
SEOのRobots.txtとは何ですか:それを作成して最適化する方法
公開: 2022-04-22今日のトピックは、トラフィックの現金化に直接関係していません。 ただし、robots.txtは、WebサイトのSEOに影響を与え、最終的には受信するトラフィックの量に影響を与える可能性があります。 多くのWeb管理者は、robots.txtエントリの失敗により、Webサイトのランキングを台無しにしてしまいました。 このガイドは、これらの落とし穴をすべて回避するのに役立ちます。 最後までお読みください!
- robots.txtファイルとは何ですか?
- robots.txtファイルはどのように見えますか?
- robots.txtファイルを見つける方法
- Robots.txtファイルはどのように機能しますか?
- Robots.txt構文
- サポートされているディレクティブ
- ユーザーエージェント*
- 許可する
- 禁止する
- サイトマップ
- サポートされていないディレクティブ
- クロール遅延
- Noindex
- Nofollow
- robots.txtファイルが必要ですか?
- robots.txtファイルを作成する
- Robots.txtファイル:SEOのベストプラクティス
- ディレクティブごとに新しい行を使用する
- ワイルドカードを使用して手順を簡略化する
- ドル記号「$」を使用して、URLの末尾を指定します
- 各ユーザーエージェントを1回だけ使用する
- 意図しないエラーを回避するために特定の手順を使用してください
- ハッシュを使用してrobots.txtファイルにコメントを入力します
- サブドメインごとに異なるrobots.txtファイルを使用する
- 良いコンテンツをブロックしないでください
- クロール遅延を使いすぎないでください
- 大文字と小文字の区別に注意してください
- その他のベストプラクティス:
- robots.txtを使用してコンテンツのインデックス作成を防止する
- robots.txtを使用してプライベートコンテンツを保護する
- robots.txtを使用して悪意のある重複コンテンツを非表示にする
- すべてのボットのオールアクセス
- すべてのボットにアクセスできません
- すべてのボットの1つのサブディレクトリをブロックする
- すべてのボットに対して1つのサブディレクトリをブロックします(1つのファイルが許可されています)
- すべてのボットに対して1つのファイルをブロックする
- すべてのボットに対して1つのファイルタイプ(PDF)をブロックする
- Googlebotのみのパラメータ化されたURLをすべてブロックする
- robots.txtファイルのエラーをテストする方法
- robots.txtによってブロックされた送信済みURL
- robots.txtによってブロックされました
- robots.txtによってブロックされていますが、インデックスに登録されています
- Robots.txtとメタロボットとxロボット
- 参考文献
- まとめ
robots.txtファイルとは何ですか?
robots.txt(ロボット除外プロトコル)は、検索エンジンロボットがすべてのWebページを、そのページのスキーママークアップまでクロールする方法を制御する一連のWeb標準です。 これは標準のテキストファイルであり、WebクローラーがWebサイト全体またはWebサイトの一部にアクセスするのを防ぐことさえできます。
SEOを調整し、技術的な問題を解決しながら、広告から受動的な収入を得ることができます。 あなたのウェブサイトの1行のコードは定期的な支払いを返します!
目次へ↑robots.txtファイルはどのように見えますか?
