
R と Python を使用して BigQuery にデータをアップロードする方法
公開: 2023-06-06ウェブ分析の世界は、ユニバーサル アナリティクスがデータ処理を停止し、Google アナリティクス 4 (GA4) に置き換えられる運命の 7 月 1 日を目指して猛スピードで進み続けています。 重要な変更点の 1 つは、GA4 ではプラットフォームにデータを最大 14 か月間しか保持できないことです。 これは UA からの大きな変更ですが、その代わりに、上限まで無料で GA4 データを BigQuery にプッシュできるようになります。
BigQuery は、GA4 を超えるデータ ストレージにとって非常に便利なリソースです。 ここ数か月でこれまで以上に重要性が高まっているため、あらゆるデータ ストレージのニーズに合わせて使用を開始するのにこれまでと同様に良い時期です。 多くの場合、アップロードする前に何らかの方法でデータを操作することが望ましいでしょう。 このため、特にこの種の操作を繰り返し行う必要がある場合は、R または Python で書かれたスクリプトを使用することをお勧めします。 これらのスクリプトから直接データを BigQuery にアップロードすることもできます。このブログではまさにそれについて説明します。
R から BigQuery へのアップロード
R はデータ サイエンスにとって非常に強力な言語であり、BigQuery にデータをアップロードする場合に最も使いやすい言語です。 最初のステップは、必要なライブラリをすべてインポートすることです。 このチュートリアルでは、次のライブラリが必要です。
library(googleAuthR)
library(bigQueryR)
これらのライブラリをこれまでに使用したことがない場合は、コンソールでinstall.packages(<PACKAGE NAME>)を実行してインストールします。
次に、API を使用する際に最も注意が必要であり、常に最もイライラする部分である承認に取り組む必要があります。 幸いなことに、R ではこれは比較的簡単です。 認証資格情報を含む JSON ファイルが必要です。 これは、BigQuery と同じ場所である Google Cloud Console にあります。 まず、Google Cloud Console に移動し、[API とサービス] をクリックします。
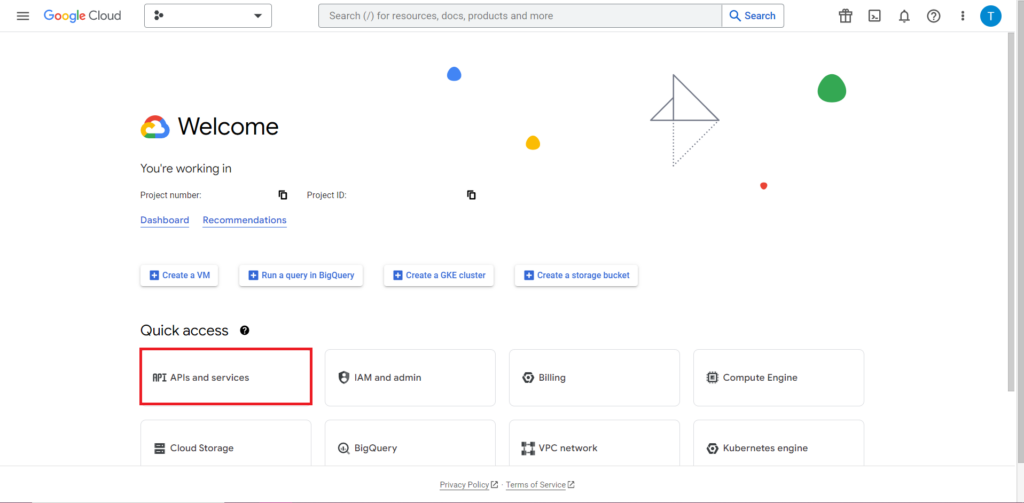
次に、サイドバーの「認証情報」をクリックします。
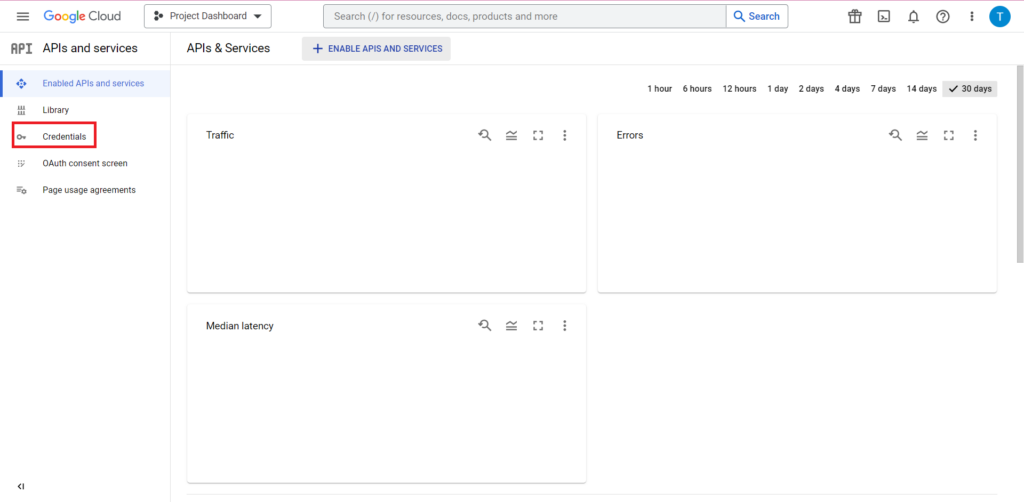
