
データ抽出とは: 初心者ガイド
公開: 2023-11-07データが通貨と同じくらい価値のある時代では、このデータを効率的に抽出できる機能が競合他社との差別化を図ることができます。 データ抽出は単なる技術的なプロセスではありません。 これは戦略的なものであり、適切に実行すれば、より賢明なビジネス上の意思決定と堅実な成長につながる洞察を明らかにすることができます。 このブログ投稿では、データ抽出の内容、理由、方法について詳しく説明し、その可能性を最大限に活用するための知識を提供します。
データ抽出とは
データ抽出は、データベース、Web サイト、ドキュメント、画像などのさまざまなソースから構造化データまたは非構造化データを取得するプロセスです。その後、このデータはスプレッドシートやデータベースなど、より管理しやすく使用可能な形式に変換されます。 目標は、分析やビジネス インテリジェンスにアクセスできるようにしながら、その意味を保持する方法でこの情報を収集することです。
出典: https://papersoft-dms.com/
データ抽出が重要な理由
- 情報に基づいた意思決定:抽出されたデータは、傾向を明らかにし、結果を予測し、戦略的意思決定を導くことができる分析の基盤を提供します。
- 効率:データ抽出プロセスを自動化すると、時間とリソースが節約され、手動エラーや冗長性が排除されます。
- 統合:異なるソースからのデータを統合して、運用の全体的なビューを提供します。
- 競争上の優位性:関連データへの迅速なアクセスは、企業が競争に打ち勝つために必要な優位性となります。
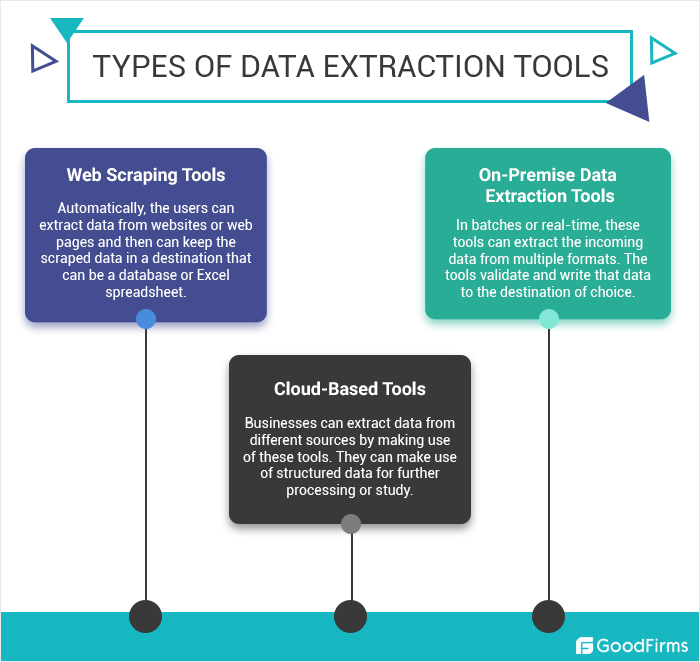
データ抽出の種類
私たちが住む情報過多の世界では、さまざまなソースからデータを効率的に抽出できる機能が非常に貴重です。 データ抽出プロセスは、方法論だけでなく、アプリケーションも異なります。 データ抽出の種類を理解すると、データのニーズに適した手法を選択するのに役立ちます。
1. 手動データ抽出
手動データ抽出は最も基本的な形式であり、物理的またはデジタル ソースからデータを収集するために人間の入力が必要です。 この方法は多くの場合時間がかかり、エラーが発生しやすくなりますが、人間の判断が必要な複雑な情報を扱う場合には便利です。
2. 自動データ抽出
このタイプでは、ソフトウェアとツールを利用してデータを自動的に収集して処理するため、プロセスが大幅に高速化され、エラーの可能性が軽減されます。
3. Webデータ抽出(Webスクレイピング)
Web スクレイピングは、Web サイトからデータを抽出するために使用される技術です。 これは、人間の Web サーフィンを模倣してオンライン ソースから特定の情報を収集するソフトウェアを通じて行われます。
4. 構造化データの抽出
このタイプは、データベースやスプレッドシートなどの構造化された形式で編成され、データに一貫性があり、特定のスキーマに従っているデータの取得を指します。
5. 非構造化データの抽出
非構造化データ抽出では、電子メール、PDF、マルチメディアなど、特定の形式や構造に従っていないデータを処理します。
6. 半構造化データの抽出
半構造化データの抽出は、リレーショナル データベースには存在しないが、いくつかの組織的特性を持つデータを対象とするため、非構造化データよりも分析が容易になります。
7. クエリベースのデータ抽出
この方法では、クエリを使用してデータベースからデータを取得します。 これは構造化データ抽出の非常に効率的な形式であり、リアルタイムまたはスケジュールされた情報取得を提供できます。
データ抽出技術
- 自動データキャプチャ:ドキュメントまたは Web ページから関連情報を自動的に検出して抽出するツール。
- Web スクレイピング:ソフトウェアを使用して人間による Web 探索をシミュレートし、特定のデータを収集します。
- テキスト分析:自然言語処理を採用して、非構造化テキストから情報を抽出します。
- ETL プロセス: Extract、Transform、Load の略で、さまざまなソースからデータを取得し、有用な形式に変換して、データ ウェアハウスに保存する統合システムです。
効果的なデータ抽出のためのベスト プラクティス