構文は単純です。ユーザーエージェントとディレクティブを指定してボットにルールを与えます。 このファイルの基本形式は次のとおりです。
サイトマップ:[サイトマップのURLの場所]
ユーザーエージェント:[ボット識別子]
[指令1]
[指令2]
[指令…]
ユーザーエージェント:[別のボット識別子]
[指令1]
[指令2]
[指令…]
robots.txtファイルを見つける方法
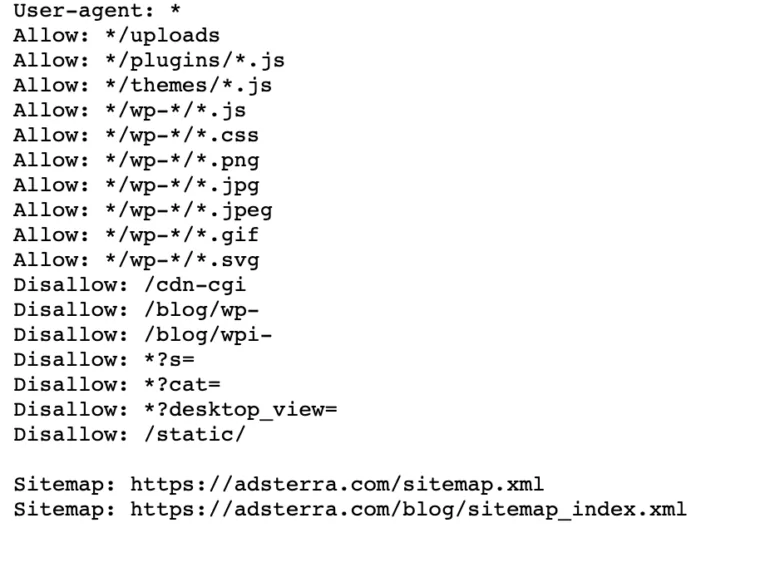
ウェブサイトにすでにrobot.txtファイルがある場合は、ブラウザで次のURLにアクセスして見つけることができます: https ://yourdomainname.com/robots.txt。 たとえば、これが私たちのファイルです
Robots.txtファイルはどのように機能しますか?
robots.txtファイルは、HTMLマークアップコード(したがって.txt拡張子)を含まないプレーンテキストファイルです。 このファイルは、Webサイト上の他のすべてのファイルと同様に、Webサーバーに保存されます。 このページはどのページにもリンクされていないため、ユーザーがこのページにアクセスする可能性はほとんどありませんが、ほとんどのWebクローラーボットは、Webサイト全体をクロールする前にこのページを検索します。
robots.txtファイルはボットに指示を与えることができますが、それらの指示を強制することはできません。 Webクローラーやニュースフィードボットなどの優れたボットは、ドメインページにアクセスする前に、ファイルをチェックして指示に従います。 ただし、悪意のあるボットはファイルを無視または処理して、禁止されているWebページを見つけます。
robots.txtファイルに競合するコマンドが含まれている状況では、ボットは最も具体的な一連の命令を使用します。
目次へ↑Robots.txt構文
robots.txtファイルは、「ディレクティブ」のいくつかのセクションで構成され、それぞれがユーザーエージェントで始まります。 ユーザーエージェントは、コードが通信するクロールボットを指定します。 すべての検索エンジンに一度に対応することも、個々の検索エンジンを管理することもできます。
ボットがWebサイトをクロールするときはいつでも、それを呼び出しているサイトの部分に作用します。
ユーザーエージェント: *
禁止:/
ユーザーエージェント:Googlebot
禁止:
ユーザーエージェント:Bingbot
禁止:/ not-for-bing /
サポートされているディレクティブ
ディレクティブは、宣言するユーザーエージェントに従わせるガイドラインです。 Googleは現在、次のディレクティブをサポートしています。
ユーザーエージェント*
プログラムがWebサーバー(ロボットまたは通常のWebブラウザー)に接続すると、そのIDに関する基本情報を含む「user-agent」と呼ばれるHTTPヘッダーが送信されます。 すべての検索エンジンにはユーザーエージェントがあります。 GoogleのロボットはGooglebot、YahooのロボットはSlurp、BingのロボットはBingBotとして知られています。 ユーザーエージェントは、特定のユーザーエージェントまたはすべてのユーザーエージェントに適用できる一連のディレクティブを開始します。
許可する
allowディレクティブは、制限されたディレクトリであっても、ページまたはサブディレクトリをクロールするように検索エンジンに指示します。 たとえば、検索エンジンが1つを除くすべてのブログの投稿にアクセスできないようにする場合、robots.txtファイルは次のようになります。
ユーザーエージェント: *
禁止:/ blog
許可:/ blog / allowed-post
ただし、検索エンジンは/ blog / allowed-postにアクセスできますが、以下にアクセスすることはできません。
/ blog / another-post
/ blog / yet-another-post
/blog/download-me.pd
禁止する
disallowディレクティブ(Webサイトのrobots.txtファイルに追加されます)は、特定のページをクロールしないように検索エンジンに指示します。 ほとんどの場合、これによりページが検索結果に表示されなくなります。
