパラメーターを選択するための対話型インターフェイスをユーザーに提供する可能性があると説明されています。 これは、テキスト フィールド、ドロップダウン メニューなどです。また、応答には、その応答がトレーニングされた機械学習モデルに基づく予測であるというユーザーに提示されるメッセージが含まれる場合もあります。 そのためGoogleは、これが機械学習モデルに基づく予測であり、インデックス付けしたデータに基づいて提供される回答であることをユーザーに理解してもらいたいと考えている。

9. その後、トレーニングされたモデルを検証して、予測が少なくとも「しきい値の品質」であることを確認できます。 特定のしきい値を下回るものは抑制され、ユーザーに提供されないようにすることができます。 その場合、代わりに標準の検索結果を表示できます。

10. この特許では、公開された検索結果以外にも、このシステムをプライベート データベース上で使用して、企業が特定の結果を予測できるようにすることができると説明しています。 この特許では、「ユーザーのグループ、企業、および/またはその他の制限されたセットに対して非公開」と説明されています。 たとえば、遊園地の従業員が「明日はかき氷が何個売れるでしょうか?」と尋ねるかもしれません。 その後、システムはプライベート データベースにクエリを実行して、前日の売上、気象情報、勤怠データなどを把握し、従業員の回答を予測することができます。
11. この特許では、システムがある時点で「自動アシスタント」からプッシュ通知を提供できる可能性があると説明されています。 そして、ただ大声で考えてみると、出版社に数千もの Code Red を引き起こした Google の Code Red についての投稿で説明したような、ジャービスのようなアシスタントによるものではないかと考えています。

12. 遅延の観点から、特許では、ユーザーがクエリを送信した後に遅延が発生する可能性があると説明されています。 その場合、標準の検索結果が、クエリに対して「良好な」結果が得られず、予測の生成に機械学習モデルが使用されていることを示すメッセージとともに最初に表示される可能性があります。 このような状況では、システムは後でその予測をユーザーにプッシュしたり、ユーザーがクリックして機械学習の出力を表示できるハイパーリンクを提供したりできます。
13. また、特許では、状況によっては、プロセスを続行するためにユーザーがプロンプトを承認する必要があるとも述べています。 たとえば、システムは次のようなメッセージを表示する場合があります。 答えを予想してみませんか?」 その後、プロンプトに対して肯定的なユーザー入力が受信された場合にのみ、機械学習モデルがトレーニングされます。 先ほど説明したように、2020 年 4 月に展開された「検索に一致するものはありません」というメッセージとの関連性がわかります。将来的には、このモデルの利用が拡大する可能性があるのではないかと考えています…

概要: Google は、(インデックス付き) 機械学習モデルを介して、強力かつ超効率的な方法で質の高い回答を予測している可能性があります。
特定の特許が使用されているかどうかはわかりませんが、このプロセスの威力と効率性は Google にとって非常に意味のあるものです。 機械学習モデルの「オンザフライ」生成から、将来使用するためのそれらのモデルのインデックス作成、プッシュ通知を備えたインタラクティブなインターフェースの利用まで、Google はジャービスのようなアシスタントのための準備を整えているようです。 したがって、次回 Google に答えの予測を依頼するときは、この特許について考えてください。 そして、ある時点で詳細情報の入力を求められるかもしれません (ジャービスがこれらすべてをナノ秒で実行できるようになるまで)。 :)
GG