[資格情報] ページでは、既存の API キー、OAuth 2.0 クライアント ID、およびサービス アカウントを表示できます。 これには OAuth 2.0 クライアント ID が必要なので、ID に関連する行の最後にあるダウンロード ボタンをクリックするか、ページの上部にある [資格情報の作成] をクリックして新しい ID を作成します。 関連する BigQuery プロジェクトを表示および編集する権限が ID にあることを確認してください。これを行うには、サイドバーを開いて [IAM と管理者] にカーソルを合わせ、[IAM] をクリックします。 このページでは、ページ上部の [アクセスの許可] ボタンを使用して、サービス アカウントに関連プロジェクトへのアクセスを許可できます。
JSON ファイルを取得して保存したら、gar_set_client() 関数を使用してそのファイルへのパスを渡し、資格情報を設定できます。 認可のための完全なコードは以下のとおりです。
googleAuthR::gar_cache_empty()
googleAuthR::gar_set_client("C:\\Users\\Tom Brown\\Documents\\R\\APIs\\credentials.json")
bqr_auth(email = "<your email here>")
当然のことながら、gar_set_client() 関数のパスを独自の JSON ファイルへのパスに置き換え、BigQuery へのアクセスに使用するメール アドレスを bqr_auth() 関数に挿入する必要があります。
認可がすべて設定されたら、BigQuery にアップロードするデータが必要になります。 このデータをデータフレームに入れる必要があります。 この記事の目的のために、いくつかの場所と販売数を含む架空のデータを作成しますが、ほとんどの場合、.csv ファイルまたはスプレッドシートから実際のデータを読み取ることになります。 .csv ファイルからデータを読み取るには、read.csv() 関数を使用して、ファイルへのパスを引数として渡すだけです。
data <- read.csv("C:\\Users\\Tom Brown\\Documents\\Semetrical\\Blogs\\mycsv.csv")
また、データをスプレッドシートに保存している場合は、そのスプレッドシートがどこにあるかによって方法が異なります。 スプレッドシートが Google スプレッドシートに保存されている場合は、googlesheets4 ライブラリを使用してそのデータを R に読み取ることができます。
library(googlesheets4)
data <- read_sheet(ss=”<spreadsheet URL>”, sheet=”<name of tab>”)
前と同様、このパッケージを使用したことがない場合は、コードを実行する前にコンソールで install.packages(“googlesheets4”) を実行する必要があります。