このディレクティブを使用して、一般の人から隠している特定のフォルダー内のファイルやページをクロールしないように検索エンジンに指示できます。 たとえば、まだ作業中ですが誤って公開されたコンテンツ。 すべての検索エンジンがブログにアクセスできないようにする場合、robots.txtファイルは次のようになります。
ユーザーエージェント: *
禁止:/ blog
これは、/blogディレクトリのすべてのサブディレクトリもクロールされないことを意味します。 これにより、Googleが/blogを含むURLにアクセスすることもブロックされます。
目次へ↑サイトマップ
サイトマップは、検索エンジンがクロールしてインデックスに登録するページのリストです。 サイトマップディレクティブを使用する場合、検索エンジンはXMLサイトマップの場所を認識します。 それぞれが訪問者にあなたのウェブサイトについての貴重な情報を提供することができるので、最良のオプションはそれらを検索エンジンのウェブマスターツールに提出することです。
ユーザーエージェントごとにサイトマップディレクティブを繰り返す必要はなく、1つの検索エージェントには適用されないことに注意することが重要です。 robots.txtファイルの最初または最後にサイトマップディレクティブを追加します。
ファイル内のサイトマップディレクティブの例:
サイトマップ:https://www.domain.com/sitemap.xml
ユーザーエージェント:Googlebot
禁止:/ blog /
許可:/ blog / post-title /
ユーザーエージェント:Bingbot
禁止:/ services /
目次へ↑サポートされていないディレクティブ
以下は、 Googleがサポートしなくなったディレクティブです。技術的に承認されていないものもあります。
クロール遅延
Yahoo、Bing、およびYandexは、Webサイトのインデックス作成に迅速に対応し、クロール遅延ディレクティブに対応します。これにより、Webサイトはしばらくの間チェックされ続けます。
次の行をブロックに適用します。
ユーザーエージェント:Bingbot
クロール遅延:10
これは、検索エンジンがWebサイトをクロールする前に10秒間、またはクロール後にWebサイトに再度アクセスする前に10秒間待機できることを意味します。これは同じことですが、使用するユーザーエージェントによってわずかに異なります。
Noindex
noindexメタタグは、検索エンジンがページの1つにインデックスを付けるのを防ぐための優れた方法です。 このタグを使用すると、ボットはWebページにアクセスできますが、ロボットにインデックスを付けないように通知することもできます。
- noindexタグ付きのHTTP応答ヘッダー。 このタグは、X-Robots-Tagを含むHTTP応答ヘッダーまたは<head>セクション内に配置された<meta>タグの2つの方法で実装できます。 <meta>タグは次のようになります。
<meta name =” robots” content =” noindex”>
- 404&410HTTPステータスコード。 404および410ステータスコードは、ページが使用できなくなったことを示します。 404/410ページをクロールして処理した後、Googleのインデックスから自動的に削除されます。 404および410エラーページのリスクを減らすために、Webサイトを定期的にクロールし、301リダイレクトを使用して、必要に応じて既存のページにトラフィックを誘導します。
Nofollow
Nofollowは、特定のパスの下にあるページやファイルのリンクをたどらないように検索エンジンに指示します。 2020年3月1日以降、Googleはnofollow属性をディレクティブと見なしなくなりました。 代わりに、正規のタグのように、ヒントになります。 ページ上のすべてのリンクに「nofollow」属性が必要な場合は、ロボットのメタタグ、x-robotsヘッダー、またはrel=「nofollow」リンク属性を使用します。

以前は、次のディレクティブを使用して、Googleがブログ上のすべてのリンクをたどらないようにすることができました。
ユーザーエージェント:Googlebot
Nofollow:/ blog /
robots.txtファイルが必要ですか?
