
Python Web クローラー – ステップバイステップのチュートリアル
公開: 2023-12-07Web クローラーは、データ収集と Web スクレイピングの世界における魅力的なツールです。 これらは、Web をナビゲートしてデータを収集するプロセスを自動化し、そのデータは検索エンジンのインデックス作成、データ マイニング、競合分析などのさまざまな目的に使用できます。 このチュートリアルでは、Web データを処理する際のシンプルさと強力な機能で知られる言語である Python を使用して、基本的な Web クローラーを構築するための有益な作業に着手します。
Python はライブラリの豊富なエコシステムを備えており、Web クローラーを開発するための優れたプラットフォームを提供します。 あなたが新進の開発者であっても、データ愛好家であっても、あるいは単に Web クローラーがどのように機能するかに興味がある人であっても、このステップバイステップのガイドは、Web クローリングの基本を紹介し、独自のクローラーを作成するスキルを身につけることを目的としています。 。
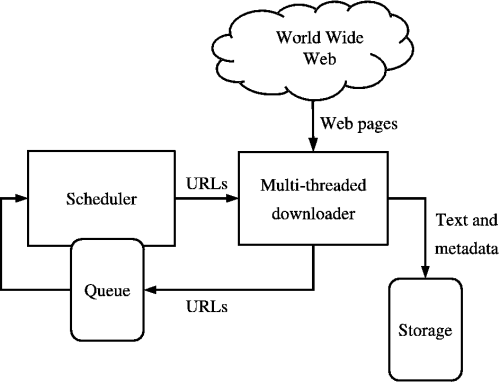
出典: https://medium.com/kariyertech/web-crawling-general-perspective-713971e9c659
Python Web クローラー – Web クローラーの構築方法
ステップ 1: 基本を理解する
Web クローラーはスパイダーとも呼ばれ、体系的かつ自動化された方法で World Wide Web を閲覧するプログラムです。 クローラーには、そのシンプルさと強力なライブラリのため Python を使用します。
ステップ 2: 環境をセットアップする
Python のインストール: Python がインストールされていることを確認します。 python.org からダウンロードできます。
ライブラリのインストール: HTTP リクエストを行うためのリクエストと、HTML を解析するための bs4 からの BeautifulSoup が必要です。 pip を使用してインストールします。
pip インストール リクエスト pip install beautifulsoup4
ステップ 3: 基本的なクローラーを作成する
ライブラリのインポート:
bs4 import BeautifulSoup からのインポートリクエスト
Web ページを取得する:
ここでは、Web ページのコンテンツを取得します。 「URL」をクロールする Web ページに置き換えます。
URL = 'URL' 応答 =requests.get(url) コンテンツ =response.content
HTML コンテンツを解析します。
スープ = BeautifulSoup(content, 'html.parser')
情報の抽出:
たとえば、すべてのハイパーリンクを抽出するには、次のようにします。
Soup.find_all('a') のリンクの場合: print(link.get('href'))
ステップ 4: クローラーを拡張する
相対 URL の処理:
相対 URL を処理するには、urljoin を使用します。
urllib.parse から urljoin をインポート
同じページを 2 回クロールしないようにします。
冗長性を避けるために、訪問した URL のセットを維持します。
遅延の追加:
敬意を持ったクロールには、リクエスト間の遅延が含まれます。 time.sleep() を使用します。
ステップ 5: Robots.txt を尊重する
