
Webスクレイピングにおける技術的課題の克服: エキスパートによるソリューション
公開: 2024-03-29Web スクレイピングは、熟練したデータマイナーにとっても、多くの技術的な課題を伴う手法です。 これには、Web サイトからデータを取得して取得するためにプログラミング技術を使用する必要がありますが、Web テクノロジーの複雑で多様な性質のため、これは必ずしも簡単ではありません。
さらに、多くの Web サイトではデータ収集を防ぐための保護措置が講じられているため、スクレイパーがスクレイピング防止メカニズム、動的コンテンツ、複雑なサイト構造をネゴシエートすることが不可欠となっています。
有用な情報をすぐに入手するという目的は単純そうに見えますが、そこに到達するにはいくつかの恐るべき障壁を乗り越える必要があり、強力な分析能力と技術能力が求められます。
動的コンテンツの処理
動的コンテンツとは、ユーザーのアクションに基づいて更新される Web ページ情報や、最初のページ ビューに続く読み込みを指すもので、Web スクレイピング ツールにとって一般的に課題となります。
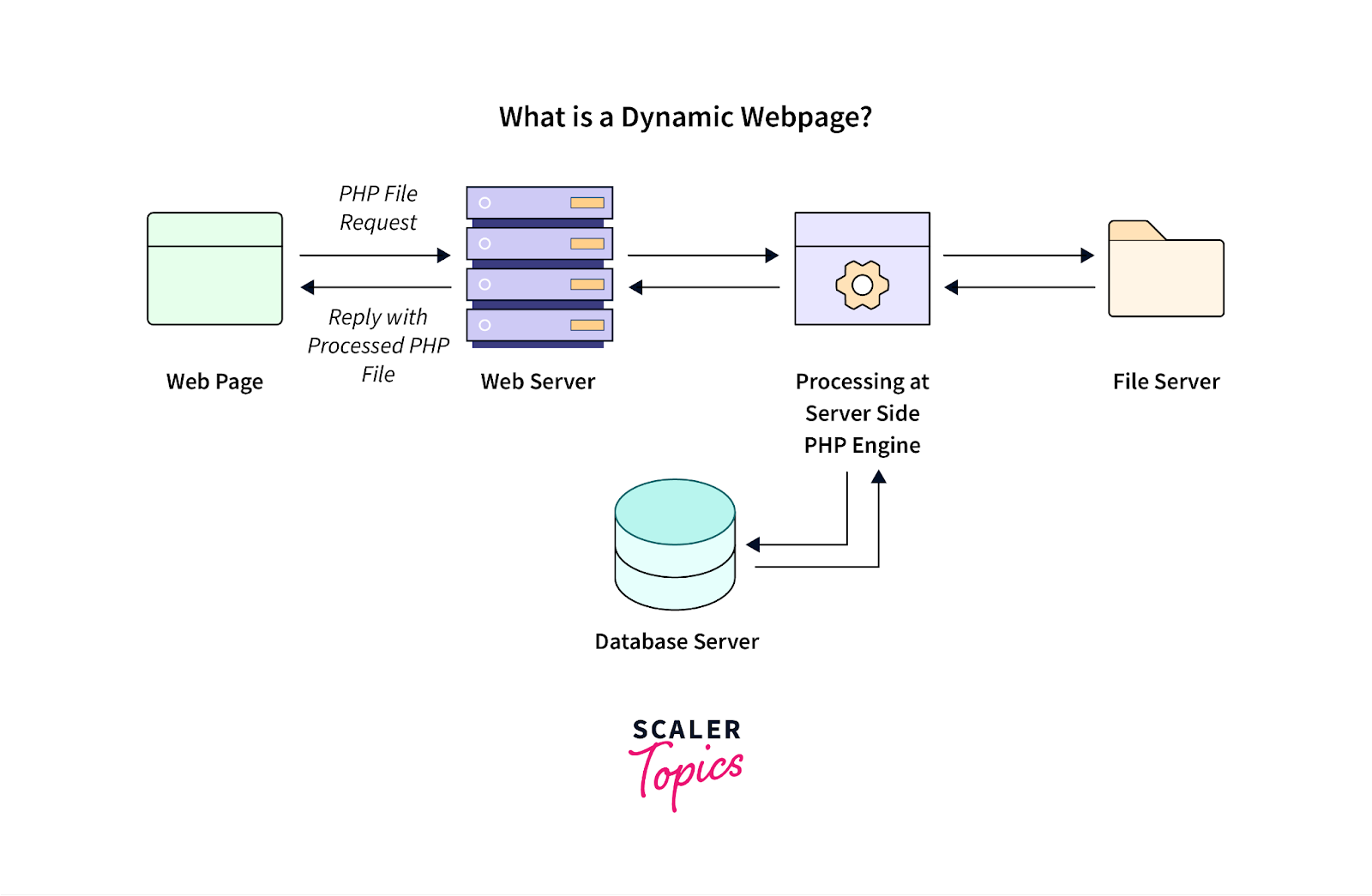
画像ソース: https://www.scaler.com/topics/php-tutorial/dynamic-website-in-php/
このような動的コンテンツは、JavaScript フレームワークを使用して構築された最新の Web アプリケーションで頻繁に利用されます。 このように動的に生成されたコンテンツからデータを適切に管理および抽出するには、次のベスト プラクティスを考慮してください。
- Selenium、Puppeteer、 Playwright などの Web 自動化ツールの使用を検討してください。これにより、Web スクレイパーが Web ページ上で本物のユーザーと同じように動作できるようになります。
- Web サイトがコンテンツを動的にロードするためにこれらのテクノロジを利用している場合は、 WebSocketまたはAJAX処理テクノロジを実装します。
- スクレイピング コードで明示的な待機を使用して要素が読み込まれるのを待機し、スクレイピングを試行する前にコンテンツが完全に読み込まれていることを確認します。
- JavaScript を実行し、動的に読み込まれるコンテンツを含むページ全体をレンダリングできるヘッドレス ブラウザを使用して探索します。
これらの戦略を習得することで、スクレイパーは最もインタラクティブで動的に変化する Web サイトからも効果的にデータを抽出できます。
アンチスクレーピング技術
Web 開発者が Web サイトを保護するために、未承認のデータ スクレイピングを防止することを目的とした対策を講じるのは一般的です。 これらの対策は、Web スクレイパーにとって重大な課題となる可能性があります。 アンチスクレイピングテクノロジーをナビゲートするためのいくつかの方法と戦略を次に示します。

