
Web クローラーを構築するためのステップバイステップ ガイド
公開: 2023-12-05情報が無数の Web サイトに散在するインターネットの複雑なタペストリーの中で、Web クローラーは縁の下の力持ちとして登場し、この豊富なデータを整理し、インデックスを作成し、アクセスできるように熱心に取り組んでいます。 この記事では、Web クローラーの探求に着手し、Web クローラーの基本的な仕組みを明らかにし、Web クローリングと Web スクレイピングを区別し、シンプルな Python ベースの Web クローラーを作成するためのステップバイステップ ガイドなどの実用的な洞察を提供します。 さらに深く掘り下げると、Scrapy などの高度なツールの機能が明らかになり、PromptCloud が Web クローリングを産業規模にまで高める方法がわかります。
ウェブ クローラーとは
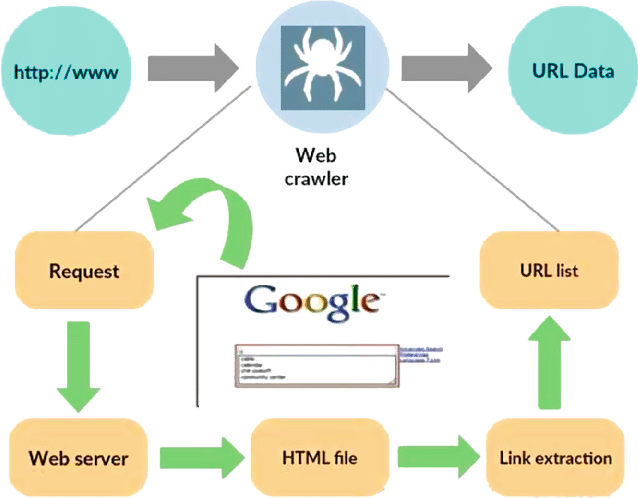
出典: https://www.researchgate.net/figure/Working-model-of-web-crawler_fig1_316089973
スパイダーまたはボットとも呼ばれる Web クローラーは、World Wide Web の広大な範囲を体系的かつ自律的にナビゲートするように設計された特殊なプログラムです。 その主な機能は、Web サイトを横断し、データを収集し、検索エンジンの最適化、コンテンツのインデックス作成、データ抽出などのさまざまな目的で情報のインデックスを作成することです。
Web クローラーの核心は、人間のユーザーのアクションを模倣しますが、そのペースははるかに高速で効率的です。 シード URL と呼ばれることが多い指定された開始点から移動を開始し、ある Web ページから別の Web ページへのハイパーリンクをたどります。 リンクをたどるこのプロセスは再帰的であるため、クローラーはインターネットのかなりの部分を探索できます。
クローラーは Web ページにアクセスすると、テキスト、画像、メタデータなどを含む関連データを体系的に抽出して保存します。 抽出されたデータは整理され、インデックスが作成されるため、検索エンジンがクエリ時に関連情報を取得してユーザーに表示することが容易になります。
Web クローラーは、Google、Bing、Yahoo などの検索エンジンの機能において極めて重要な役割を果たします。 継続的かつ体系的に Web をクロールすることで、検索エンジンのインデックスが最新の状態に保たれ、正確で関連性の高い検索結果がユーザーに提供されます。 さらに、Web クローラーは、コンテンツ集約、Web サイト監視、データ マイニングなど、他のさまざまなアプリケーションでも利用されます。
Web クローラーの有効性は、多様な Web サイト構造をナビゲートし、動的コンテンツを処理し、サイトのどの部分をクロールできるかを概説する robots.txt ファイルを通じて Web サイトによって設定されたルールを尊重する能力にかかっています。 Web クローラーがどのように動作するかを理解することは、膨大な Web 情報にアクセスして整理する上での Web クローラーの重要性を理解するための基礎となります。
Web クローラーの仕組み
スパイダーまたはボットとしても知られる Web クローラーは、World Wide Web をナビゲートする体系的なプロセスを通じて動作し、Web サイトから情報を収集します。 Web クローラーの仕組みの概要は次のとおりです。
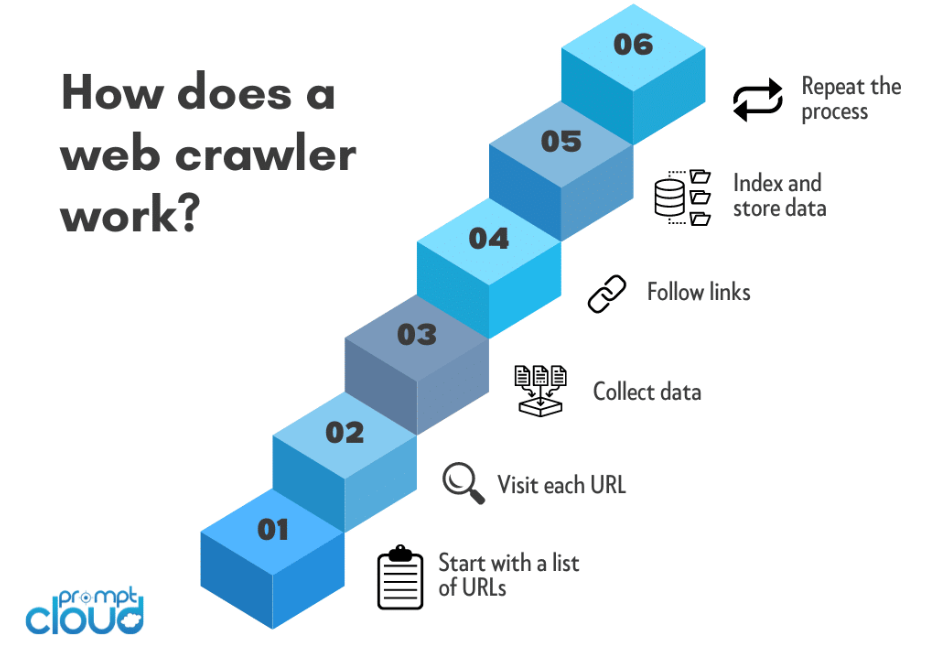
シード URL の選択:
Web クローリング プロセスは通常、シード URL から始まります。 これは、クローラーが移動を開始する最初の Web ページまたは Web サイトです。
HTTPリクエスト:
クローラーは、HTTP リクエストをシード URL に送信して、Web ページの HTML コンテンツを取得します。 このリクエストは、Web サイトにアクセスするときに Web ブラウザによって行われるリクエストに似ています。
HTML 解析:
HTML コンテンツが取得されると、クローラーはそれを解析して関連情報を抽出します。 これには、HTML コードをクローラーがナビゲートして分析できる構造化フォーマットに分解することが含まれます。
URL 抽出:
クローラーは、HTML コンテンツ内に存在するハイパーリンク (URL) を識別して抽出します。 これらの URL は、クローラーが後でアクセスする他のページへのリンクを表します。
キューとスケジューラ:
抽出された URL はキューまたはスケジューラに追加されます。 キューにより、クローラーが特定の順序で URL にアクセスできるようになり、多くの場合、新しい URL または未訪問の URL が最初に優先されます。
再帰:
クローラーはキュー内のリンクをたどり、HTTP リクエストの送信、HTML コンテンツの解析、新しい URL の抽出のプロセスを繰り返します。 この再帰的なプロセスにより、クローラーは Web ページの複数のレイヤーをナビゲートできるようになります。