多くのそれほど複雑でないウェブサイトはそれを必要としません。 Googleは通常robots.txtによってブロックされたウェブページのインデックスを作成しませんが、これらのページが検索結果に表示されないことを保証する方法はありません。 このファイルがあると、検索エンジンよりもWebサイトのコンテンツをより細かく制御およびセキュリティで保護できます。
ロボットファイルは、次のことも実行するのに役立ちます。
- 重複するコンテンツがクロールされないようにします。
- さまざまなWebサイトセクションのプライバシーを維持します。
- 内部検索結果のクロールを制限します。
- サーバーの過負荷を防ぎます。
- 「クロール予算」の無駄を防ぎます。
- 画像、動画、リソースファイルをGoogleの検索結果に含めないでください。
これらの対策は、最終的にSEOの戦術に影響を与えます。 たとえば、重複するコンテンツは検索エンジンを混乱させ、2つのページのどちらを最初にランク付けするかを選択するように強制します。 コンテンツの作成者に関係なく、Googleは上位の検索結果に元のページを選択しない場合があります。
Googleがユーザーを欺いたり、ランキングを操作したりすることを目的とした重複コンテンツを検出した場合、Googleはウェブサイトのインデックス作成とランキングを調整します。 その結果、サイトのランキングが低下するか、Googleのインデックスから完全に削除され、検索結果に表示されなくなる可能性があります。
さまざまなWebサイトのセクションのプライバシーを維持することで、Webサイトのセキュリティが向上し、ハッカーから保護されます。 長期的には、これらの対策により、Webサイトの安全性、信頼性、収益性が向上します。
あなたはトラフィックから利益を得たいウェブサイトの所有者ですか? Adsterraを使用すると、どのWebサイトからも受動的な収入を得ることができます。
目次へ↑robots.txtファイルを作成する
メモ帳などのテキストエディタが必要です。
- 新しいシートを作成し、空白のページを「robots.txt」として保存して、空白の.txtドキュメントにディレクティブの入力を開始します。
- cPanelにログインし、サイトのルートディレクトリに移動して、 public_htmlフォルダーを探します。
- ファイルをこのフォルダにドラッグしてから、ファイルの権限が正しく設定されているかどうかを再確認してください。
所有者としてファイルの書き込み、読み取り、編集を行うことができますが、第三者は許可されていません。 「0644」許可コードがファイルに表示されます。 そうでない場合は、ファイルを右クリックして「ファイルのアクセス許可」を選択します。
Robots.txtファイル:SEOのベストプラクティス
ディレクティブごとに新しい行を使用する
各ディレクティブを別々の行で宣言する必要があります。 そうしないと、検索エンジンが混乱します。
ユーザーエージェント: *
禁止:/ directory /
禁止:/ another-directory /
ワイルドカードを使用して手順を簡略化する
すべてのユーザーエージェントにワイルドカード(*)を使用し、ディレクティブを宣言するときにURLパターンを一致させることができます。 ワイルドカードは、均一なパターンを持つURLに適しています。 たとえば、URLに疑問符(?)が含まれるすべてのフィルターページがクロールされないようにすることができます。
ユーザーエージェント: *
禁止:/ *?