画像ソース: https://kinsta.com/knowledgebase/what-is-web-scraping/
- 動的ファクタリング: Web サイトはコンテンツを動的に生成する場合があり、URL や HTML 構造の予測が困難になります。 JavaScript を実行し、AJAX リクエストを処理できるツールを利用します。
- IP ブロック: 同じ IP からの頻繁なリクエストはブロックにつながる可能性があります。 プロキシ サーバーのプールを使用して IP をローテーションし、人間のトラフィック パターンを模倣します。
- CAPTCHA : これらは人間とボットを区別するように設計されています。 CAPTCHA 解決サービスを適用するか、可能な場合は手動入力を選択します。
- レート制限: レート制限に引っかからないようにするには、リクエスト レートを調整し、リクエスト間にランダムな遅延を実装します。
- ユーザー エージェント: Web サイトは既知のスクレーパー ユーザー エージェントをブロックする可能性があります。 ユーザー エージェントをローテーションして、さまざまなブラウザーやデバイスを模倣します。
これらの課題を克服するには、必要なデータに効率的にアクセスしながら、Web サイトの利用規約を尊重する洗練されたアプローチが必要です。
CAPTCHA とハニーポット トラップの処理
Web スクレイパーは、人間のユーザーとボットを区別するために設計された CAPTCHA の課題に遭遇することがよくあります。 これを克服するには、次のことが必要です。
- 人間または AI の能力を活用した CAPTCHA 解決サービスを利用します。
- 人間の動作を模倣するために遅延を実装し、リクエストをランダム化します。
ハニーポット トラップの場合、ユーザーには見えませんが、自動化されたスクリプトをトラップします。
- Web サイトのコードを注意深く調べて、隠しリンクとの相互作用を回避してください。
- 目立たないようにするために、あまり攻撃的ではないスクレイピング手法を採用します。
開発者は、Web サイトの利用規約とユーザー エクスペリエンスを尊重しながら、効率性の倫理的なバランスを取る必要があります。

スクレイピングの効率と速度の最適化
Web スクレイピング プロセスは、効率と速度の両方を最適化することで改善できます。 このドメインの課題を克服するには:
- マルチスレッドを利用して同時データ抽出を可能にし、スループットを向上させます。
- ヘッドレス ブラウザを活用して、グラフィック コンテンツの不必要な読み込みを排除し、実行を高速化します。
- スクレイピング コードを最適化して、遅延を最小限に抑えて実行します。
- 安定したペースを維持しながら IP 禁止を防ぐために、適切なリクエスト スロットルを実装します。
