
機械学習におけるデータラベリングとは何ですか?どのように機能しますか?
公開: 2022-04-29データは、今日のビジネスにとって新しい富です。 人工知能などのテクノロジーが私たちの日々の活動のほとんどを徐々に引き継いでいるため、データの適切な使用は社会にプラスの影響を与えています。 データを効率的に分離してラベル付けすることにより、MLアルゴリズムは問題を発見し、実用的で関連性のあるソリューションを提供できます。
データラベリングの助けを借りて、私たちはマシンにさまざまな技術を教え、それらが「スマート」に動作するようにさまざまな形式で情報を入力します。 データラベリングの背後にある科学には、同じ情報の複数のバリエーションでデータセットに注釈を付けたり、ラベルを付けたりするという形で、多くの宿題が含まれます。 最終的な結果は私たちの日常生活を驚かせ、楽にしますが、その背後にある労力は計り知れず、称賛に値します。
データラベリングとは何ですか?
機械学習では、入力データの品質とタイプによって出力の品質とタイプが決まります。 マシンのトレーニングに使用されるデータの品質により、AIモデルの精度が向上します。
言い換えると、データのラベル付けは、非構造化データセットまたは構造化データセットにラベルを付けたり注釈を付けたりすることで、それらのデータセット間の相違点と類似点を見つけるようにマシンをトレーニングするプロセスです。
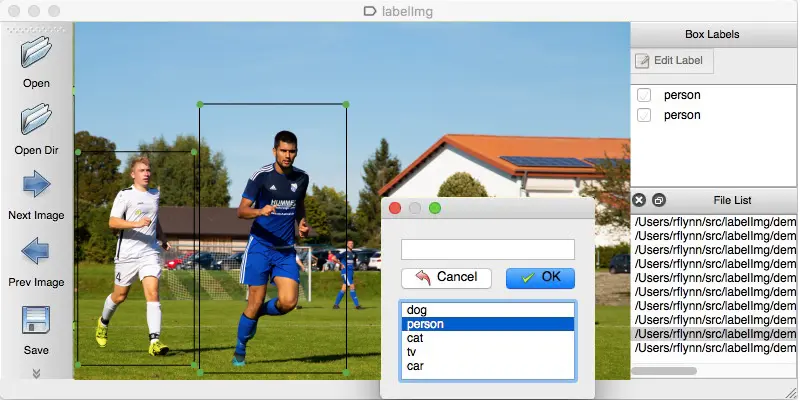
例を挙げてこれを理解しましょう。 赤色光が停止の兆候であることを機械に訓練するには、機械が信号を理解できるように、さまざまな写真のすべての赤色光にタグを付ける必要があります。 これに基づいて、AIは、与えられたすべてのシナリオで停止信号として赤信号を読み取るアルゴリズムを作成します。 もう1つの例は、音楽のジャンルを、ジャズ、ポップ、ロック、クラシックなどのラベルの下にある複数のデータセットで分離できることです。
データラベリングの課題
テクノロジーまたは構造の新しい変更/進歩は、その利点と課題をもたらします。 データのラベリングでも違いはありません。 データのラベル付けにより、ビジネスの拡大にかかる時間を大幅に短縮できますが、コストがかかります。 データラベリングがもたらすいくつかの課題について詳しく見ていきましょう。
時間と労力の観点からのコスト
ニッチ固有のデータを大量に取得すること自体が困難な作業です。 各アイテムに手動でタグを追加すると、すでに時間のかかるタスクが追加されるだけです。 プロジェクトが社内で処理される場合、プロジェクト時間のほとんどは、データの収集、準備、ラベル付けなどのデータ関連のタスクに費やされます。
これらのタスクを効果的に管理し、最初から正しく作業できるようにするには、この特定の専門知識を持つ専門家のラベラーが必要になります。 これは費用のかかる作業でもあり、時間だけでなくお金の面でも費用がかかります。
矛盾
専門知識が異なるアノテーターは、異なるラベル付け基準を持っている場合があります。 したがって、タグ付けに一貫性がない可能性が高くなります。 そうは言っても、複数の人が同じデータセットにラベルを付けると、データの正解率ははるかに高くなります。
ドメインの専門知識
特定の業界では、特定のドメインの専門知識を持つラベラーを雇う必要性を感じるでしょう。 たとえば、ヘルスケア業界向けのMLアプリを構築する場合、関連するドメインの専門知識を持たないアノテーターは、要素に正しくタグを付けることが非常に難しいことに気付くでしょう。
欠陥
人間が繰り返し行う作業は、エラーが発生しやすくなります。 人間のラベラーが持つ専門知識のレベルが何であれ、手動のタグ付けには常に不完全な範囲があります。 アノテーターはラベル付けのために大量の生データを処理する必要があるため、エラーをゼロにすることはほぼ不可能です。