クローラーが、サイトのどの部分をクロールすべきでないのかを示す Web サイトの robots.txt ファイルを尊重していることを確認してください。
ステップ 6: エラー処理
Try-Except ブロックを実装して、接続タイムアウトやアクセス拒否などの潜在的なエラーを処理します。
ステップ 7: さらに深くなる
クローラーを強化して、フォームの送信や JavaScript のレンダリングなど、より複雑なタスクを処理することができます。 JavaScript を多用する Web サイトの場合は、Selenium の使用を検討してください。
ステップ 8: データを保存する
クロールしたデータを保存する方法を決定します。 オプションには、単純なファイル、データベース、さらにはサーバーへのデータの直接送信も含まれます。
ステップ9: 倫理的であること
- サーバーに過負荷をかけないでください。 リクエストに遅延を追加します。
- Web サイトの利用規約に従ってください。
- 許可なく個人データを収集したり保存したりしないでください。
ブロックされることは、Web クローリングの際、特に自動アクセスを検出してブロックするための対策が講じられている Web サイトを扱う場合によくある課題です。 Python でこの問題を解決するのに役立ついくつかの戦略と考慮事項を次に示します。
ブロックされる理由を理解する
頻繁なリクエスト:同じ IP からのリクエストが急速に繰り返されると、ブロックがトリガーされる可能性があります。
人間以外のパターン:ボットは、ページにあまりにも早くアクセスしたり、予測可能な順序でページにアクセスしたりするなど、人間の閲覧パターンとは異なる動作を示すことがよくあります。

ヘッダーの不適切な管理: HTTP ヘッダーが欠落しているか正しくない場合、リクエストが疑わしいものに見える可能性があります。
robots.txt の無視:サイトの robots.txt ファイル内のディレクティブに従わないと、ブロックが発生する可能性があります。
ブロックされないようにするための戦略
robots.txt を尊重する: Web サイトの robots.txt ファイルを常に確認して準拠してください。 これは倫理的な行為であり、不必要なブロックを防ぐことができます。
ユーザー エージェントのローテーション: Web サイトは、ユーザー エージェントを通じてユーザーを識別できます。 回転させることで、ボットとしてフラグが立てられるリスクが軽減されます。 これを実装するには、fake_useragent ライブラリを使用します。
from fake_useragent import UserAgent ua = UserAgent() headers = {'User-Agent': ua.random}
遅延の追加: リクエスト間に遅延を実装すると、人間の動作を模倣できます。 time.sleep() を使用して、ランダムまたは固定の遅延を追加します。
import time time.sleep(3) # 3秒間待機します
IP ローテーション: 可能であれば、プロキシ サービスを使用して IP アドレスをローテーションします。 これには無料と有料の両方のサービスが利用可能です。
セッションの使用: Python の request.Session オブジェクトは、一貫した接続を維持し、リクエスト間でヘッダーや Cookie などを共有するのに役立ち、クローラーを通常のブラウザー セッションのように見せることができます。
request.Session() をセッションとして使用: session.headers = {'User-Agent': ua.random} 応答 = session.get(url)
