
検索エンジンは Web サイトをクロールするためにどのようなテクノロジーを使用しますか?
公開: 2023-03-02
検索エンジンが Web サイトをクロールするためにどのようなテクノロジを使用しているか疑問に思ったことがある場合は、最終的にその質問の答えを得る準備をしてください。 Web クローラーとは何か、主要な検索エンジンで使用されるさまざまな種類の Web クローラー、および検索インデックス作成プロセスが何であるかについて説明します。 また、これらすべてが検索エンジンの結果にどのように影響するか、また、Web サイトの所有者が検索エンジンの Web クローラーに、希望に応じてコンテンツをインデックスするように指示する方法についても学びます。 ワールド ワイド ウェブで情報を探している人々に何十億もの関連する検索結果を正確に提供するために検索エンジンが使用するこのテクノロジーについて詳しく見てみましょう。
Web クローラーまたは検索エンジン ボットとは何ですか?
スパイダーとしても知られる Web クローラー ボットは、Google や Microsoft などの企業が、インターネット上で見つかるすべての Web サイトの、アクセス可能なすべての Web ページに何が存在するかを自社の検索エンジンに教えるために使用する自動プログラムです。 これらの検索エンジンは、ユーザーが特定のトピックについて知りたいと検索クエリを入力したときに、Web ページにどのような情報が含まれているかを学習することによってのみ、この情報を正確に取得できます。
Web クローラー ボットの種類
すべての検索エンジンには Web クローラーがあります。 ここでは、最も広く使用されているもののいくつかを紹介します。
Googleボット
Google は地球上で最も人気のある検索エンジンであり、2 つのバージョンの Web クローラーを使用して数千億の Web ページのインデックスを作成します。 GoogleBot デスクトップは、デスクトップ コンピュータを使用してインターネットを閲覧している人の動作を模倣したページを表示しますが、GoogleBot モバイルはスマートフォン ユーザーに対して同様の動作を行います。
GoogleBot は、これまでに作成された検索ボットの中で最も効果的なタイプの 1 つであり、Web ページを迅速にクロールしてインデックスを付けることができます。 ただし、非常に複雑な Web サイト構造をクロールするのに多少の問題があります。 さらに、GoogleBot が新しく公開された Web ページをクロールするのに数日から数週間かかることもよくあります。つまり、関連する結果にしばらく表示されなくなります。
ビングボット
Bingbot は、Microsoft が独自の検索エンジン Bing で Google に対抗するためのソリューションです。 これは Google の Web クローラーと同様に機能し、ボットがページをクロールする方法を示す取得ツールも含まれており、問題があるかどうかを確認できます。
スラープボット
Slurp Bot は Yahoo が使用する Web クローラーですが、Yahoo は検索エンジンの結果を提供するために Bingbot も使用しています。 Web ページのコンテンツを Yahoo モバイルの検索結果に表示したい場合、Web サイトの所有者は Slurp Bot へのアクセスを許可する必要があります。 さらに、Slurp ボットは Yahoo のパートナー サイトにアクセスして、Yahoo News、Yahoo Sports、Yahoo Finance Web サイトにコンテンツを追加することもできます。
アヒルアヒルボット
これは、DuckDuckGo で使用される Web クローラーです。DuckDuckGo は、多くの一般的な検索エンジンのようにユーザーのアクティビティを追跡しないことで、比類のないレベルのプライバシーをユーザーに提供することで知られています。 彼らは、DuckDuckBot だけでなく、Wikipedia やその他の検索エンジンなどのクラウドソーシング Web サイトから取得した検索結果を提供します。
Baiduspider と Yandex ボット
これらは、それぞれ中国の検索エンジン Baidu とロシアの Yandex で使用されているクローラー ボットです。 Baidu は中国本土の検索エンジン市場で 80% 以上のシェアを持っています。
Web クローリング、検索インデックス付け、検索エンジンのランキングの仕組み
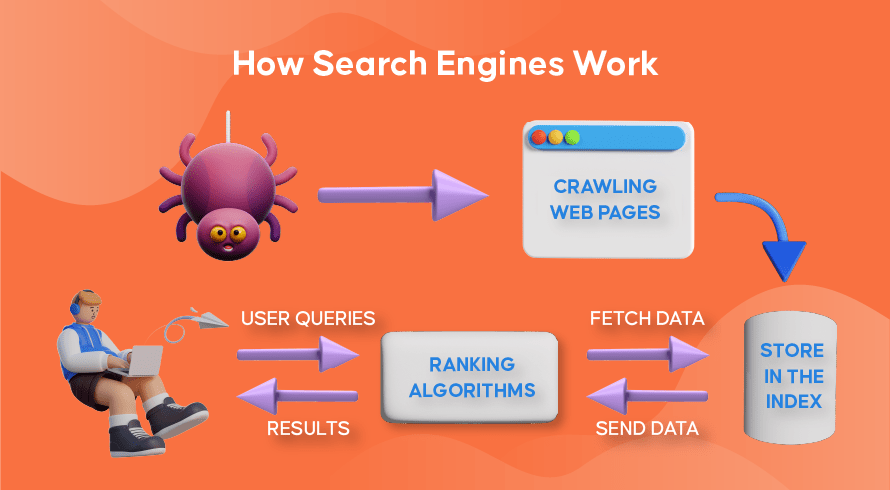
ここで、ほとんどの検索エンジンが Web クローラーを使用して、Web サイトに含まれる情報を検索、保存、整理、取得する方法を見てみましょう。
Web クローラーの仕組み
Web サイト上の新しいコンテンツと更新されたコンテンツの両方を見つけるプロセスは「Web クローリング」と呼ばれ、この機能を実行するソフトウェア プログラムの名前が付けられました。 ボットはまずいくつかの Web ページのクロールを開始し、そのコンテンツを見つけます。次に、その Web ページに含まれるハイパーリンクをたどって新しい URL を発見し、さらに多くのコンテンツにアクセスします。
検索エンジンのインデックス作成の仕組み