スプレッドシートが Excel の場合は、tidyverse ライブラリの一部である readxl ライブラリを使用する必要があります。これを使用することをお勧めします。 これには、R でのデータ操作を非常に簡単にする膨大な数の関数が含まれています。
library(tidyverse)
data <- read_excel(“C:\\Users\\Tom Brown\\Documents\\Semetrical\\Blogs\\myxl.xlsx”)
まだ実行していない場合は、もう一度、必ず install.package(“tidyverse”) を実行してください。
最後のステップは、データを BigQuery にアップロードすることです。 このためには、BigQuery にアップロードする場所が必要です。 テーブルはデータ セット内に配置され、データ セットはプロジェクト内に配置されます。これら 3 つすべての名前が次の形式で必要になります。
bqr_upload_data(“<your project>”, “<your dataset>”, “<your table>”, <your dataframe>)
私の場合、これはコードが次のようになることを意味します。
bqr_upload_data(“my-project”, “test2”, “blogtestR”, data)
テーブルがまだ存在しない場合でも、コードによってテーブルが作成されますので、心配しないでください。 プロジェクト、データセット、テーブルの名前を上記のコード (引用符内) に挿入し、正しいデータフレームをアップロードしていることを確認することを忘れないでください。 これが完了すると、以下のように BigQuery にデータが表示されるはずです。
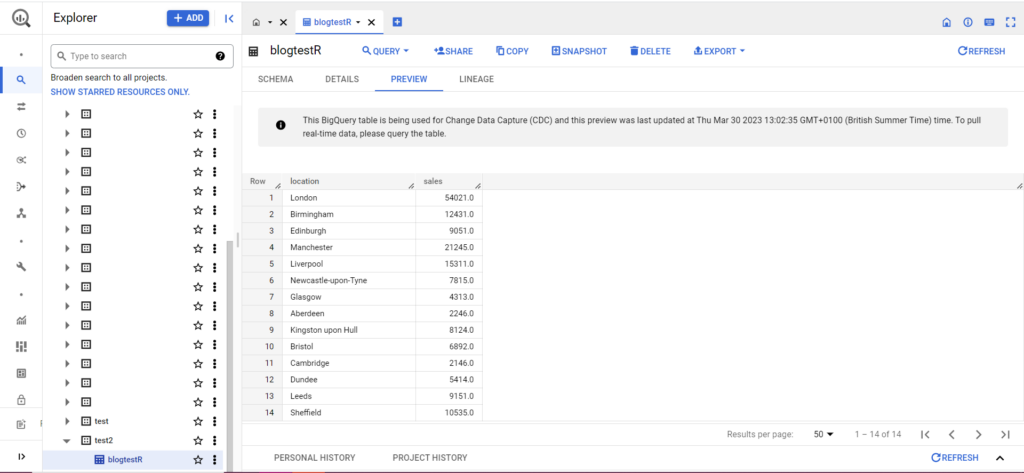
最後のステップとして、BigQuery に追加したい追加データがあるとします。 たとえば、上記のデータで、大陸のいくつかの場所を含めるのを忘れたため、BigQuery にアップロードしたいと考えていますが、既存のデータは上書きしたくないとします。 このため、bqr_upload_data には writeDisposition と呼ばれるパラメータがあります。 writeDisposition には「WRITE_TRUNCATE」と「WRITE_APPEND」の 2 つの設定があります。 前者は bqr_upload_data() にテーブル内の既存のデータを上書きするように指示し、後者は新しいデータを追加するように指示します。 したがって、この新しいデータをアップロードするには、次のように書きます。

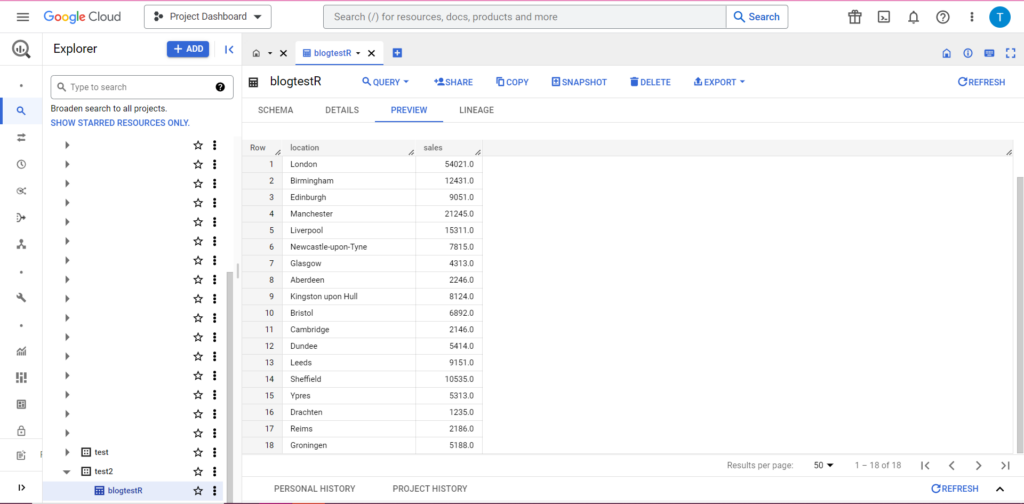
bqr_upload_data(“my-project”, “test2”, “blogtestR”, data2, writeDisposition = “WRITE_APPEND”))