JavaScript の処理: 一部の Web サイトでは、コンテンツの読み込みに JavaScript に大きく依存しています。 Selenium や Puppeteer などのツールは、JavaScript レンダリングを含め、実際のブラウザーを模倣できます。
エラー処理: ブロックやその他の問題を適切に管理し、対応するために、堅牢なエラー処理を実装します。
倫理的配慮
- ウェブサイトの利用規約を常に尊重してください。 サイトが Web スクレイピングを明示的に禁止している場合は、従うことが最善です。
- クローラーが Web サイトのリソースに与える影響に注意してください。 サーバーに過負荷がかかると、サイト所有者に問題が発生する可能性があります。
高度なテクニック
- Web スクレイピング フレームワーク: さまざまなクロールの問題を処理する機能が組み込まれている、Scrapy のようなフレームワークの使用を検討してください。
- CAPTCHA 解決サービス: CAPTCHA の課題があるサイト向けに、CAPTCHA を解決できるサービスがありますが、その使用には倫理的な懸念が生じます。
Python での Web クローリングのベスト プラクティス
Web クローリング活動に従事するには、技術的な効率と倫理的責任のバランスが必要です。 Web クローリングに Python を使用する場合は、データとデータの取得元の Web サイトを尊重するベスト プラクティスに従うことが重要です。 Python での Web クローリングに関する重要な考慮事項とベスト プラクティスをいくつか示します。
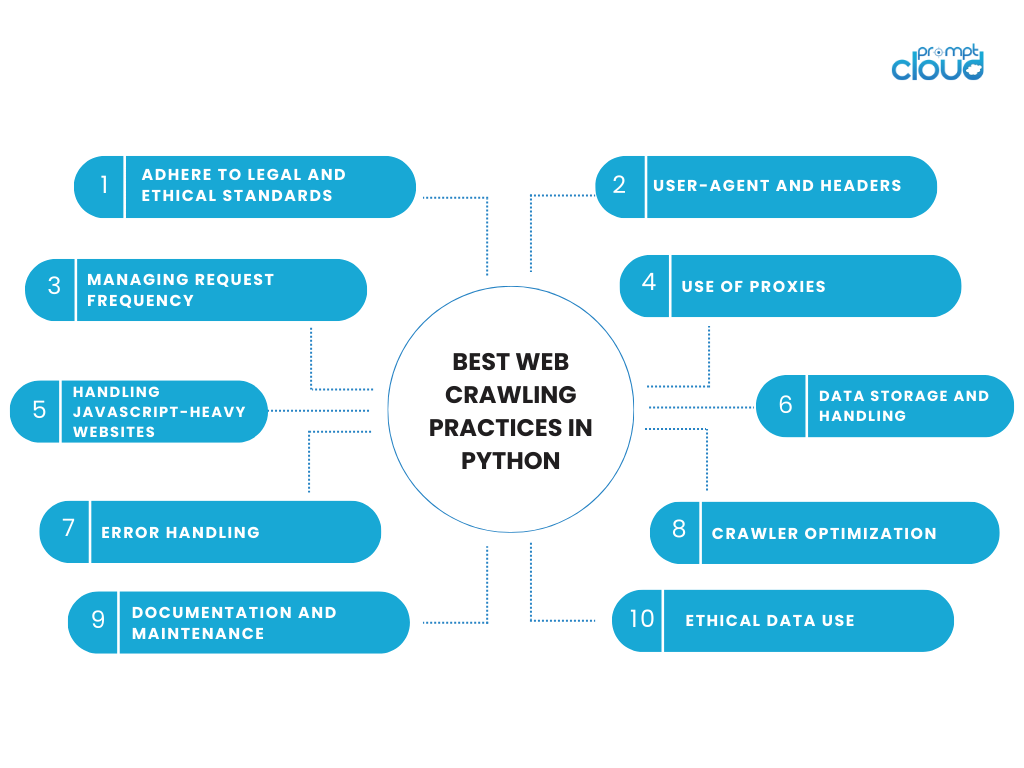
法的および倫理的基準の遵守
- robots.txt を尊重する: Web サイトの robots.txt ファイルを常に確認してください。 このファイルには、Web サイト所有者がクロールされたくないサイト領域の概要が記載されています。
- 利用規約に従う:多くの Web サイトでは、利用規約に Web スクレイピングに関する条項が含まれています。 これらの条件を遵守することは、倫理的にも法的にも賢明です。
- サーバーの過負荷を避ける: Web サイトのサーバーに過剰な負荷がかからないよう、適度なペースでリクエストを実行します。
ユーザーエージェントとヘッダー
- 自分自身を識別する:連絡先情報またはクロールの目的を含むユーザー エージェント文字列を使用します。 この透明性により信頼を築くことができます。
- ヘッダーを適切に使用する: HTTP ヘッダーを適切に構成すると、ブロックされる可能性を減らすことができます。 ユーザーエージェント、受け入れ言語などの情報を含めることができます。
リクエスト頻度の管理
- 遅延の追加:人間の閲覧パターンを模倣するために、リクエスト間に遅延を実装します。 Python の time.sleep() 関数を使用します。
- レート制限:一定期間内に Web サイトに送信するリクエストの数に注意してください。
プロキシの使用
- IP ローテーション:プロキシを使用して IP アドレスをローテーションすると、IP ベースのブロックを回避できますが、責任を持って倫理的に行う必要があります。
JavaScript を多用する Web サイトの処理
- 動的コンテンツ: JavaScript を使用してコンテンツを動的に読み込むサイトの場合、Selenium や Puppeteer (Python 用の Pyppeteer と組み合わせて) などのツールを使用すると、ブラウザーのようにページをレンダリングできます。