ドル記号「$」を使用して、URLの末尾を指定します
検索エンジンは、.pdfなどの拡張子で終わるURLにアクセスできません。 つまり、/ file.pdfにはアクセスできませんが、「。pdf」で終わらない/file.pdf?id=68937586にはアクセスできます。 たとえば、検索エンジンがWebサイト上のすべてのPDFファイルにアクセスできないようにする場合、robots.txtファイルは次のようになります。
ユーザーエージェント: *
禁止:/*.pdf$
各ユーザーエージェントを1回だけ使用する
Googleでは、同じユーザーエージェントを複数回使用するかどうかは関係ありません。 さまざまな宣言のすべてのルールを1つのディレクティブにコンパイルし、それに従います。 ただし、混乱が少ないため、各ユーザーエージェントを1回だけ宣言することは理にかなっています。
ディレクティブをきちんとシンプルに保つことで、重大なエラーのリスクを減らします。 たとえば、robots.txtファイルに次のユーザーエージェントとディレクティブが含まれているとします。
ユーザーエージェント:Googlebot
禁止:/ a /
ユーザーエージェント:Googlebot
禁止:/ b /
意図しないエラーを回避するために特定の手順を使用してください
ディレクティブを設定するときに、特定の指示を提供しないと、SEOに害を及ぼす可能性のあるエラーが発生する可能性があります。 多言語サイトがあり、/de/サブディレクトリのドイツ語バージョンで作業していると仮定します。
まだ準備ができていないので、検索エンジンがそれにアクセスできるようにしたくありません。 次のrobots.txtファイルは、検索エンジンがそのサブフォルダーとそのコンテンツのインデックスを作成できないようにします。
ユーザーエージェント: *
禁止:/ de
ただし、検索エンジンが/deで始まるページやファイルをクロールすることは制限されます。 この場合、末尾にスラッシュを追加するのが簡単な解決策です。
ユーザーエージェント: *
禁止:/ de /
目次へ↑ハッシュを使用してrobots.txtファイルにコメントを入力します
コメントは、開発者、場合によってはrobots.txtファイルを理解するのに役立ちます。 コメントを含めるには、ハッシュ(#)で行を開始します。 クローラーは、ハッシュで始まる行を無視します。
#これは、Bingボットにサイトをクロールしないように指示します。
ユーザーエージェント:Bingbot
禁止:/
サブドメインごとに異なるrobots.txtファイルを使用する
Robots.txtは、そのホストドメインでのクロールにのみ影響します。 別のサブドメインでのクロールを制限するには、別のファイルが必要です。 たとえば、メインのウェブサイトをexample.comでホストし、ブログをblog.example.comでホストする場合、2つのrobots.txtファイルが必要になります。 1つはメインドメインのルートディレクトリに配置し、もう1つのファイルはブログのルートディレクトリに配置する必要があります。
良いコンテンツをブロックしないでください
SEOの結果への悪影響を避けるために、robots.txtファイルやnoindexタグを使用して、公開したい高品質のコンテンツをブロックしないでください。 noindexタグを徹底的にチェックし、ページのルールを禁止します。
クロール遅延を使いすぎないでください
クロールの遅延について説明しましたが、ボットがすべてのページをクロールするのを制限するため、頻繁に使用しないでください。 一部のWebサイトでは機能する場合がありますが、大規模なWebサイトを使用している場合は、ランキングとトラフィックを損なう可能性があります。
大文字と小文字の区別に注意してください
Robots.txtファイルでは大文字と小文字が区別されるため、ロボットファイルを正しい形式で作成する必要があります。 robotsファイルの名前は「robots.txt」で、すべて小文字にする必要があります。 そうでなければ、それは機能しません。