データ抽出:
クローラーは Web を横断する際に、訪問した各ページから関連データを抽出します。 抽出されるデータの種類はクローラーの目的によって異なり、テキスト、画像、メタデータ、またはその他の特定のコンテンツが含まれる場合があります。
コンテンツのインデックス作成:
収集されたデータは整理され、インデックスが付けられます。 インデックス作成には、ユーザーがクエリを送信するときに情報を簡単に検索、取得、表示できるようにする構造化データベースの作成が含まれます。
Robots.txt を尊重する:
Web クローラーは通常、Web サイトの robots.txt ファイルで指定されたルールに従います。 このファイルは、サイトのどの領域をクロールできるか、どの領域を除外する必要があるかに関するガイドラインを提供します。
クロールの遅延と礼儀正しさ:
サーバーの過負荷や混乱を避けるために、クローラーには多くの場合、クロールの遅延と丁寧さのためのメカニズムが組み込まれています。 これらの対策により、クローラーは敬意を持って中断のない方法で Web サイトと対話することが保証されます。
Web クローラーは体系的に Web を移動し、リンクをたどり、データを抽出し、整理されたインデックスを構築します。 このプロセスにより、検索エンジンはクエリに基づいて正確で関連性の高い結果をユーザーに提供できるようになり、Web クローラーが現代のインターネット エコシステムの基本コンポーネントとなっています。
Web クローリングと Web スクレイピング

出典: https://research.aimultiple.com/web-crawling-vs-web-scraping/

Web クローリングと Web スクレイピングはしばしば同じ意味で使用されますが、異なる目的を果たします。 Web クローリングには、体系的に Web をナビゲートしてインデックスを付けて情報を収集することが含まれますが、Web スクレイピングは Web ページから特定のデータを抽出することに重点を置いています。 本質的に、Web クローリングは Web を探索してマッピングすることですが、Web スクレイピングは対象の情報を収集することです。
Web クローラーの構築
Python で単純な Web クローラーを構築するには、開発環境のセットアップからクローラー ロジックのコーディングまで、いくつかの手順が必要です。 以下は、Python を使用して基本的な Web クローラーを作成するのに役立つ詳細なガイドです。HTTP リクエストの作成にはリクエスト ライブラリを、HTML 解析には BeautifulSoup を利用します。
ステップ 1: 環境をセットアップする
システムに Python がインストールされていることを確認してください。 python.org からダウンロードできます。 さらに、必要なライブラリをインストールする必要があります。
pip install requests beautifulsoup4
ステップ 2: ライブラリをインポートする
新しい Python ファイル (simple_crawler.py など) を作成し、必要なライブラリをインポートします。
import requests from bs4 import BeautifulSoup
ステップ 3: クローラー関数を定義する
URL を入力として受け取り、HTTP リクエストを送信し、HTML コンテンツから関連情報を抽出する関数を作成します。
def simple_crawler(url):
# Send HTTP request to the URL
response = requests.get(url)
# Check if the request was successful (status code 200)
if response.status_code == 200:
# Parse HTML content with BeautifulSoup
soup = BeautifulSoup(response.text, 'html.parser')
# Extract and print relevant information (modify as needed)
title = soup.title.text
print(f'Title: {title}')
# Additional data extraction and processing can be added here
else:
print(f'Error: Failed to fetch {url}')
ステップ 4: クローラーをテストする
サンプル URL を指定し、simple_crawler 関数を呼び出してクローラーをテストします。
if __name__ == "__main__": sample_url = 'https://example.com' simple_crawler(sample_url)
ステップ 5: クローラーを実行する
ターミナルまたはコマンド プロンプトで Python スクリプトを実行します。
python simple_crawler.py