データの保存と処理
- データ ストレージ:データ プライバシー法と規制を考慮して、クロールされたデータを責任を持って保存します。
- データ抽出を最小限に抑える:必要なデータのみを抽出します。 絶対に必要で合法的な場合を除き、個人情報や機密情報を収集しないでください。
エラー処理
- 堅牢なエラー処理:包括的なエラー処理を実装して、タイムアウト、サーバー エラー、コンテンツの読み込み失敗などの問題を管理します。
クローラーの最適化
- スケーラビリティ:クロールされるページ数と処理されるデータ量の両方の観点から、スケールの増加に対応できるようにクローラーを設計します。
- 効率:コードを最適化して効率を高めます。 効率的なコードにより、システムとターゲット サーバーの両方の負荷が軽減されます。
文書化とメンテナンス
- ドキュメントを保存する:将来の参照やメンテナンスのために、コードとクロール ロジックをドキュメント化します。
- 定期的な更新:特にターゲット Web サイトの構造が変更された場合は、クロール コードを常に最新の状態に保ちます。
倫理的なデータの使用
- 倫理的な利用:ユーザーのプライバシーとデータ使用規範を尊重し、収集したデータを倫理的な方法で使用します。
結論は
Python で Web クローラーを構築する探求を終えるにあたり、自動データ収集の複雑さとそれに伴う倫理的考慮事項について検討してきました。 この取り組みは、当社の技術スキルを向上させるだけでなく、広大なデジタル環境における責任あるデータ処理についての理解を深めます。
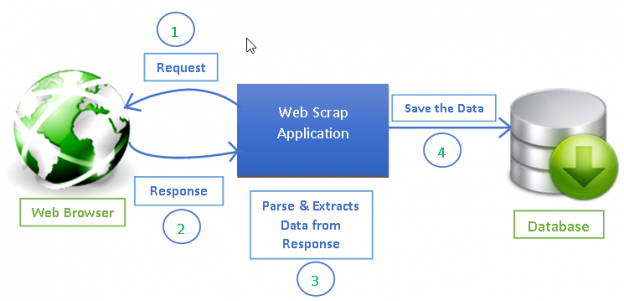
出典: https://www.datacamp.com/tutorial/making-web-crawlers-scrapy-python
ただし、Web クローラーの作成と保守は、特に特定の大規模なデータ ニーズを持つ企業にとっては、複雑で時間のかかる作業になる可能性があります。 ここで、PromptCloud のカスタム Web スクレイピング サービスが活躍します。 Web データ要件に合わせてカスタマイズされた効率的かつ倫理的なソリューションをお探しの場合、PromptCloud はお客様固有のニーズに合わせた一連のサービスを提供します。 複雑な Web サイトの処理から、クリーンで構造化されたデータの提供まで、Web スクレイピング プロジェクトが手間なく、ビジネス目標に沿ったものになることを保証します。
独自の Web クローラーを開発および管理する時間や技術的専門知識がない企業や個人にとって、このタスクを PromptCloud のような専門家にアウトソーシングすることは、状況を大きく変える可能性があります。 彼らのサービスは、時間とリソースを節約するだけでなく、法的および倫理的基準を遵守しながら、最も正確で関連性の高いデータを確実に取得できるようにします。
PromptCloud が特定のデータ ニーズにどのように対応できるかについて詳しく知りたいですか? 詳細については、sales@promptcloud.com までお問い合わせください。また、カスタム Web スクレイピング ソリューションがビジネスの推進にどのように役立つかについて話し合ってください。
Web データの動的な世界では、PromptCloud のような信頼できるパートナーを持つことでビジネスに力を与え、データ主導の意思決定において優位性を得ることができます。 データの収集と分析の領域では、適切なパートナーが大きな違いを生むことを忘れないでください。
楽しいデータハンティングを!