データラベリングへのアプローチ
前述のように、データのラベル付けは時間のかかる作業であり、詳細に目を向ける必要があります。 問題の説明、タグ付けされるデータの量、データの複雑さ、およびスタイルに基づいて、データに注釈を付けるために適用される戦略は異なります。
財源と利用可能な時間に基づいて、会社が選択できるさまざまなアプローチを確認しましょう。
社内データラベリング
業界の種類、特定のAIプロジェクトを完了するための手元の時間、および必要なリソースの可用性に基づいて、データラベルプロセスを組織が社内で実行できます。
長所:
- 高精度
- 高品質
- 簡素化された追跡
短所:
- 時間のかかる/遅い
- 広範なリソースが必要
クラウドソーシング
フリーランサーによってラベル付けされたソーシングデータセットは、さまざまなクラウドソーシングプラットフォームで利用できます。 この方法は、写真などの一般化されたデータに注釈を付けるために使用できます。
クラウドソーシングによるデータラベリングの最も有名な例はRecaptchaです。 ユーザーは、特定の種類の画像を特定して、それらが人間であることを証明するよう求められます。 これらは、他のユーザーからの入力に基づいて検証されます。 これは、画像の配列のラベルのデータベースとして機能します。
長所:
- 早くて簡単
- 費用対効果の高い
短所:
- ドメインの専門知識を必要とするデータには使用できません
- 品質は保証されません
アウトソーシング
アウトソーシングは、社内のデータラベリングとクラウドソーシングの中間として機能します。 サードパーティの組織またはドメインの専門知識を持つ個人を雇うことは、長期および短期のすべてのプロジェクトで組織を支援することができます。
長所:
- 高レベルの一時的なプロジェクトに最適
- サードパーティのアウトソーシング会社が精査されたスタッフを提供します
- ビジネスニーズに応じて、構築済みとカスタムの両方のデータラベリングツールを提供します
- ニッチ固有のデータラベリングの専門家のオプションを取得できます
短所:
- サードパーティの管理には時間がかかる場合があります
マシンベース
業界で広く使用され、受け入れられているデータのラベル付けと注釈の最新の形式の1つは、マシンベースの注釈です。 データラベリングソフトウェアを使用してデータラベリングプロセスを自動化することで、人間の介入を減らし、ラベリングを実行できる速度を向上させます。 アクティブラーニングと呼ばれる手法を使用すると、データにタグを付けることができ、それに基づいてタグをトレーニングデータセットに自動的に追加できます。
長所:
- より迅速なデータ処理とラベリング
- 人間の介入が少ない
短所:
- 品質は優れていますが、人間のタグ付けと同等ではありません
- エラーが発生した場合でも、人間の介入が必要です

データのラベル付けはどのように機能しますか?
ビジネスニーズに基づいて、要件に最適なアプローチを選択できます。 ただし、データのラベル付けプロセスは、時系列で次の順序で機能します。
データ収集
機械学習プロジェクトの基盤はデータです。 さまざまな形式で適切な量の生データを収集することは、データのラベル付けの最初のステップです。 データの収集には2つの形式があります。1つは社内で収集したもので、もう1つは公開されている外部ソースから収集したものです。
生の形式であるため、このデータはデータセットのラベルを作成する前にクリーニングと処理が必要です。 このクリーンアップされ前処理されたデータは、トレーニングのためにモデルに送られます。 データが大きく多様化するほど、結果はより正確になります。

データ注釈