- 明確な目標を定義する:データ抽出の取り組みから何が必要かを把握し、適切なツールと方法を選択します。
- データ品質の確保:整合性を維持するため、抽出プロセスの一環としてデータを検証してクリーニングします。
- コンプライアンスを維持する:データ抽出方法が合法であることを確認するために、データ プライバシー法と規制に注意してください。
- スケーラビリティ:将来のオーバーホールを避けるために、データのニーズに応じて拡張できるソリューションを選択してください。
データ抽出における課題
データ抽出は非常に貴重ではありますが、企業と個人の両方にとってプロセスを複雑にする可能性のある多くの課題を抱えています。 これらの課題は、データ主導型の取り組みの品質、速度、効率に影響を与える可能性があります。 以下では、データ抽出のプロセスで遭遇する一般的な障害のいくつかを詳しく説明します。

- データ品質の問題:
- 一貫性のないデータ: さまざまなソースからデータを抽出する場合、多くの場合、形式、構造、品質の不一致に対処する必要があり、不正確なデータセットにつながる可能性があります。
- 不完全なデータ: 抽出中に値が欠落していたり、レコードが不完全だったりすると、分析結果が歪む可能性があります。
- 重複: 抽出中に冗長なデータが発生する可能性があり、非効率性や偏った分析結果につながります。
- スケーラビリティに関する懸念:
- 量: データ量が増加するにつれて、システムのパフォーマンスを損なうことなく、タイムリーかつ効率的な方法で情報を抽出することがますます困難になります。
- データの進化: データが継続的に進化するには、大規模な再構成を必要とせずに変化に適応できるスケーラブルな抽出プロセスが必要です。
- 複雑で多様なデータソース:
- 多様性: さまざまな形式 (PDF、Web ページ、データベースなど) の幅広いソースからデータを抽出するには、多用途で洗練された抽出ツールが必要です。
- アクセシビリティ: レガシー システムまたは独自の形式でロックされたデータは、アクセスして抽出することが特に困難になる場合があります。
- 技術的な制限:
- 統合の難しさ: 抽出されたデータを既存のシステムに統合することは、特に異なるテクノロジーや古いインフラストラクチャを扱う場合に、技術的な課題を引き起こす可能性があります。
- 専門知識の欠如: 効率的なデータ抽出に必要なツールやテクニックに関しては、多くの場合、学習曲線が急勾配であり、専門知識が必要です。
- 法的およびコンプライアンスの問題:
- プライバシー規制: GDPR や HIPAA などの厳格なデータ プライバシー法を遵守すると、特定のデータでは追加の処理プロトコルが必要になる場合があるため、抽出プロセスが複雑になる可能性があります。
- 知的財産: 外部ソースからデータを抽出する場合、知的財産権を侵害するリスクがあり、法的な問題が複雑になる可能性があります。
- リアルタイムのデータ抽出:
- レイテンシー: 金融やセキュリティなど、レイテンシーが意思決定に大きな影響を与える可能性がある特定の分野では、リアルタイム データ抽出のニーズが高まっています。
- インフラストラクチャ: リアルタイムのデータ抽出には、ボトルネックなしで継続的なデータ フローを処理できる堅牢なインフラストラクチャが必要です。
- データ変換:
- 形式変換: 抽出されたデータは、分析のために別の形式に変換する必要があることがよくありますが、これは複雑でエラーが発生しやすいプロセスになる可能性があります。
- コンテキストの維持: 抽出と変換後にデータがその意味を保持していることを確認することは重要ですが、特に非構造化データを扱う場合には困難です。
- セキュリティ上の懸念:
- データ侵害: 機密情報や機密情報を抽出する際には常にデータ侵害のリスクがあり、厳格なセキュリティ対策が必要です。
- データの破損: ソフトウェア エラー、互換性の問題、またはハードウェアの障害により、抽出中にデータが破損する可能性があります。
結論
データ分析プロセスの生命線であるデータ抽出は困難に思えるかもしれませんが、適切なアプローチをとれば、洞察とチャンスを生み出すきっかけとなります。 その原則を理解し、現在のテクノロジーを活用することで、どの組織でもデータの可能性を最大限に引き出すことができます。