クローラーは、指定された URL の HTML コンテンツを取得し、解析して、タイトルを出力します。 さまざまな種類のデータを抽出するための機能を追加することで、クローラーを拡張できます。
Scrapy による Web クローリング
Scrapy を使用した Web クローリングは、効率的でスケーラブルな Web スクレイピングのために特別に設計された強力で柔軟なフレームワークへの扉を開きます。 Scrapy は、Web クローラー構築の複雑さを簡素化し、Web サイトをナビゲートし、データを抽出し、体系的に保存できるスパイダーを作成するための構造化された環境を提供します。 ここでは、Scrapy を使用した Web クローリングを詳しく見ていきます。
インストール:
始める前に、Scrapy がインストールされていることを確認してください。 以下を使用してインストールできます。
pip install scrapy
Scrapy プロジェクトの作成:
Scrapy プロジェクトを開始します。
ターミナルを開き、Scrapy プロジェクトを作成するディレクトリに移動します。 次のコマンドを実行します。
scrapy startproject your_project_name
これにより、必要なファイルを含む基本的なプロジェクト構造が作成されます。
スパイダーを定義します。
プロジェクト ディレクトリ内で、spiders フォルダーに移動し、スパイダーの Python ファイルを作成します。 スパイダー クラスを定義するには、scrapy.Spider をサブクラス化し、名前、許可されるドメイン、開始 URL などの重要な詳細を指定します。
import scrapy
class YourSpider(scrapy.Spider):
name = 'your_spider'
allowed_domains = ['example.com']
start_urls = ['http://example.com']
def parse(self, response):
# Define parsing logic here
pass
データの抽出:
セレクターの使用:
Scrapy は、HTML からデータを抽出するために強力なセレクターを利用します。 スパイダーの parse メソッドでセレクターを定義して、特定の要素をキャプチャできます。
def parse(self, response):
title = response.css('title::text').get()
yield {'title': title}
この例では、<title> タグのテキスト コンテンツを抽出します。
次のリンク:
Scrapy は、リンクをたどるプロセスを簡素化します。 他のページに移動するには、次のメソッドを使用します。
def parse(self, response):
for next_page in response.css('a::attr(href)').getall():
yield response.follow(next_page, self.parse)
スパイダーを実行する:
プロジェクト ディレクトリから次のコマンドを使用してスパイダーを実行します。
scrapy crawl your_spider
Scrapy はスパイダーを開始し、リンクをたどり、parse メソッドで定義された解析ロジックを実行します。
Scrapy を使用した Web クローリングは、複雑なスクレイピング タスクを処理するための堅牢で拡張可能なフレームワークを提供します。 そのモジュール式アーキテクチャと組み込み機能により、高度な Web データ抽出プロジェクトに携わる開発者にとって好ましい選択肢となっています。
大規模な Web クローリング
大規模な Web クローリングには、特に多数の Web サイトにまたがる膨大な量のデータを扱う場合に特有の課題が生じます。 PromptCloud は、Web クローリング プロセスを大規模に合理化し、最適化するように設計された特殊なプラットフォームです。 PromptCloud が大規模な Web クローリング イニシアチブの処理をどのように支援できるかは次のとおりです。
- スケーラビリティ
- データの抽出と強化
- データの品質と正確性
- インフラストラクチャ管理
- 使いやすさ
- コンプライアンスと倫理
- リアルタイムの監視とレポート
- サポートとメンテナンス
PromptCloud は、Web クローリングを大規模に実行しようとしている組織や個人のための堅牢なソリューションです。 このプラットフォームは、大規模なデータ抽出に関連する主要な課題に対処することで、Web クローリングの取り組みの効率、信頼性、管理性を強化します。
要約すれば
Web クローラーは、広大なデジタル環境において縁の下の力持ちとして存在し、Web を熱心にナビゲートして情報のインデックス付け、収集、整理を行います。 Web クローリング プロジェクトの規模が拡大するにつれて、PromptCloud がソリューションとして介入し、スケーラビリティ、データ強化、倫理コンプライアンスを提供して大規模な取り組みを合理化します。 sales@promptcloud.comまでご連絡ください。