
LLM 推論最適化のための GPU アーキテクチャを理解する
公開: 2024-04-02LLM の概要と GPU 最適化の重要性
自然言語処理 (NLP) が進歩した今日の時代では、大規模言語モデル (LLM) が、テキスト生成から質問応答や要約に至るまで、無数のタスクのための強力なツールとして登場しました。 これらは、次に考えられるトークン生成器以上のものです。 ただし、これらのモデルの複雑さとサイズの増大により、計算効率とパフォーマンスの点で大きな課題が生じています。
このブログでは、GPU アーキテクチャの複雑さを掘り下げ、さまざまなコンポーネントが LLM 推論にどのように寄与するかを調査します。 メモリ帯域幅やテンソル コアの使用率などの主要なパフォーマンス メトリクスについて説明し、さまざまな GPU カードの違いを説明します。これにより、大規模な言語モデルのタスク用のハードウェアを選択する際に、情報に基づいた意思決定ができるようになります。
NLP タスクが増大し続ける計算リソースを必要とする急速に進化する状況では、LLM 推論のスループットを最適化することが最も重要です。 GPU 最適化技術を通じて LLM の可能性を最大限に引き出し、パフォーマンスを効果的に向上させるさまざまなツールを詳しく掘り下げるこの旅に参加してください。
LLM のための GPU アーキテクチャの要点 – GPU の内部構造を理解する
GPU は、高効率な並列計算を実行するという性質上、すべての深層学習タスクを実行するための最適なデバイスとなるため、推論段階で発生する根本的なボトルネックを理解するために、GPU アーキテクチャの概要を理解することが重要です。 Nvidia カードは、NVIDIA が開発した独自の並列コンピューティング プラットフォームと API である CUDA (Compute Unified Device Architecture) により推奨されます。これにより、開発者は C プログラミング言語でスレッドレベルの並列処理を指定でき、GPU の仮想命令セットと並列処理に直接アクセスできます。計算要素。
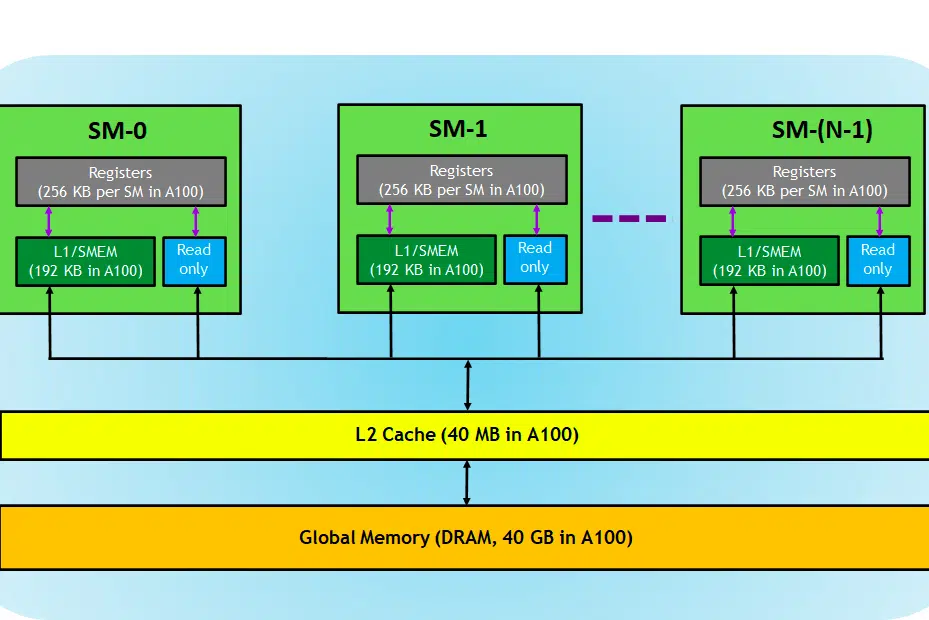
コンテキストとして、説明に NVIDIA カードを使用しました。これは、すでに述べたように、NVIDIA カードがディープ ラーニング タスクに広く好まれており、Tensor コアなど他の用語がそれに当てはまるものはほとんどないためです。
GPU カードを見てみましょう。この画像では、GPU デバイスの 3 つの主要な部分と (もう 1 つの主要な隠れた部分) を見ることができます。
- SM (ストリーミング マルチプロセッサ)
- L2キャッシュ
- メモリ帯域幅
- グローバルメモリ(DRAM)
CPU と RAM が連携して動作するのと同じように、RAM はデータを保存する場所 (つまりメモリ) であり、CPU はタスクを処理する場所 (つまり プロセス) です。 GPU では、高帯域幅グローバル メモリ (DRAM) がメモリにロードされるモデル (LLAMA 7B など) の重みを保持し、必要に応じてこれらの重みが計算のために処理ユニット (つまり SM プロセッサ) に転送されます。
ストリーミングマルチプロセッサ
ストリーミング マルチプロセッサ (SM) は、CUDA コア (NVIDIA による独自の並列コンピューティング プラットフォーム) と呼ばれる小さな実行ユニットと、命令のフェッチ、デコード、スケジューリング、およびディスパッチを担当する追加の機能ユニットの集合です。 各 SM は独立して動作し、独自のレジスタ ファイル、共有メモリ、L1 キャッシュ、およびテクスチャ ユニットを含みます。 SM は高度に並列化されており、数千のスレッドを同時に処理できます。これは、GPU コンピューティング タスクで高いスループットを達成するために不可欠です。 プロセッサのパフォーマンスは通常、FLOPS という単位で測定されます。 毎秒実行できるフローティング操作の数。
ディープ ラーニング タスクは主にテンソル演算、つまり行列と行列の乗算で構成されます。nvidia は、これらのテンソル演算を高効率な方法で実行するように特別に設計されたテンソル コアを新世代の GPU に導入しました。 前述したように、ディープ ラーニング タスクに関しては Tensor コアが役立ちます。CUDA コアの代わりに Tensor コアをチェックして、GPU が LLM のトレーニング/推論をどれだけ効率的に実行できるかを判断する必要があります。
L2キャッシュ