ボットが Web クローリングを通じて新しいコンテンツまたは更新されたコンテンツを発見すると、見つけたものはすべて「検索エンジン インデックス」と呼ばれる大規模なデータベースに追加されます。 これは図書館のようなもので、書籍が Web ページのように構成され、後で簡単に検索できるように整理されています。 各書籍には、Web ページに含まれる私たちが見ることができるほとんどのテキスト (「a」、「an」、「the」などの単語を除く) と、クローラーのみが見るメタデータが含まれています。 メタデータは、検索エンジンが Web ページのコンテンツを理解するために使用するものです。 メタタイトルおよびメタディスクリプションはメタデータの一例である。
検索ランキングの仕組み
ユーザーが検索クエリを入力すると、それぞれの検索エンジンがそのインデックスをチェックし、このリクエストに一致する最も関連性の高い情報を見つけ、関連するコンテンツを含む Web リンクのリストを整理し、これを検索エンジンでユーザーに表示します。結果ページ (SERP)。
このSERPの編成は「検索ランキング」と呼ばれ、メタデータ、Webサイトの信頼性(権威性)、キーワードやリンクなどを含む収集されたデータを考慮した検索アルゴリズムによって実行されます。 非常に信頼できる情報源であり、ユーザーにとって役立つ関連性の高いコンテンツが含まれている Web サイトは、上位にランクされ、SERP で上位の結果を獲得します。 そのため、すべての Web サイト所有者は、SERP で Web サイトをランク付けするための戦略を持っています。
検索エンジン最適化 (SEO) の概要
Web サイトの所有者は、検索エンジンがページのコンテンツをユーザーにとって関連性があり有用であると認識しやすくなるように、ページのコンテンツを最適化できます。 これにより、これらのページが SERP の上位にプッシュされ、より多くのオーガニック トラフィックが Web サイトに流入します。 ページコピーに関連キーワードを戦略的に含める、リンクを構築する、オリジナルの画像や動画を使用するなどは、SEO テクニックを活用する方法の一部です。
さらに、Web サイトは SEMrush などのさまざまなツールを使用して、リンク切れなどのページ上のさまざまな問題を見つけて修正することもでき、検索エンジンの目でのランキングをさらに向上させることができます。
検索エンジンにウェブサイトのクロール方法を伝える

場合によっては、Web クローラーがその機能を適切に実行しておらず、Web サイトの重要なページがインデックスから欠落していることがわかります。 これは、関連する検索クエリがコンテンツとともに表示されないことを意味し、潜在的な顧客がページにたどり着くことが困難になります。 幸いなことに、検索エンジンと通信する方法があり、何をインデックスに登録し、何を無視するかを少し制御できます。
Web サイトのルート ディレクトリに保存されている robots.txt ファイルは、どのページをクロールするか、どのページを無視するか、および Web サイトのアーキテクチャがどのように配置されているかを Web クローラーに指示します。 特定のページがテスト、または電子商取引で使用される特別なプロモーションや重複 URL に使用されている場合、そのページがインデックスに登録されないようにしたい場合があります。
たとえば、GoogleBot は、robots.txt ファイルが存在しない場合でも、Web サイトを完全にクロールし続けます。 robots.txt ファイルを検出すると、GoogleBot はクロール中に指示に従います。 ファイルの検出に問題がある場合、またはエラーが発生した場合、Web サイトがクロールされない可能性があります。 クロールに関する問題を回避するには、robots.txt ファイルを正しく使用し、Web サイトのアーキテクチャを整理し、オンページ SEO のベスト プラクティスを使用する必要があります。 Web サイト監査を実行して、Web サイトを悩ませている問題を分析および特定できます。

あなたのウェブサイトに SEO サービスが必要ですか?
Web クローラーと検索インデックスが Web サイトのランキングを向上させるためにどのように機能するかを理解しているサービス プロバイダーをお探しの場合、Inquivix は探していた SEO パートナーです。 当社は、コンテンツ作成からサイト アーキテクチャの最適化、Web サイトのパフォーマンス分析に至るまで、包括的なオンページ SEO サービスを提供し、Web サイトのエクスペリエンスの品質を継続的に向上させます。 詳細については、今すぐ Inquivix オンページ SEO サービスにアクセスしてください。
よくある質問
検索エンジンは、「スパイダー」または「ボット」とも呼ばれる「Web クローラー」と呼ばれるプログラムを使用して、Web サイトのページ上の新しいコンテンツと更新されたコンテンツの両方を検出します。 その後、ページに含まれるリンクをたどって、さらにページを検索します。 ページ上で見つかったコンテンツはインデックスに保存され、ユーザーがリクエストしたときに検索結果の情報を取得するために使用されます。
GoogleBot Desktop と GoogleBot Mobile は、ほとんどの国で最も人気のある Web クローラーであり、次に Bingbot、Slurp Bot、DuckDuckBot が続きます。 Baiduspider は主に中国で使用されており、Yandex Bot はロシアで使用されています。