その他のベストプラクティス:
- Webサイトのコンテンツまたはセクションのクロールをブロックしないようにしてください。
- 機密データ(プライベートユーザー情報)をSERP結果から除外するためにrobots.txtを使用しないでください。 他のページがプライベートページに直接リンクしている場合は、データ暗号化やnoindexメタディレクティブなどの別の方法を使用してアクセスを制限します。
- 一部の検索エンジンには、複数のユーザーエージェントがあります。 たとえば、Googleはオーガニック検索にGooglebotを使用し、画像にGooglebot-Imageを使用しています。 同じ検索エンジンのほとんどのユーザーエージェントは同じルールに従うため、各検索エンジンの複数のクローラーにディレクティブを指定する必要はありません。
- 検索エンジンはrobots.txtの内容をキャッシュしますが、毎日更新します。 ファイルを変更してより速く更新したい場合は、ファイルのURLをGoogleに送信できます。
robots.txtを使用してコンテンツのインデックス作成を防止する
ページを無効にすることは、ボットがページを直接クロールするのを防ぐための最も効果的な方法です。 ただし、次の状況では機能しません。
- 別のソースにページへのリンクがある場合でも、ボットはページをクロールしてインデックスを作成します。
- 不正なボットは引き続きコンテンツをクロールしてインデックスに登録します。
robots.txtを使用してプライベートコンテンツを保護する
PDFやサンキューページなどの一部のプライベートコンテンツは、ボットをブロックした場合でもインデックスに登録できます。 ログインの背後にすべての排他的ページを配置することは、disallowディレクティブを強化するための最良の方法の1つです。 コンテンツは引き続き利用できますが、訪問者はコンテンツにアクセスするための追加の手順を実行します。
robots.txtを使用して悪意のある重複コンテンツを非表示にする
重複するコンテンツは、同じ言語の他のコンテンツと同一または非常に類似しています。 Googleは、独自のコンテンツを含むページのインデックス作成と表示を試みます。 たとえば、サイトに各記事の「通常」バージョンと「プリンター」バージョンがあり、noindexタグがどちらもブロックしない場合、それらの1つがリストされます。
robots.txtファイルの例
以下は、robots.txtファイルのサンプルです。 これらは主にアイデアのためのものですが、いずれかがニーズに合っている場合は、それをコピーしてテキストドキュメントに貼り付け、「robots.txt」として保存して、適切なディレクトリにアップロードします。
すべてのボットのオールアクセス
空のrobots.txtファイルがあるかどうかなど、すべてのファイルにアクセスするように検索エンジンに指示する方法はいくつかあります。
ユーザーエージェント: *
禁止:
すべてのボットにアクセスできません
次のrobots.txtファイルは、サイト全体にアクセスしないようにすべての検索エンジンに指示します。
ユーザーエージェント: *
禁止:/
すべてのボットの1つのサブディレクトリをブロックする
ユーザーエージェント: *
禁止:/ folder /
すべてのボットに対して1つのサブディレクトリをブロックします(1つのファイルが許可されています)
ユーザーエージェント: *
禁止:/ folder /
許可:/folder/page.html
すべてのボットに対して1つのファイルをブロックする
ユーザーエージェント: *
禁止:/this-is-a-file.pdf
すべてのボットに対して1つのファイルタイプ(PDF)をブロックする
ユーザーエージェント: *
禁止:/*.pdf$
Googlebotのみのパラメータ化されたURLをすべてブロックする
ユーザーエージェント:Googlebot
禁止:/ *?