L2 キャッシュは、システム内のメモリ アクセスとデータ転送効率を最適化することを目的とした SM 間で共有される高帯域幅メモリです。 これは、DRAM と比較して、処理ユニット (ストリーミング マルチプロセッサなど) の近くに常駐する、小型で高速なタイプのメモリです。 メモリ要求ごとに低速の DRAM にアクセスする必要性が減り、全体的なメモリ アクセス効率が向上します。
メモリ帯域幅
したがって、パフォーマンスは、重みをメモリからプロセッサにどれだけ速く転送できるか、およびプロセッサが与えられた計算をどれだけ効率的かつ迅速に処理できるかによって決まります。
コンピューティング能力がメモリと SM 間のデータ転送速度よりも高い/速い場合、SM は処理するデータに飢え、その結果コンピューティングが十分に活用されなくなります。メモリ帯域幅が消費速度よりも低いこの状況は、メモリバウンドフェーズとして知られています。 。 これは推論プロセスにおける主なボトルネックであるため、注意することが非常に重要です。
逆に、計算の処理に時間がかかっており、計算のためにキューに入れられているデータが増えている場合、この状態は計算に依存したフェーズになります。
GPU を最大限に活用するには、発生する計算を可能な限り効率的に実行しながら、計算に制約された状態にする必要があります。
DRAMメモリ
DRAM は GPU のプライマリ メモリとして機能し、計算に必要なデータと命令を保存するための大規模なメモリ プールを提供します。 通常、高速アクセスを可能にする複数のメモリ バンクとチャネルを備えた階層構造になっています。
推論タスクの場合、GPU の DRAM によってロードできるモデルの大きさが決まり、計算 FLOPS と帯域幅によって取得できるスループットが決まります。

LLM タスク用の GPU カードの比較
テンソル コアの数、帯域幅速度に関する情報を取得するには、GPU メーカーがリリースしたホワイトペーパーを参照してください。 ここに例を示します。
| RTX A6000 | RTX4090 | RTX3090 | |
| メモリー容量 | 48GB | 24GB | 24GB |
| メモリの種類 | GDDR6 | GDDR6X | |
| 帯域幅 | 768.0GB/秒 | 1008GB/秒 | 936.2GB/秒 |
| CUDAコア/GPU | 10752 | 16384 | 10496 |
| テンソルコア | 336 | 512 | 328 |
| L1キャッシュ | 128 KB (SM あたり) | 128 KB (SM あたり) | 128 KB (SM あたり) |
| FP16 非テンソル | 38.71 TFLOPS (1:1) | 82.6 | 35.58 TFLOPS (1:1) |
| FP32 非テンソル | 38.71 TFLOPS | 82.6 | 35.58 TFLOPS |
| FP64 非テンソル | 1,210 GFLOPS (1:32) | 556.0 GFLOPS (1:64) | |
| FP16 Accumulate を使用したピーク FP16 Tensor TFLOPS | 154.8/309.6 | 330.3/660.6 | 142/284 |
| FP32 Accumulate を使用したピーク FP16 Tensor TFLOPS | 154.8/309.6 | 165.2/330.4 | 71/142 |
| FP32 でのピーク BF16 テンソル TFLOPS | 154.8/309.6 | 165.2/330.4 | 71/142 |
| ピーク TF32 テンソル TFLOPS | 77.4/154.8 | 82.6/165.2 | 35.6/71 |
| ピーク INT8 テンソル TOPS | 309.7/619.4 | 660.6/1321.2 | 284/568 |
| ピーク INT4 テンソル TOPS | 619.3/1238.6 | 1321.2/2642.4 | 568/1136 |
| L2キャッシュ | 6MB | 72MB | 6MB |
| メモリバス | 384ビット | 384ビット | 384ビット |
| TMU | 336 | 512 | 328 |
| ROP | 112 | 176 | 112 |
| SM カウント | 84 | 128 | 82 |
| RTコア | 84 | 128 | 82 |