- 静的コンテンツをキャッシュしてダウンロードの繰り返しを回避し、帯域幅と時間を節約します。
- 非同期プログラミング手法を採用して、ネットワーク I/O 操作を最適化します。
- 効率的なセレクターと解析ライブラリを選択して、DOM 操作のオーバーヘッドを削減します。
これらの戦略を組み込むことで、Web スクレーパーは操作上の中断を最小限に抑えながら堅牢なパフォーマンスを実現できます。
データの抽出と解析
Web スクレイピングには正確なデータ抽出と解析が必要であり、明確な課題が存在します。 これらに対処する方法は次のとおりです。
- BeautifulSoup や Scrapy など、さまざまな HTML 構造を処理できる堅牢なライブラリを使用します。
- 正規表現を慎重に実装して、特定のパターンを正確にターゲットにします。
- Selenium などのブラウザ自動化ツールを活用して、JavaScript を多用する Web サイトと対話し、抽出前にデータが確実にレンダリングされるようにします。
- XPath または CSS セレクターを利用して、DOM 内のデータ要素を正確に特定します。
- 新しいコンテンツをロードするメカニズム (URL パラメーターの更新や AJAX 呼び出しの処理など) を識別して操作することにより、ページネーションと無限スクロールを処理します。
Webスクレイピングの技術を習得する
Web スクレイピングは、データ主導の世界では非常に貴重なスキルです。 動的コンテンツからボット検出に至るまで、技術的な課題を克服するには、忍耐力と適応力が必要です。 Web スクレイピングを成功させるには、次のアプローチを組み合わせる必要があります。
- インテリジェントなクローリングを実装して、Web サイトのリソースを尊重し、検出されることなく移動します。
- 高度な解析を利用して動的コンテンツを処理し、変更に対して堅牢なデータ抽出を保証します。
- CAPTCHA 解決サービスを戦略的に採用して、データ フローを中断することなくアクセスを維持します。
- IP アドレスとリクエスト ヘッダーを慎重に管理して、スクレイピング アクティビティを偽装します。
- パーサー スクリプトを定期的に更新することで、Web サイト構造の変更に対処します。
これらのテクニックをマスターすることで、Web クローリングの複雑さを巧みにナビゲートし、貴重なデータの膨大な保存を解除することができます。
大規模なスクレイピング プロジェクトの管理
大規模な Web スクレイピング プロジェクトには、効率とコンプライアンスを確保するための堅牢な管理が必要です。 Web スクレイピング サービス プロバイダーと提携すると、次のような利点があります。

スクレイピング プロジェクトを専門家に委託すると、結果を最適化し、社内チームの技術的負担を最小限に抑えることができます。
よくある質問
Webスクレイピングの制限は何ですか?