データがクリーンアップされると、ドメインエキスパートがデータを調べ、さまざまなデータラベル付けアプローチに従ってラベルを追加します。 意味のあるコンテキストは、グラウンドトゥルースとして使用できるモデルに付加されます。これらは、モデルに予測させたい画像などのターゲット変数です。
品質保証
MLモデルのトレーニングが成功するかどうかは、信頼性が高く、正確で、一貫性のあるデータの品質に大きく依存します。 これらの正確で正確なデータラベルを保証するには、定期的なQAチェックを実施する必要があります。 コンセンサスやクロンバックのアルファテストなどのQAアルゴリズムを使用すると、これらの注釈の精度を判断できます。 定期的なQAチェックは、結果の精度に大きく貢献します。
モデルのトレーニングとテスト
上記のすべての手順を実行することは、データの精度がテストされている場合にのみ意味があります。 非構造化データセットを入力して、期待される結果が得られるかどうかを確認すると、プロセスがテストされます。
データラベリングの業界ごとのユースケース
データラベリングとは何か、そしてそれがどのように機能するかを理解したところで、最も顕著なユースケースを確認しましょう。
コンピュータービジョン(CV)
これはAIのサブセットであり、ビジュアルとビデオ(タグ付けのために抽出された静止画像)の形式で提供される入力から、マシンが意味のある解釈を導き出すことを可能にします。
コンピュータービジョンアノテーションは、AIの実用的なメリットを実装するために、さまざまな業界で使用できます。
- 自動車業界では、道路、建物、歩行者、その他のオブジェクトをセグメント化するために画像や動画にラベルを付けることで、自動運転車がこれらのエンティティを区別し、実際の接触を回避するのに役立ちます。
- ヘルスケア業界では、病気の症状をX線、MRI、およびCTスキャンでセグメント化できます。 顕微鏡画像の助けを借りて、最も重大な病気を早期に診断することができます。
- QRコード、ラベルバーコードなどは、商品を追跡するための運輸およびロジスティクス業界のラベルとして使用できます。
自然言語処理(NLP)
これは、AIマシンが人間の言語と統計を解釈できるようにするサブセットです。 テキストと音声から意味を導き出し、アルゴリズムはさまざまな言語的側面を分析できます。
NLPは、多くのエンタープライズソリューションでますます使用されています。
- これは、電子メールアシスタント、オートコンプリート機能、スペルチェッカー、スパム電子メールと非スパム電子メールの分離など、すべての業界で一般的に使用されています。
- チャットボットの形式では、顧客が提起した基本的なクエリは、人間の介入なしにリアルタイムで解釈され、回答されます。 2023年までに、顧客とのやり取りの70%がチャットボットとモバイルメッセージングアプリケーションによって管理されると予測されています。
- 顧客の感情を捉えるためのテキストの負と正の極性を理解することは、eコマースのデータラベリングによって行われています。
Appinventivは、ユーザーがBluetoothウェアラブル用に最適化されたオーディオメッセージを送受信できるようにするVyrb用のソーシャルメディアアプリの構築に成功しました。

AIデータラベリング市場の概要
データラベリングは、 AIテクノロジーから生まれた繁栄している業界です。 データのラベル付けは、機械学習に提供される正確なデータに大きく依存しているため、今後数年で成長するはずです。
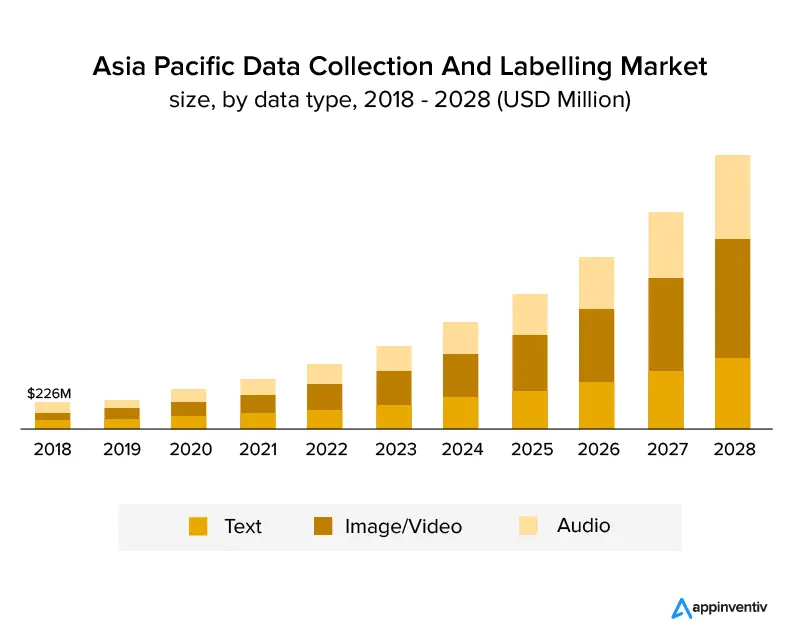
下のグラフは、業界が成長しており、今後数年間は成長し続けることを明確に示しています。 年平均成長率25.6%で成長し、2028年までに82.2億米ドルの市場規模に達すると予想されています。下のグラフは、データタイプ別の成長を示しています。