robots.txtファイルのエラーをテストする方法
Robots.txtの間違いは深刻な場合があるため、それらを監視することが重要です。 robot.txtに関連する問題については、検索コンソールの「カバレッジ」レポートを定期的に確認してください。 発生する可能性のあるエラーのいくつか、それらの意味、およびそれらを修正する方法を以下に示します。
robots.txtによってブロックされた送信済みURL
これは、robots.txtがサイトマップ内の少なくとも1つのURLをブロックしたことを示しています。 サイトマップが正しく、正規化されたページ、インデックス付けされていないページ、またはリダイレクトされたページが含まれていない場合、robots.txtは送信するページをブロックしないようにする必要があります。 そうである場合は、影響を受けるページを特定し、robots.txtファイルからブロックを削除します。
Googleのrobots.txtテスターを使用して、ブロックディレクティブを特定できます。 間違いは他のページやファイルに影響を与える可能性があるため、robots.txtファイルを編集するときは注意してください。
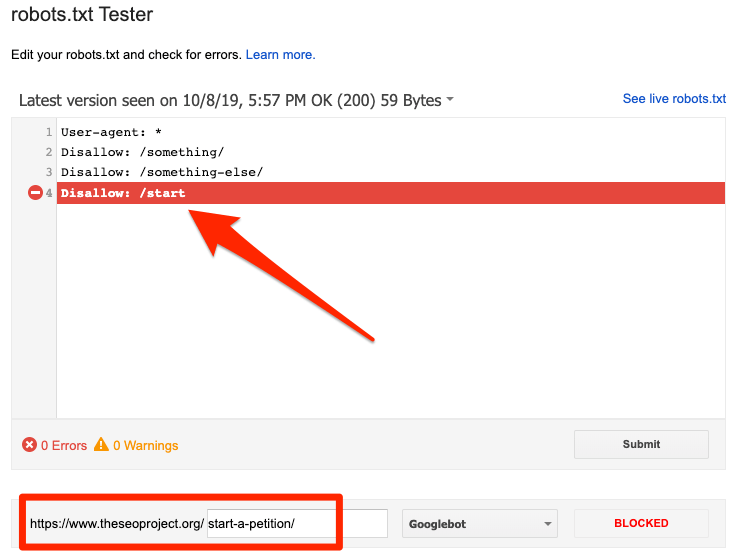
robots.txtによってブロックされました
このエラーは、robots.txtがGoogleがインデックスに登録できないコンテンツをブロックしたことを示しています。 このコンテンツが重要であり、インデックスを作成する必要がある場合は、robots.txtのクロールブロックを削除してください。 (また、コンテンツがインデックスに登録されていないことを確認してください。)
Googleのインデックスからコンテンツを除外する場合は、ロボットのメタタグまたはx-robots-headerを使用して、クロールブロックを削除します。 これが、コンテンツをGoogleのインデックスから除外する唯一の方法です。
robots.txtによってブロックされていますが、インデックスに登録されています
これは、Googleがrobots.txtによってブロックされたコンテンツの一部を引き続きインデックスに登録することを意味します。 Robots.txtは、コンテンツがGoogle検索結果に表示されないようにするためのソリューションではありません。
インデックス作成を防ぐには、クロールブロックを削除し、メタロボットタグまたはx-robots-tagHTTPヘッダーに置き換えます。 このコンテンツを誤ってブロックし、Googleにインデックスを作成させたい場合は、robots.txtのクロールブロックを削除してください。 これは、Google検索でのコンテンツの可視性を向上させるのに役立ちます。
Robots.txtとメタロボットとxロボット
これらの3つのロボットコマンドの違いは何ですか? Robots.txtは単純なテキストファイルですが、metaおよびx-robotsはメタディレクティブです。 それらの基本的な役割を超えて、3つは異なる機能を持っています。 Robots.txtは、ウェブサイトまたはディレクトリ全体のクロール動作を指定しますが、メタロボットとxロボットは、個々のページ(またはページ要素)のインデックス作成動作を定義します。
参考文献
役立つリソース
- ウィキペディア:ロボット排除プロトコル
- Robots.txtに関するGoogleのドキュメント
- Robots.txtのBing(およびYahoo)ドキュメント
- ディレクティブの説明
- Robots.txtのYandexドキュメント
まとめ
robot.txtファイルの重要性と、SEOの全体的な実践とウェブサイトの収益性に対するその貢献を十分に理解していただければ幸いです。 あなたがまだあなたのウェブサイトから収入を得るのに苦労しているならば、あなたはAdsterra広告で収入を得始めるためにコーディングする必要はありません。 HTML、WordPress、またはBloggerのWebサイトに広告コードを配置して、今日から利益を上げましょう。