そして案の定、BigQuery ではデータに新しいルームメイトが含まれていることがわかります。
Python から BigQuery にアップロードする
Python では状況が少し異なります。 もう一度、いくつかのパッケージをインポートする必要があるので、これらから始めましょう:
import pandas as pd
from google.cloud import bigquery
from google.oauth2 import service_account
認可は複雑です。 もう一度、認証情報を含む JSON ファイルが必要になります。 上記と同様に、Google Cloud Console に移動し、[API とサービス] をクリックし、サイドバーの [認証情報] をクリックします。 今回は、ページの下部に「サービス アカウント」というセクションが表示されます。
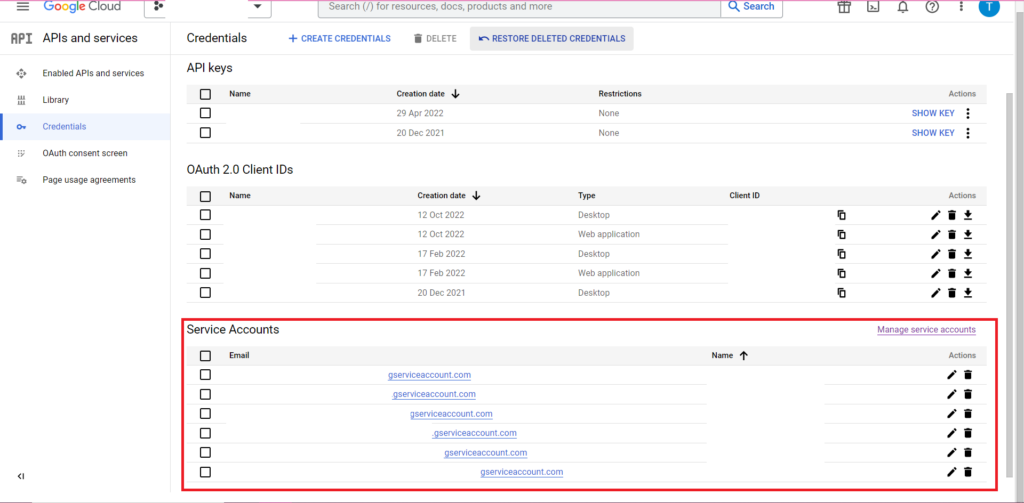
そこでサービス アカウントにキーをダウンロードするか、[サービス アカウントの管理] をクリックして、資格情報をダウンロードできる新しいキーまたは新しいサービス アカウントを作成できます。
次に、サービス アカウントに BigQuery プロジェクトにアクセスして編集する権限があることを確認する必要があります。 もう一度、サイドバーの「IAM と管理」の下にある IAM ページに移動します。そこで、ページの上部にある「アクセスの許可」ボタンを使用して、サービス アカウントに関連プロジェクトへのアクセスを許可できます。
それを整理したら、すぐに認証コードを書くことができます。
bqcreds = service_account.Credentials.from_service_account_file('myjson.json', scopes = ['https://www.googleapis.com/auth/cloud-platform'])
client = bigquery.Client(credentials=bqcreds, project=bqcreds.project_id,)
次に、データをデータフレームに取り込む必要があります。 データフレームは pandas パッケージに属しており、作成は非常に簡単です。 CSV から読み取るには、次の例に従います。
data = pd.read_csv('C:\\Users\\Tom Brown\\Documents\\Semetrical\\Blogs\\mycsv.csv')
明らかに、上記のパスを独自の CSV ファイルへのパスに置き換える必要があります。 Excel ファイルから読み取るには、次の例に従います。
data = pd.read_excel('C:\\Users\\Tom Brown\\Documents\\Semetrical\\Blogs\\myxl.xlsx', sheet_name='mytab'>