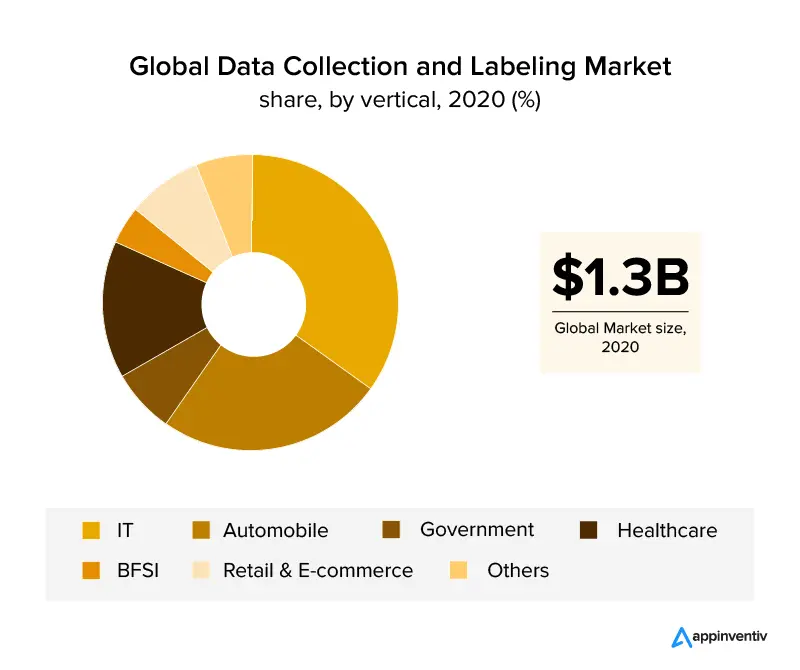
データラベリングを活用した業種の概要は、ITおよび自動車セクターであり、世界の収益の30%以上を占めています。 ヘルスケア業界の成長に伴い、このセクターでの効率的なAIベースのアプリケーションの正確なデータ要件により、データラベリングが急成長すると予想されます。 画像ラベリングの助けを借りて、小売および電子商取引業界もデータラベリング業界で大きな市場シェアを確保しています。
Appinventivによるデータのラベル付け
戦略的に、企業は強力な機械学習モデルを構築するためのデータ収集およびラベリングサービスをアウトソーシングしています。
Appinventivは、AIとMLの開発会社であり、組織がAI主導のソリューションで機会を開拓するのを長年にわたって支援してきました。 ビジネスの変革に10年近くの経験があり、さまざまな業界に多くの複雑なAIプロジェクトを成功裏に提供してきました。
たとえば、Appinventivは、ヨーロッパの大手銀行の銀行業務プロセスの自動化に成功しています。 自動化プロセスにより、銀行は精度を50%向上させ、ATMサービスレベルを92%向上させることができました。
AppinventivがYouCOMMが医療支援へのリアルタイムアクセスを提供することにより、院内の患者コミュニケーションを変革するための革新的なソリューションを構築するのを支援した別の例。 カスタマイズ可能な患者メッセージシステムを使用すると、患者は音声コマンドや頭のジェスチャーを使用して、スタッフにニーズを簡単に通知できます。
私たちの専門知識と顧客重視のチームにより、特定のニーズと要件に基づいた包括的なデータラベリングサービスを提供するという課題を克服するのに役立つデータラベリングサービスを提供します。
Appinventivは、タグ付けとデータ注釈に必要な膨大な数のツールを活用することで、データトレーニングプロセスを強化して複雑なモデルを簡素化できます。 これにより、セグメンテーション、分類、およびその後のデータラベル付けの精度の点で、迅速かつ簡単に優れたパフォーマンスを発揮できます。
まとめ!
「人工知能の力は非常に素晴らしいので、社会を非常に深く変えるでしょう。」 - ビルゲイツ
人工知能は、人間の生活を楽にし、社会に役立つ可能性を秘めています。 データラベリングの助けを借りて大量のデータを意味のある命令に分類するその機能は、業界が飛躍的に進歩し成長するのを助けました。
よくある質問
Q.データのラベル付けを完璧にするためのベストプラクティスは何ですか?
A.データのラベル付けに採用するアプローチに基づいて、従うことができるいくつかのベストプラクティスがあります。
- 収集されたデータが適切で、適切にクリーンアップされ、処理されていることを確認してください。
- 業界に基づいて、ドメインエキスパートデータラベラーのみにジョブを割り当てます。
- チームが従うべき注釈手法の基準を提供することにより、チームが統一されたアプローチに従うようにします。
- クロスラベル用に複数のアノテーターを割り当てることにより、メーカーチェッカープロセスに従います。
Q.データラベリングの利点は何ですか?
A.データのラベル付けは、データの正確な予測を行うためのコンテキスト、品質、および使いやすさをより明確にするのに役立ちます。 これは、モデル内の変数のデータの使いやすさを向上させるのに役立ちます。
Q.データラベリング会社を候補リストに載せる際に考慮すべきさまざまな要素は何ですか?
A.機械学習用のデータラベルサービスを選択する際に考慮すべき5つのパラメーターがあります。
- データラベリングプロセスのスケーラビリティ
- データラベリングサービスの費用
- データセキュリティ
- データラベリングプラットフォーム