ここでは、FLOPS が特に Tensor 演算について言及されていることがわかります。このデータは、さまざまな GPU カードを比較し、ユースケースに適したカードを最終リストに出すのに役立ちます。 表から、A6000 は 4090 の 2 倍のメモリを備えていますが、テンソル フロップとメモリ帯域幅は数値的には 4090 の方が優れているため、大規模な言語モデルの推論に対してより強力です。
さらに読む: 100 秒でわかる Nvidia CUDA
結論
急速に進歩している NLP 分野では、推論タスクのための大規模言語モデル (LLM) の最適化が重要な焦点となっています。 これまで説明してきたように、GPU のアーキテクチャは、これらのタスクで高いパフォーマンスと効率を達成する上で極めて重要な役割を果たします。 ストリーミング マルチプロセッサ (SM)、L2 キャッシュ、メモリ帯域幅、DRAM などの GPU の内部コンポーネントを理解することは、LLM 推論プロセスの潜在的なボトルネックを特定するために不可欠です。
さまざまな NVIDIA GPU カード (RTX A6000、RTX 4090、RTX 3090) を比較すると、特にメモリ サイズ、帯域幅、CUDA コアと Tensor コアの数などの点で大きな違いがあることがわかります。 これらの区別は、特定の LLM タスクにどの GPU が最適であるかを情報に基づいて決定するために重要です。 たとえば、RTX A6000 はより大きなメモリ サイズを提供しますが、RTX 4090 は Tensor FLOPS とメモリ帯域幅の点で優れており、要求の厳しい LLM 推論タスクにとってより強力な選択肢となります。
LLM 推論を最適化するには、GPU の計算能力と当面の LLM タスクの特定の要件の両方を考慮したバランスの取れたアプローチが必要です。 適切な GPU を選択するには、メモリ容量、処理能力、帯域幅の間のトレードオフを理解し、GPU がボトルネックになることなくモデルの重みを効率的に処理し、計算を実行できるようにする必要があります。 NLP の分野が進化し続ける中、大規模言語モデルで可能なことの限界を押し広げたいと考えている人にとって、最新の GPU テクノロジとその機能に関する情報を常に入手することが最も重要になります。
使用される用語
- スループット:
推論の場合、スループットは、一定期間内に処理されるリクエスト/プロンプトの数の尺度です。 スループットは通常、次の 2 つの方法で測定されます。
- 1 秒あたりのリクエスト数 (RPS) :
- RPS は、モデルが 1 秒以内に処理できる推論リクエストの数を測定します。 推論リクエストには通常、入力データに基づいて応答または予測を生成することが含まれます。
- LLM 生成の場合、RPS は、モデルが受信プロンプトまたはクエリにどれだけ早く応答できるかを示します。 RPS 値が高いほど、リアルタイムまたはほぼリアルタイムのアプリケーションの応答性とスケーラビリティが向上していることを示します。
- 高い RPS 値を達成するには、多くの場合、複数のリクエストをまとめてバッチ処理してオーバーヘッドを軽減し、計算リソースの使用率を最大化するなど、効率的な展開戦略が必要になります。
- 1 秒あたりのトークン数 (TPS) :
- TPS は、テキスト生成中にモデルがトークン (単語またはサブワード) を処理および生成できる速度を測定します。
- LLM 生成のコンテキストでは、TPS はテキスト生成に関するモデルのスループットを反映します。 これは、モデルがどれだけ早く一貫性のある意味のある応答を生成できるかを示します。
- TPS 値が高いほど、テキスト生成が速くなり、モデルがより多くの入力データを処理し、指定された時間内でより長い応答を生成できるようになります。
- 高い TPS 値を達成するには、多くの場合、モデル アーキテクチャの最適化、計算の並列化、GPU などのハードウェア アクセラレータの活用によるトークン生成の促進が必要になります。
- レイテンシ:
LLM のレイテンシは、推論中の入力と出力の間の時間遅延を指します。 遅延を最小限に抑えることは、ユーザー エクスペリエンスを向上させ、LLM を活用したアプリケーションでのリアルタイム インタラクションを可能にするために不可欠です。 提供する必要があるサービスに基づいて、スループットとレイテンシーのバランスをとることが重要です。 リアルタイム インタラクション チャットボット/コパイロットのような場合には低遅延が望ましいですが、内部データの再処理のような大量のデータ処理の場合には必要ありません。
LLM スループットを向上させるための高度なテクニックの詳細については、こちらをご覧ください。