Google スプレッドシートからの読み取りは難しく、もう一度承認が必要です。 いくつかの新しいパッケージをインポートし、上記の R チュートリアルで取得した JSON 認証情報ファイルを使用する必要があります。 次のコードに従って、データを認証して読み取ることができます。
import gspread
from oauth2client.service_account import ServiceAccountCredentials
credentials = ServiceAccountCredentials.from_json_keyfile_name('myjson.json', scopes = ['https://spreadsheets.google.com/feeds'])
gc = gspead.authorize(credentials)
ss = gc.open_by_key('<spreadsheet key>')
sheet = ss.worksheet('<name of tab>')
data = pd.DataFrame(sheet.get_all_records())
データフレームにデータを入れたら、もう一度 BigQuery にアップロードします。 これは、次のテンプレートに従って行うことができます。
table_id = “<your project>.<your dataset>.<your table>”
job_config0 = bigquery.LoadJobConfig(write_disposition = 'WRITE_TRUNCATE')
job = client.load_table_from_dataframe(data, table_id, job_config=job_config0)
job.result()
例として、以前に作成したデータをアップロードするために作成したコードを次に示します。
table_
job_config0 = bigquery.LoadJobConfig(write_disposition = 'WRITE_TRUNCATE')
job = client.load_table_from_dataframe(data, table_id, job_config=job_config0)
job.result()
これが完了すると、データはすぐに BigQuery に表示されるはずです。
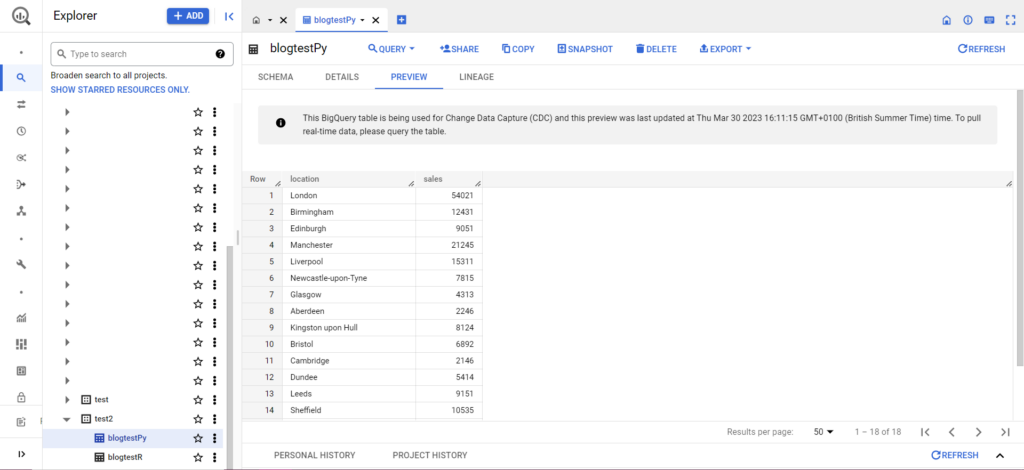
これらの関数を使いこなせば、さらに多くのことができるようになります。 分析設定をより細かく制御したい場合は、Semetrical がお手伝いします。 データを最大限に活用する方法の詳細については、ブログをご覧ください。 または、分析に関するあらゆるサポートについて詳しく知りたい場合は、Web Analytics にアクセスして、当社がどのようにお手伝いできるかをご確認ください。