Web スクレイピングは、運用に組み込む前に考慮する必要がある特定の制約に直面しています。 法的に、一部の Web サイトでは利用規約または robot.txt ファイルによるスクレイピングを禁止しています。 これらの制限を無視すると、重大な結果が生じる可能性があります。
技術的には、Web サイトは CAPTCHA、IP ブロック、ハニー ポットなどのスクレイピングに対する対策を導入して、不正アクセスを防止する場合があります。 動的レンダリングやソースが頻繁に更新されるため、抽出されたデータの精度も問題になる可能性があります。 最後に、Web スクレイピングには技術的なノウハウ、リソースへの投資、継続的な努力が必要であり、特に技術者以外の人にとっては課題が生じます。
データスクレイピングが問題となるのはなぜですか?
問題は主に、必要な許可や倫理的行為なしにデータスクレイピングが行われた場合に発生します。 機密情報の抽出はプライバシー規範に違反し、個人の利益を保護するために定められた法令に違反します。
スクレイピングを過剰に使用すると、ターゲットサーバーに負担がかかり、パフォーマンスと可用性に悪影響を及ぼします。 知的財産の盗難は、侵害された当事者によって著作権侵害訴訟が起こされる可能性があるため、違法なスクレイピングから生じるさらに別の懸念事項となります。
したがって、データ スクレイピング タスクを実行する際には、ポリシー規定を遵守し、倫理基準を遵守し、必要に応じて同意を求めることが引き続き重要です。
Web スクレイピングが不正確になる可能性があるのはなぜですか?
Web スクレイピングでは、専用のソフトウェアを使用して Web サイトからデータを自動的に抽出しますが、さまざまな要因により完全な正確性が保証されるわけではありません。 たとえば、Web サイトの構造が変更されると、スクレイパー ツールが誤動作したり、誤った情報が取得されたりする可能性があります。
さらに、特定の Web サイトでは CAPTCHA テスト、IP ブロック、JavaScript レンダリングなどのスクレイピング対策が実装されており、データの欠落や歪みにつながります。 場合によっては、作成中の開発者の見落としが最適でない結果につながることもあります。
ただし、熟練した Web スクレイピング サービス プロバイダーと提携することで、Web サイトのレイアウトが変化しても高精度レベルを維持できる回復力と機敏なスクレーパーを構築するために必要なノウハウと資産がもたらされるため、精度を高めることができます。 熟練した専門家がこれらのスクレイパーを実装前に綿密にテストおよび検証し、抽出プロセス全体を通じて正確さを保証します。
Webスクレイピングは面倒ですか?
実際、Web スクレイピング活動に取り組むことは、特にコーディングの専門知識やデジタル プラットフォームの理解が不足している人にとっては、骨の折れる、困難な作業であることがわかります。 このようなタスクには、オーダーメイドのコードの作成、欠陥のあるスクレーパーの修正、サーバー アーキテクチャの管理、対象の Web サイト内で発生する変更の把握が必要であり、これらすべてにかなりの技術的能力が必要であり、時間の支出という点で多大な投資が必要となります。
過去の基本的な Web スクレイピング作業を拡張することは、規制遵守、帯域幅管理、分散コンピューティング システムの実装に関する考慮事項を考慮すると、徐々に複雑になっていきます。
対照的に、専門的な Web スクレイピング サービスを選択すると、ユーザー固有の要求に従って設計された既製のサービスにより、関連する負担が大幅に軽減されます。 その結果、顧客は収集したデータの活用に主に集中し、システムの最適化、リソースの割り当て、法的問い合わせへの対応を担当する熟練した開発者とIT専門家からなる専門チームに収集のロジスティクスを任せることになり、Webスクレイピングの取り組みに関連する全体的な退屈な作業が大幅に軽減されます。